|
|
 |
|
 |
| Preparing to shut down |
| Posted on Friday, April 29, 2022 at 05:15:29 PM | -doNka- |
|
| |
After a second life planet-rtcw is again going to shut down.
Hosting is expensive and maintenance is a bother. Old php stack and app are vulnerable to all kinds of sqli/email attacks that it's just not worth it.
Bots are rampant and hackers are plentiful. Internet is a bad place to host well, pretty much anything.
I will migrate a few features like client stats and server-on-demand to stats.rtcwpro.com, but for now I'm just putting this baby to sleep once again. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Closing 2 years of client stats! |
| Posted on Wednesday, January 19, 2022 at 07:15:30 AM | -doNka- |
|
| |
A pet project for learning python and pandas while processing RTCW stats started in 2018. Lots of doubt went into who and why and what value it will provide to a community of 17 people that have already stats processors, but there was a vision. It was modern data science techniques applied to RTCW with more detailed, rich, more insightful data extraction and analysis. The next level was taking two games together and aggregating the results.
5000 executions later, one can say the adoption went well. 1.3G client stats submitted, 24 seasons aggregated in NA, ELOs, fun stats of every kind.
For the record, here are December 2021 stats:
https://stats.donkanator.com/endseason/stats-2021Dec.html
Now onto the exciting part - summary for the last 2! years! I have aggregated every single recorded game and made the final dataset of 105,000 matches public, forever.
Here are some insights I have put together:
https://stats.donkanator.com/endseason/RTCW+Yearly+Analysis.html
And if you are into that kind of thing - datasets, analytics, etc, you can run the provided Jupiter notebook here
https://stats.donkanator.com/endseason/RTCW+Yearly+Analysis.ipynb
The next frontier is https://stats.rtcwpro.com/ where stats are automatically submitted by all participating RTCWPro servers to the central repository. The automation makes this whole process a lot more fun, robust(after all bugs are out) and open to new possibilities. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (1)
.:Back to Top:. |
|
|
|
| Catching up on 2021 stats |
| Posted on Saturday, December 11, 2021 at 09:40:49 PM | -doNka- |
|
| |
Most of my time is going to RTCW Pro stats - https://stats.rtcwpro.com/leaders
It's an exciting data flow where all RTCWPro servers around the world submit stats automatically to a central processing location. Match records are stored, processed, and made available within seconds. This is the next frontier of RTCW stats and it needs more priority/time than older client files.
To keep the promise, here are the stats for 2021 August-November. I will promptly close December when the month is over and will probably not have any more client-based seasons. There are no plans to take down (maybe refactor to a cheaper solution) old stats upload functionality at this time.
Enjoy:
August 2021
September 2021
October 2021
November 2021 |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Community project for RTCWPro awards |
| Posted on Tuesday, November 16, 2021 at 09:58:39 PM | -doNka- |
|
| |
World RTCW players, I'd like to invite you to contribute to the current RTCWPro stats project https://stats.rtcwpro.com/
I need help right now with your ingenuity and coding to process game events and produce award insights.
Task: provided a python array of RTCWPro events (kills, etc) you need to produce a match award like "Top Killer" or "Backstabber"
How to get started?
1. Copy everything in this folder to your PC and run just to test.
-- https://github.com/donkz/rtcwprostats/tree/master/test/gamelog_process
2. Dig into the code and comments to see what is the test setup and actual code
3. Write your own class and plug it in where comments are!
-- Be nice and do some good tests and encapsulate your code safely into try/catch clauses.
4. Pass the code back to me and i will work to bring it into common repository.
Comments are welcome!
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| RTCW Servers OnDemand |
| Posted on Sunday, July 18, 2021 at 07:31:57 AM | -doNka- |
|
| |
I'm rolling out a new RTCW server hosting solution!
Anyone can request an RTCW Pro server on demand by a click of a button. All you have to do is to head over to Server OnDemand link and request one in a region next to you.
It takes about 2 minutes for the server to provision and depending on a region, the address always will be:
na.donkanator.com (Virginia)
sa.donkanator.com (Sao Paolo)
eu.donkanator.com (London)
The template for the server is a container maintained by msh100 - https://github.com/msh100/rtcw
BTW , this guy deserves major recognition for the amount of work he put in. His RTCWPro container provides a amazingly flexible option for RTCW server hosting. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| RTCW 2021 Spring Fling Tournament - 6v6 - Completed. |
| Posted on Thursday, May 20, 2021 at 07:38:47 PM | -doNka- |
|
| |
Post by Raiser
Thanks to the cup admins Virus, Cypher, Gut, Eternal, Source, Spaztik, Cak and Raiser for planning and hosting an unbelievable exciting two day tournament. Thanks to all the cup participants ended up being 6 teams of 6; around 42 starters. Shoutout to the casters MakL, Ryan and Fonze for streaming as well as following the games; Well done. We look forward to seeing everyone again for the next cup; 2021 RTCW Pro Spring Fling is officially over.
Edit: Special thanks to RTCWPRO contributor team https://github.com/rtcwmp-com/rtcwPro/graphs/contributors
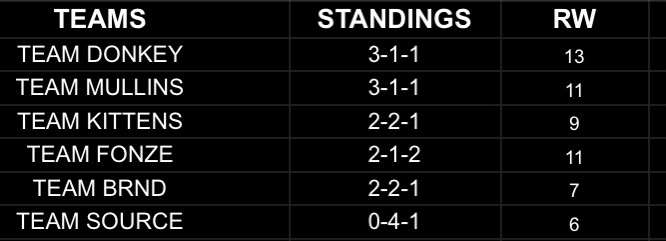
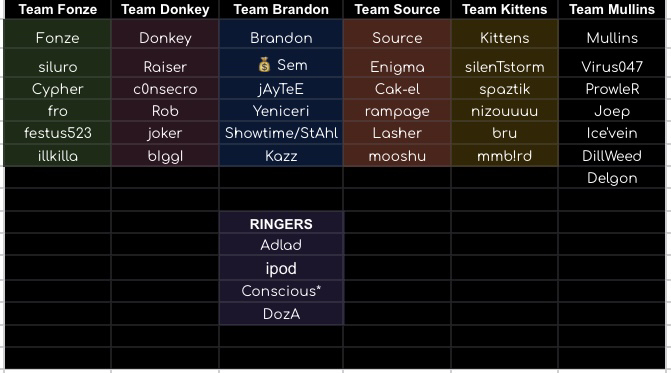
FINAL STANDINGS:
1st Place - Team Donkey - sDk - Still Don’t Know
2nd Place - Team Mullins - Redue - Redue Draft
3rd Place - Team Fonze/Team Kittens - ehhhh/8===D
5th Place - Team Brandon - T$T - The Money Team
6th Place - Team Source - [z] - Sleep
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| 2021 RTCWPro Spring Fling servers |
| Posted on Saturday, April 24, 2021 at 02:54:07 AM | -doNka- |
|
| |
These are the servers for the tournament, please first check with admins if there's any doubt.
t1.donkanator.com resolves to 54.173.77.70
t2.donkanator.com resolves to 34.201.58.197
/connect t1.donkanator.com;password cup2021
/connect t2.donkanator.com;password cup2021
Both servers have RTCW on default port 27960 and additional 27962
For those far far away from US/Virginia region - Europe, SA, Australia, try the following addresses to the same servers. They have enhanced networking enabled and could have lower ping and less jitter
eu.t1.donkanator.com
eu.t2.donkanator.com
https://www.youtube.com/watch?v=GAxrPQ3ycsQ&t=1s
For the good citizens that help retain stats
PLEASE SUBMIT STATS WHILE SELECTING REGION: NA and MATCH TYPE: Event/Tournament
?page=upload_stats
Reminder: to collect stats you need to set logfile 1, I have a windows shortcut like this for example:
"D:GamesReturn to Castle WolfensteinWolfMP.exe" +set fs_game rtcwpro +connect rtcwpro.donkanator.com +exec myfavoriteconfig.cfg +logfile 1
Additionally , you can use these URLs as server browsers
http://t1.donkanator.com/
http://t1.donkanator.com/27962/
http://t2.donkanator.com/
http://t2.donkanator.com/27962/ |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| November Season Closing |
| Posted on Monday, November 30, 2020 at 10:23:30 PM | -doNka- |
|
| |
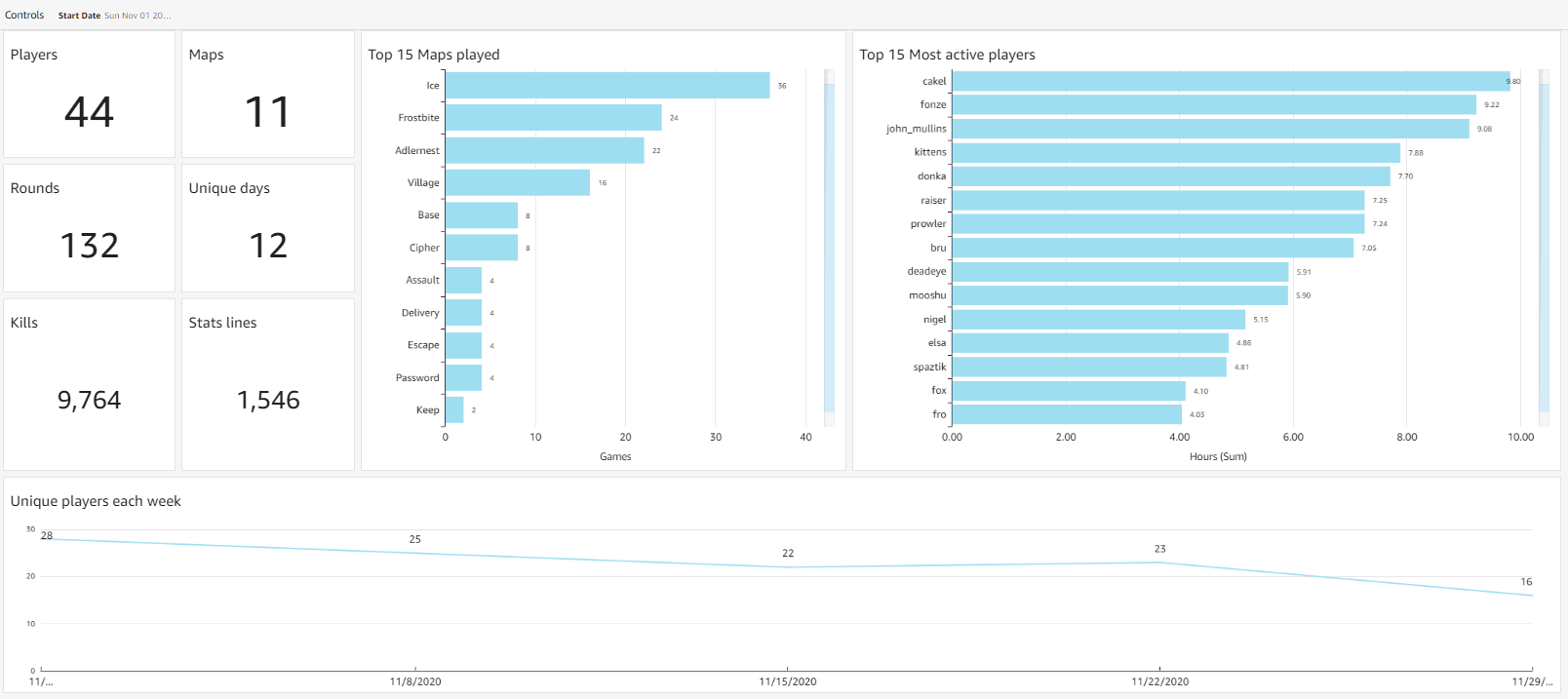
Another season came to an end and although this may look a little slimmer - much more exciting things are happening.
RTCW is getting a new mod - RTCWPro in place of OSP that served well for 18 years, but lost support almost as long ago. RTCWPro is still in very active development, but the NA scene is putting it to a good test. The stats processor was out of tune with the new client and vice versa, so quite a few stats simply went unrecorded or unreported. There's still plenty of activity to go around.
Here are the November 2020 stats. Congrats to people picking up some medals!
November results
November ELO
Health check!
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| August season closing |
| Posted on Wednesday, September 2, 2020 at 10:01:09 PM | -doNka- |
|
| |
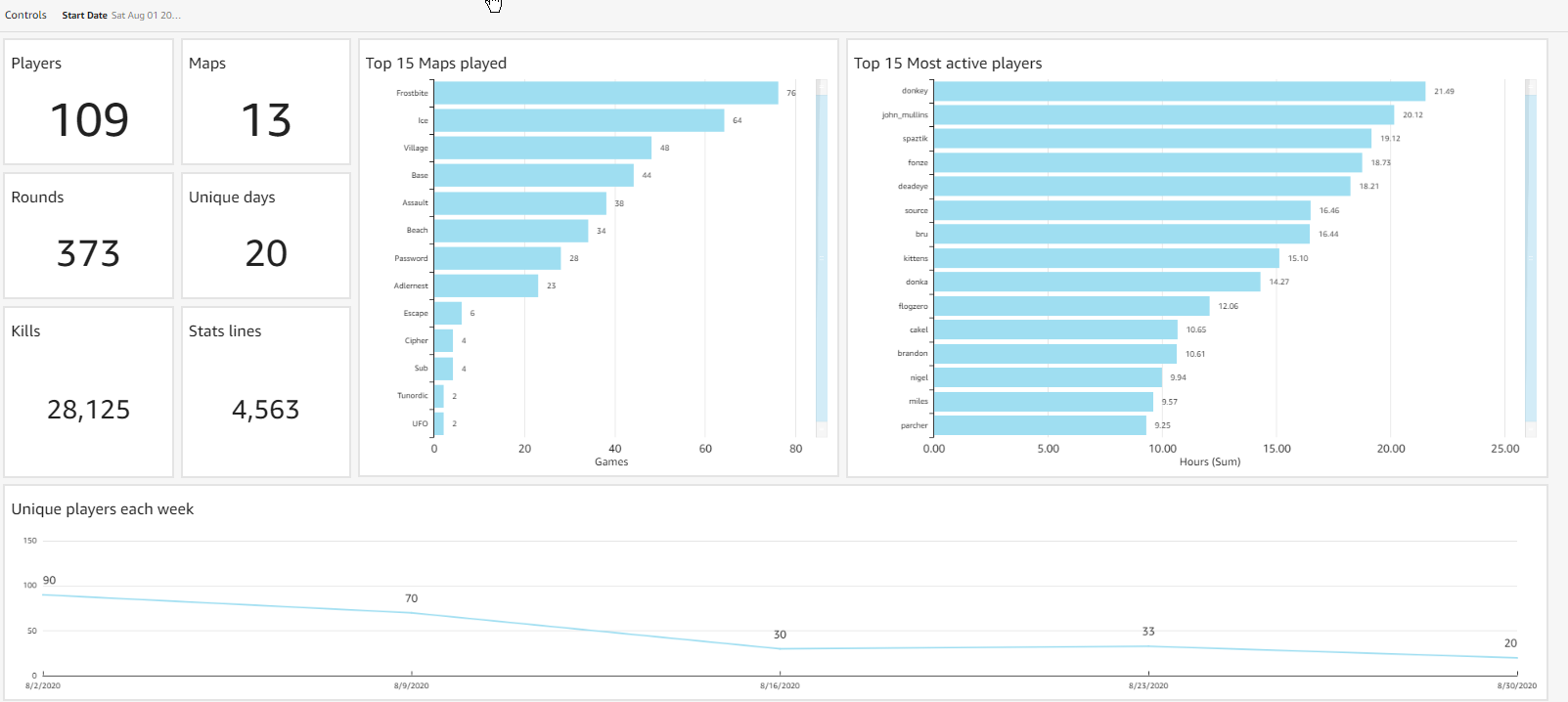
August was an interesting month - quakecon hype, most scrims since 2004, lots of PUGs and of course large numbers of new players in pubs on Thursdays/Sundays. Some players are taking time off after the QuakeCon burnout, but our numbers of regular players are stronger than ever!
These are the final stats for the season:
https://stats.donkanator.com/endseason/stats-2020Aug.html
Elo curves are coming soon!
Congratulations to the season winners!
1. Murkey
2. Source
3. Parcher
Health check - pay attention to the first week of August!
and panzer/sniper stats
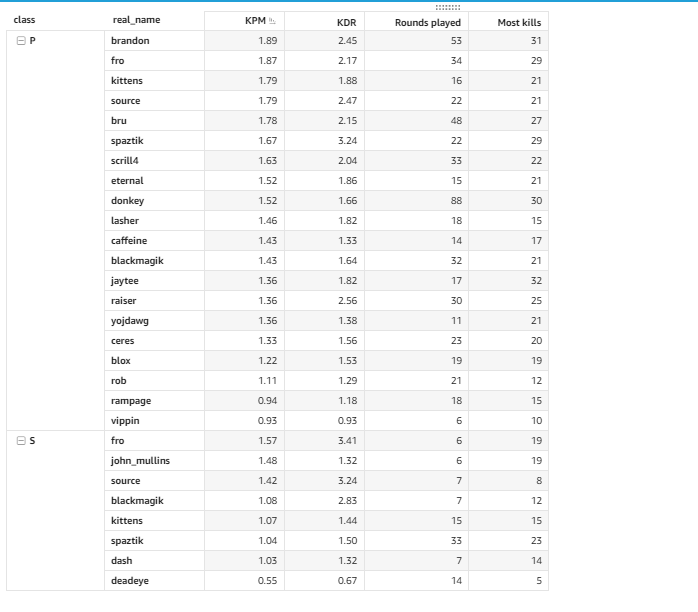
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Quakecon 2020 Final stats |
| Posted on Wednesday, August 12, 2020 at 09:59:52 PM | -doNka- |
|
| |
Congrats to all winners:
Invite + Playoffs
flagrant - (C)Warrior, Brandon,Source,Kittens,Bru,Nigel,DeadEye,Knifey
blatant - (C)Eternal,cKy,HotDamn (Elusive),Flogzero,Murkey,Candy,Donkey,Crono
3rd place decider is Thursday 9:30 EST 8/13/2020
https://s3.amazonaws.com/donkanator.com/stats/endseason/Quakecon2020-invite.html
Open winners - Get Stompled - (C)Conscious,Spaztik,Blackmagic,Dresserwood,Fonze,Pixi,Cak-el,Siluro
https://s3.amazonaws.com/donkanator.com/stats/endseason/Quakecon2020-open.html
Available casts:
https://www.youtube.com/playlist?list=PL9SMHmlI4wfCkMqaMufAoD0frk8wA8ez0 |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (1)
.:Back to Top:. |
|
|
|
| Raiser retirement #57 |
| Posted on Tuesday, July 14, 2020 at 02:20:45 PM | -doNka- |
|
| |
Raiser is close to beating Brett Favre with his retirement drama, but this one we are ready to take very seriously:
I just wanted to say guys I have enjoyed playing with everyone it was nice actually coming back and playing RTCW the past four years but after being banned from the NA discord a month ago for a ridiculous reason I thought that would be a long enough punishment in which the admins thought different deciding to double down and keep me and h2o banned. Thank you to the Euro community for welcoming and allowing me to play in the gathers while I didn’t have a job for those two months it was a very stressful time for me back then but being able get away from the real world and play with you guys so competitively it was alot of fun. It’s time for me to uninstall and walk away from this game. I don’t agree with holding these bans from both communities and I can guarantee you I am not the only one who’s thinking it. I had a couple of guys message me asking to join their team for qcon too but it looks like that’s not gonna be able to happen. Good luck to everyone I’ll miss both the NA and the Euro commmuity except for Caff, Nigel and Miles.
Shoutout to the NA original admin crew Virus, Gut, Cypher for organizing all the tournaments the last four years. Eternal - Hanging in there with everything that happened in the NA community always having my back trying to keep me in the community. I’m sorry I wasn’t able to control how I acted in these discord channels it’s a lot harder for me than you think.
Last but not least the Euro admins for everything they did to try and organize with the NA admins to make this qcon event happen it breaks my heart I will not be able to participate and this is why I need to move on.
Take care everyone.
Fr4gster, Sneaky, Raiser 2002-2006 - Raiser 2016-2020
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| QuakeCon 2020 at Home! |
| Posted on Friday, July 10, 2020 at 06:33:56 PM | -doNka- |
|
| |
AUGUST 7-9, 2020
THIS YEAR QUAKECON WILL TAKE PLACE IN THE CONVENIENCE OF YOUR OWN HOME.
Virus047: Yup yup!
[9:44 AM] Virus047: Qcon approached myself and gut about two months ago with discussions to begin planning this.
[9:44 AM] Virus047: Launched the news yesterday! :slight_smile:
[9:46 AM] Virus047: This definitely is legit and 100 percent supported by Quakecon and Bethesda.
https://www.rtcw.live/home |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Updated versions of Cipher and Nordic are now available! |
| Posted on Thursday, June 25, 2020 at 04:01:02 PM | -doNka- |
|
| |
(from source)
Here are some of the major changes:
Cipher (B2)
- added ladder clip to the sides of the river (and raised the water level) so people can get out easier
- resized and restructured the lower complex to make it more straight forward and scalable for 3v3
- removed explodable barrels for stability
- various textural and staging upgrades to improve visual clarity
https://s3.amazonaws.com/donkanator.com/rtcw_maps/te_cipher_b2.pk3
Nordic (B2)
- fixed bug that made it possible to hear sounds from distant areas
- fixed bug where destroyable grates remained after being broken with non-explosive weapons
- fixed bug that made fences solid/bulletproof
- added drop-down from lower axis spawn to emergency access tunnel / planning room
- added more initial spawn points at the north turret
- added outside entrance to office balcony ladder
- removed explodable barrels for stability
- restructured the office/warehouse area to make it more straight-forward
https://s3.amazonaws.com/donkanator.com/rtcw_maps/te_nordic_b2.pk3
For both maps, I also standardized the objective flags so that the primary objective (documents) is the at the top, and the forward spawn flag is the bottom. Sometimes the announcement that the objective taken doesn't get heard, and in that case this should make it easier for people to determine if the primary objective is in play.
Thanks to all those who provided useful feedback. Please download these maps before you join the pug as we will be playing them starting 6/25/2020 |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Corona Season 3 Results!! |
| Posted on Monday, June 1, 2020 at 03:51:13 AM | -doNka- |
|
| |
Corona season 3 is over!
We had another great month with 53 unique players and 30K pug kills. This month had seen increasing amount of smaller, more constant pickup games 3v3, 4v4 mid-week games that we agreed not to include in general PUG season.
Some improvements to stats:
-Best friends stats - see pairs of players that win together the most
-Weapon signatures - changed weapon kills to weapon percentages. Kills are pretty meaningless with people playing various amounts of time. Percentages, on the other side, can help you benchmark player styles against each other
-Other percentage base fields have better sorting.
Move onto the results:
https://s3.amazonaws.com/donkanator.com/stats/2020-05-31-May-Corona3.html
Thanks for all participants, active and casual, and congratulations to the winners!!! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Decka Remorial |
| Posted on Thursday, May 14, 2020 at 03:32:47 AM | -doNka- |
|
| |
eternal 05/11/2020
@everyone Decka passed away on Saturday evening. All the details are not yet known, but he was recently released from the hospital following surgery. While he hadn't participated in this community recently, Decka has been a regular character in these parts for the past two decades. He was a champion, and a great person behind his sometimes prickly exterior. I am at a loss for what to say, but he will be missed.
Our next pug night is Thursday 5/14/2020. Let's get some games going to remember a good player and a teammate.
Get on discord https://discord.gg/wJqBDsT
Get on RTCW/OSP: decka.donkanator.com
If you need to install RTCW, look for fully packed installation in the #reinstallation-and-files discord channel https://discord.com/channels/272106365307060225/419127457497612298
Run wolf as admin, generate and change new CD key (otherwise you will collide with others)
Join the server for a few minutes ahead of time to make sure your config and punkbuster work.
..we start around 9PM EST |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Corona Season 2 Results!! |
| Posted on Friday, May 1, 2020 at 05:45:00 AM | -doNka- |
|
| |
April brought even bigger numbers, more games, and new names than the previous record reason. We are dealing with splitting teams into 4 teams into different servers!
This month I enabled web upload for rtcwconsole.log files straight from the users and it’s been getting a lot of traction in the NA community as well as the EU. Please check out the “upload stats” link on the left navigation bar.
I have also coded a major overhaul to some metrics:
-New Tapout penalty for suiciding too much. It offsets high KDR for the panzers that vape a lot and /kill to boost KDR. It’s far from all malicious, but it’s a justified penalty to offset KDR.
-Megakills, Killstreaks, and Win% are awarded in ranges, instead of rankings. For example, anyone over 20 Killstreak gets the best rank, over 15 - second, etc.
-Panz penalty was reduced to 3 because Tapout is doing a good job to penalize all the vapes.
-Smoke kills penalty is 0-2 (one less).
-New ELO calculation that takes into account all players' games since January 1. It ranks by Kill performance less/more points for wins. Special weapons kills worth 50%.
-Add many countless bugs, styles, and time improvements!
Congratulations to season winners!!!
Anyone who plays on open nights and plays over 40 games is ranked.
Now head to the stats to see FINAL RESULTS
https://s3.amazonaws.com/donkanator.com/stats/stats-2020April.html
Individual night stats for the month:
(coming up)
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Follow first 2020 cup! |
| Posted on Monday, February 3, 2020 at 09:02:52 PM | -doNka- |
|
| |
Cliffdark organized an European weekly tournament that has a few North American Teams to follow!
https://www.crossfire.nu/news/9137/rtcw-6v6-2020-signups-closed
Deadeyes Huckleberry Service DHS:
Virus047 (c), Reker, Nigel, Brujah, Kittens, Tragic, Playa, Cypher, DeadEye, Fox, Jaytee
Trinity:
spaztik (c), festus, nihilist, wangofpain, lath, vodka, c@k-el, flogzero, anom, prowler
N/A
Eternal (c), cKy, End, Raiser, brandon, Sem, Donka, Machine, Booty, Donkey
Also parcher and murkey are on ROZ:
h2o (c), mini, raw, murkey, kylie, vis, parcher |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Update: RTCW2 and RTCW: The Movie |
| Posted on Thursday, December 13, 2007 at 07:18:51 PM | gisele |
|
| |
Just in case anyone missed the Quakecon 2007 update, I figured I'd relay what I've learned to everyone here!
New Wolfenstein Just Announced!
id Software�s CEO Todd Hollenshead announced on Friday, August 3rd, 2007 at QuakeCon that Threewave Software is working on the new Wolfenstein game for the following platforms: PS3, Xbox 360 and PC. Threewave Software is working in conjunction with Raven Software on the title. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (37)
.:Back to Top:. |
|
|
|
| Weekly OSP / TF2 Team Assembly |
| Posted on Monday, October 15, 2007 at 06:50:20 PM | BYE|ralphtehnader |
|
| |
Hope to see you all again on Wednesday around 8pm for some OSP gaming. The vent info is still the same.
After playing OSP for about an hour or so, let's play some TF2 for the remainder of the evening. I concur with the TF2 players on here that we should put together a team. I would be willing to host a server if there's enough interest to develop strats and pub on home turf on a 18 player server or so.
So far we have:
-Ralph
-Donka
-Juventus
-Ding
-w0rd (Papi Chulo)
-Bullz
-Paco's Gun
-BigshoT
-Snappas
-playa
-CaseyJones
-Spiza
-Tyson
-be4st
Anyone else interested?
If so:
http://www.totalgamingleague.com/team/Triad
join pw: vodka
Edit: As for the team name, some have suggested Team RtCW, which is cool. I was thinking of Team Wolfplayer or sticking with the classic BYE| = Bomb Your Enemies to go with the spam :D |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (84)
.:Back to Top:. |
|
|
|
| TF2 4 Newbs Tonight? |
| Posted on Tuesday, October 9, 2007 at 03:42:51 PM | BYE|ralphtehnader |
|
| |
Hey Folks,
It's been a while since I've been excited about a new game, and with Donka talking up TF2 and Orange Box arriving in the mail, I'd like to get some peeps on vent tonight to go over the fundamentals, and give it the old college try.
And if you don't have a copy of TF2 yet -- it's 5-games in one Box, for $45 bucks. Awesome deal.
http://www.ebgames.com/product.asp?product_id=646931
You can also order via Steam I'm told.
If you'd like, stop by at 8pm EST:
Vent Server: ventrilo4.va.powervs.com:5066
Password: bcdcrules
I'll make a TF2 channel, and maybe we can hop on ECGN afterwards for some comparing/contrasting.
Rock on,
Bill |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (51)
.:Back to Top:. |
|
|
|
| eXtinction 3v3 Tournament |
| Posted on Monday, October 1, 2007 at 04:53:04 AM | eX||hosey |
|
| |

eXtinction 3v3 Tournament!
This 3v3 double elimination RtCW 1.41 OSP tournament has been put together by a group of players that would like to see the OSP community get one last competitive run in this great game! It has been in the making for about one month now we thought it is about time we announce it to the public.
This tournament has been fully thought out and has everything almost ready for sign ups to be up.
Prizes
______
1st Place: Black Icemat Mousepad, Logitech G7 Laser Gaming Mouse, Logitech G15 Gaming Keyboard
2nd Place: Black Icemat Mousepad, Logitech Precision PC Gaming Headset
Sign ups and website containing Rules and everything you need to know will be posted shortly.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (53)
.:Back to Top:. |
|
|
|
| What's your dm_base of the future? |
| Posted on Sunday, September 9, 2007 at 08:11:23 PM | MUST B H4X |
|
| |
So... RTCW is bleeding out dead and there are some interesting games comming out rather soon (which means long before RTCW2 will ever come out). I would like to know what games the RTCW community (of the past and present) is planning to move on to or at the very least is looking forward to. Are there any former RTCW teams that are planning to head to another game and stay as a team? What are you guys looking forward to and why?
I know that personally I'm looking forward to Crysis because of the insane engine and the way that you customize the style of play. I'm also looking forward to Call of Duty 4 as far as competition goes, because it looks like (for the most part) it would be a good competition game. Haze is a game that looks like it may have a good single player. The game Severity that is being developed for the CPL for obvious competition reasons... as well as StarCraft II because of the replayability of a good RTS.
No need to say RTCW2.
(p.s. anyone know where invisi has gone? :p) |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (99)
.:Back to Top:. |
|
|
|
| RTCW OSP 3v3 Tournament |
| Posted on Thursday, August 23, 2007 at 02:23:51 AM | cr//st33la |
|
| |
Over the past few weeks myself and a few others have been working on throwing a RTCW OSP 3v3 Tournament. Before ordering servers, and posting the sign up page, we would like some feedback on the idea from the OSP community. So we know if it was a waste of time or if teams will sign up and participate. There is still a bit of work that needs to be done but if we get the feedback we hope we do sign ups will be available shortly.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (73)
.:Back to Top:. |
|
|
|
| Gang Kidnaps Top Gamer to Get His Password |
| Posted on Saturday, July 21, 2007 at 08:57:21 PM | -doNka- |
|
| |
An armed gang of four kidnapped one of the world's top RPG gamers after one criminal's girlfriend lured him into a fake date using Orkut, Google's social network. After sequestering him in Sao Paulo, they held a gun against the victim's head for five hours to get his password, which they wanted to sell for $8,000. And yes, the story gets even better.
Link to article |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (46)
.:Back to Top:. |
|
|
|
| RTCW2 exists? |
| Posted on Friday, July 20, 2007 at 08:16:59 PM | FuZioN)nG( |
|
| |
Small mentions of RTCW 2 in an article over @ IGN
"IGN: So what's going on with id right now?
Tim Willits: We have a lot of stuff going on right now. You're here to see Quake Wars [check out that preview here] so I won't go into that right now. We're working with Raven on Wolfenstein right now and we'll have a little more to talk about with that at QuakeCon. We're here talking to potential licensees about id Tech 5, which is the structure of our new title being developed internally."
Link: http://pc.ign.com/articles/804/804112p1.html
Someone going to Quakecon, please fill us in. And pictures too if we're that lucky ;)
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (29)
.:Back to Top:. |
|
|
|
| QuakeCon Registration |
| Posted on Tuesday, July 17, 2007 at 06:15:15 PM | -doNka- |
|
| |
To whom it may concern:
TOURNAMENT REGISTRATION WILL BEGIN AT QUAKECON.ORG ON
Wednesday July 18th @ 6:00 PM CDT
Games/Prizes:
Prize money for ET:QW 6v6:
1st: $22,000
2nd: $16,000
3rd: $8,000
4th: $4,000
Prize money for Quad-Damage(all versions of quake) 1v1:
1st: $20,000
2nd: $12,500
3rd: $7,500
4th: $5,000
5th/8th: $1,250 |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (23)
.:Back to Top:. |
|
|
|
| WTV Sunday 7/15/07! |
| Posted on Saturday, July 14, 2007 at 07:18:03 PM | FuZioN)nG( |
|
| |
Get your first peek at Team America!
Sunday we take on  #not.rtcw -- with recognizable former euro stars such as Creamy, Ogdoad, and Yilider from 4kings, Ramzi from GMPO, and Artan from ECGN 24/7 Beach ;p #not.rtcw -- with recognizable former euro stars such as Creamy, Ogdoad, and Yilider from 4kings, Ramzi from GMPO, and Artan from ECGN 24/7 Beach ;p
MAPS: TE_ESCAPE2; MP_VILLAGE (both maps abba on each)
WTV INFO: /connect 62.75.221.160:27990
TIME: 3eastern/2central/21:00euro
Expected  TEAM AMERICA Lineup: TEAM AMERICA Lineup:
elusive
FuZioN
Juventus
mutha``
newt``
snappas
Each map will be played on a seperate server. One map european and one map american. Come support us :)
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (33)
.:Back to Top:. |
|
|
|
| OSP Pub Night This Thursday. |
| Posted on Monday, July 2, 2007 at 03:32:11 PM | -doNka- |
|
| |
 It's time to stop beating around the bush and put your mouth where the balls are(Dodgeball). The ideas and requests are flying around to get the OSP night going on. We've seen a few suggestions for both, a pug or a pub night. Let us start with a pub night to see how many people we can gather on a given night. I'm sure with what we have right now we can easily fill up a 16-20 slots server and get some good old wolf OSP action going like the old times. It's time to stop beating around the bush and put your mouth where the balls are(Dodgeball). The ideas and requests are flying around to get the OSP night going on. We've seen a few suggestions for both, a pug or a pub night. Let us start with a pub night to see how many people we can gather on a given night. I'm sure with what we have right now we can easily fill up a 16-20 slots server and get some good old wolf OSP action going like the old times.
OSP Server IP: 66.254.117.183:27960 }-{eaven's Gate by The BirdZ 333 FPS!!!!! (CHI, needs rotation)
I'm sure most of the people would like to join some vent to chat, so we need a Vent info as well.
Vent Server IP: TBA
OSP pub night Thursday July 5th 9EST
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (109)
.:Back to Top:. |
|
|
|
| Article: RTCW Competition History |
| Posted on Friday, June 22, 2007 at 07:44:27 PM | -doNka- |
|
| |
Believe it or not, some people don't even know that article column exists, so there's a need for this post.
Karpov & Co spent quite a bit of time lining up the most detailed history record of RTCW competitions and major dramatic events that followed. Besides actual events you will find some scores, rosters, champs, and comentaries by those who could remember their lives behind the monitor 5+ years back. The whole thing came out to be pretty lenghty, but read it anyway, you will be entertained.
Artice: RTCW Competition History
Link with colors: DOWNLOAD NOW!
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (73)
.:Back to Top:. |
|
|
|
| So far has ET:QW met up to your expectations? |
| Posted on Thursday, June 21, 2007 at 05:31:11 PM | hollywood |
|
| |
Splash Damage opened up the Enemy Territory Quake Wars beta to the public yesterday. Currently only fileplanet subscribers (have to pay $) can only test out the beta. In the next couple of days it should be open up to non file planet subscribers (free) but you will not be guaranteed an etqw beta key. There will only be 60,000 slots. If you are not in the beta already, there is close to 1,000 people playing online on about 140 servers across the US, Australia and Europe.
Splash Damage had made it clear that this is a beta version and not a demo. Many people on various forums that have played many previous team based games are already calling it a failure.
http://www.hardforum.com/showthread.php?p=1031191446&posted=1#post1031191446
If you are in the ET:QW beta please post your feedback.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (60)
.:Back to Top:. |
|
|
|
| id Software |
| Posted on Wednesday, June 13, 2007 at 09:42:12 PM | [+ oo] rampage |
|
| |
Just a follow up from the already well known "secret" engine that id has been working on. It has finally been put to video and shown for the first time to the public. I couldn't get a better link other than a download link so if anyone can find one please post it.
http://www.gametrailers.com/downloadnew.php?id=20463&type=wmv

You could also go to www.gametrailers.com and view it there.
10:14AM - "So the last couple of years at iD we've been working in secrecy on next-gen tech and a game for it... this is the first time we're showing anything we've done on it publicly." iD Tech 5... "What we've got here is the entire world with unique textures, 20GB of textures covering this track. They can go in and look at the world and, say, change the color of the mountaintop, or carve their name into the rock. They can change as much as they want on surfaces with no impact on the game."
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (16)
.:Back to Top:. |
|
|
|
| RTCW Cup announced! |
| Posted on Sunday, June 3, 2007 at 06:53:10 PM | X-tra |
|
| |

Im proud to present You the Burner RTCW Cup powered by PowerMauerClanGermany.
Do you also wallow in old memories?
Showtime from PMCG got a great idea to bring back these old memories!
Let�s start a 6on6 RTCW Cup in hopes to see some nice matches in WTV and have some fun.
You can signup your team till 17.06.07 here: http://www.pmcgclan.de/rtcwcup/
I hope we'll receive a lot of sign-ups and it will be a great event!
This cup is covered by WTV and Shoutcast.
Cup Informations:
� Mode: 6on6
� RTCW Version : 1.41b
� Rtcw OSP Version: 0.9
Mappool:
mp_beach
mp_base
mp_ice
mp_village
mp_aussault
te_frostibte
Additionally the Community can vote for 2 more Maps - check the Cupsite.
I hope we will have another enjoyable event, the signups have been openend, good luck & have fun to everyone.
#burner-cup.rtcw @ Quakenet
RTCW Cup |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (79)
.:Back to Top:. |
|
|
|
| Ralph Would Love Your Help... |
| Posted on Friday, June 1, 2007 at 07:49:49 AM | BYE|ralphtehnader |
|
| |
It's been a while since The Hammer interviewed me on P-RtCW, but I wanted to give you all the heads up that I'm still making music with my band, and we recently were nominated for 7 awards in the Hartford Advocate Bandslam 2007! It would be very sexy (and cool) to have the support of the RtCW community to help bring home some wins this year! As a gift for your efforts, I've included a link to download our most recent album, Diving Dreamers entirely for free. It's available on iTunes, CDBaby and Awarestore, but for your support, we're happy to provide you it for free.
Please show your support for my guitar hax by placing your ballot vote for Bill Carleton Band in the following categories:
-Best Original Rock
-Best Pop Rock
-Bill and Lee - Happy Hour Duo
-Dan Prindle - Best Bassist
-Bryan Kelly - Best Drummer/Percussionist
-Lee Sylvestre - Best Guitarist
-Tony Parlapiano - Best Keyboardist
Thanks so much! And if anything, let me know what you think of the album (good or bad feedback)!
You can also check out our music on MySpace and at www.billcarleton.com
-Ralph
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (37)
.:Back to Top:. |
|
|
|
| id Software announces new game engine |
| Posted on Friday, June 1, 2007 at 07:49:30 AM | [+ oo] rampage |
|
| |
http://www.gametrailers.com/viewnews.php?id=4696
By Eugene Huang
With releases for PC, PS3, and Xbox 360 scheduled for the end of this calendar year, Enemy Territory: Quake Wars now seems to be comfortably on autopilot. With this joint project between id Software and Splash Damage soon to be complete, it now seems as if id has been freed to work on yet another engine to be used with another brand new franchise.
At a London event earlier this week, id CEO Todd Hollenshead was the first to reveal the news to GamesIndustry.biz.

"We are working on an all-new franchise," he stated. "It's not Doom, it's not Quake, it's not Wolfenstein, it's not Enemy Territory, it's not even Commander Keen! It is a new id brand with an all-new John Carmack engine, and I think that when we show it to people, once again they'll see, just like they saw when we first showed Doom 3, that John Carmack still has a lot of magic left."
Since creating Doom 3, Carmack has had his hands full porting games such as Doom RPG and Orcs & Elves to mobile platforms. But in comparison to those relatively minor projects, this newly announced game would be their first major independently-developed title in nearly three years.
Hollenshead also states, however, that Carmack is still feverishly working on the engine, which he hopes will be used "across a wide range of applications and different games within [id's] suite of franchises". As it is still in its early development stages, Hollenshead was not at liberty to discuss details, but promises to make a formal announcement when the time is right.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (17)
.:Back to Top:. |
|
|
|
| -[x]- End server party!!! |
| Posted on Tuesday, May 29, 2007 at 06:05:58 PM | -Tr0n- |
|
| |
Shrubapalooza (the last bastion from hackers and douche admins) Is going to be put to sleep in the morning of May, 30th, 2007.
This is an invite... from -[x]- to all of the people we've been playing with thru the years and new faces to come out and frag it up with us one last time.
Info
Time/Date : 8pm est/May 29, 2007
Place : Shrubapalooza (208.200.4.3:27960)
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (8)
.:Back to Top:. |
|
|
|
| Details On New Wolfenstein Development. |
| Posted on Saturday, May 12, 2007 at 10:15:08 PM | -doNka- |
|
| |
From Yahoo News:
The company is currently working on a new game based on the "Wolfenstein" series, and with newer motion-capture technology, it is working with a local actress to be the character in its movie.
...
The game won't come out until sometime in 2008, but the name and many other details about it are being kept secret, which is just one clue at how competitive this industry has become.
Full article
More about technology and C. Coon here
Thanks to Tosspot at ESReality for finding this. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (3)
.:Back to Top:. |
|
|
|
| Some Crazy Internets Sh*t about Planet-RTCW and Wippuh.... |
| Posted on Thursday, May 3, 2007 at 12:38:23 AM | -doNka- |
|
| |
I've been trying to follow some leads from Planet-RTCW logs and something totally ridiculous caught my attention. Some half-dead site is bashing Wippuh for I quote, "attempting to fraudulently obtain money from the Wolfenstein community".
To sum up the content:
The author talks about a news item posted by Wippuh a while ago in which he asks for charity donations. Then author claims that Wippuh is a con man and explains why he thinks so.
Read full thing here: http://www.dhutchison.co.uk/wippuh.htm
The rest of the site is pretty entertaining too. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (47)
.:Back to Top:. |
|
|
|
| BanksCon2007 |
| Posted on Friday, March 30, 2007 at 07:15:08 PM | .Banks |
|
| |
As alot of you know, last year, during BOB3, I had a lan/get together at my house. Several great friends and players showed up. Militant, Sage, Odin from arise, knight and I drank, and grilled, and lanned for two days straight. This year, during July, I wanna do the same thing again. Probably a long weekend type thing. For those of you that are interested, I live just north of Baltimore in Bel air(go to #banksbuddies on irc and pm me for more info). You can either p2p me, or call me on my cell anytime 443 910 0877. Name is Jason. Althought, most of you still call me Banks when you call me for some odd reason lol. This is nothing more, than just getting together, chillin, gettin a weeeeeee bit toasted, and talking bout things we all love. RTCW!!! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (72)
.:Back to Top:. |
|
|
|
| Searching For Site Content. |
| Posted on Thursday, March 8, 2007 at 07:08:45 PM | -doNka- |
|
| |
NA.RTCW is having that time of the year when the activity is not as great due to filler time between competition seasons. There's simply not much to write in the times like these, so I'd like to turn to our small, but strong community for support. This is a good time to step out of the generally inactive crowd with some creativity and enthusiasm. Is there an article you always wanted to write to bring up a discussion? Some old screenshots saved on your hard drive? Some other unthinkable project ideas that have been eating you forever? It's a good time to submit them now. Just use your judgement and make sure that your news/article/POW is somewhat Wolfenstein related.(Please don't try to sell laptops here like spiza).
Banks have submitted an article, that I hope will not go unnoticed:
http://planet-rtcw.com/?page=articles&id=264
If you have some project in mind, but you're not sure if your effort will not duplicate someone elses existing/upcoming work you can talk to me or make a comment about it in most discussed news item(not sure who uses forums around here).
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (35)
.:Back to Top:. |
|
|
|
| Team HighBot would like their Battle for Berlin prizes |
| Posted on Wednesday, February 28, 2007 at 03:50:51 AM | DynoSauR |
|
| |
I have been in contact with a concerned humM3L of Team HighBot for more than the past two months and it's finally come to the point that he wanted me to publicly ask when they could expect to receive their hard earned prizes? I know that he has directly asked Mortal and I have as well and haven't gotten any kind of definite answer. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (202)
.:Back to Top:. |
|
|
|
| Season Runnner Up - Warchild Under The Spotlight. |
| Posted on Saturday, February 24, 2007 at 09:32:21 PM | -doNka- |
|
| |
Looks like highlife/blur-warchild was busted with silo bot a day after the TWL OSP finals.
Here's a piece from Dyno:
I certainly didn't want to see this violation and was saddened when considering it's ramifications. I don't doubt that we will hear from warchild saying it was one of his other family members. I know we've heard this before and I would be inclined to believe warchild since his name has not been used with that GUID for a long time.
Read full post: http://www.wolfplayer.us/forums/viewtopic.php?t=269 |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (234)
.:Back to Top:. |
|
|
|
| Trinity is TWL OSP 13 Champion. |
| Posted on Thursday, February 22, 2007 at 05:56:09 AM | -doNka- |
|
| |
Trinity beat Highlife tonight in series of 4 games on Frostbite.
Round 1: Half round time set by trinity, Highlife beats it.
Round 2: Trinity holds 7:20 and caps
Round 3: Trinity Caps in 4:03, holds.
Round 4: Trinity full holds, caps.
Trinity: bigshot, cade, elusive, myth, robez, sucka
Highlife: Alien, ding, oot, ownage, silentstorm, tyson, warchild
I'd like to thank everyone who particapated in this season, especially TWL staff for keeping it together. Special mention to Gromit for quality announcements on planet-rtcw.
Stay tuned on next season announcement. I'd recommend EVERYONE who is interested to see naked wednesdays to last one more season to go and make your voice heard on TWL forums.
http://www.teamwarfare.com/forums/forumdisplay.asp?forumid=12 |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (91)
.:Back to Top:. |
|
|
|
| THURSDAY?!?!? |
| Posted on Sunday, February 11, 2007 at 08:05:58 PM | SyndicateGromit|TWL |
|
| |
I apologize for making a separate news article for this, but...
I REALLY NEED TO HEAR FROM RGR AND HL ABOUT WHETHER THEY CAN PLAY THIS THURSDAY (INSTEAD OF WEDNESDAY). I do NOT want to skip a week but I'm not going to force the teams to play on either Valentine's day (Wed) or on an alternative weekday (Thursday) without consent. As I've said in match comms and in private messages, I need to know TODAY whether RGR and HL are available (SS and TTT have said 'yes') or else I have no choice but to skip a week which sucks for everyone)
Email me at gromit@teamwarfare.com or post in match comms.
Thanks,
Gromit|TWL |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (21)
.:Back to Top:. |
|
|
|
| NiteSwine has made a statement. |
| Posted on Wednesday, February 7, 2007 at 07:53:14 PM | [a]streetz-work |
|
| |
Ive quoted this from teamwarfares forums.. NiteSwine wrote:
"I never said the door was closed on TWL sponsored leagues for RtCW. I did say we did not plan to continue, back-to-back or continuous leagues for RtCW. Options are available.
I will say I've taken some notice of various discussions and isolated activities within the community towards the development of options for continued RtCW competition. I'll admit I'm pleased by it. Maybe the real transition will be at the community level: with more activity and support emerging from the community, it may help justify future leagues and ladders hosted by TWL.
For a time, TWL will seek to encourage the community to put together options and explore new opportunities. I think this is a great opportunity for the community. If we (as a team or individuals) can help, ask us -- I'm sure you'll find us more than accomodating. I'll spend some time reviewing things as they develop, and as an admin team we'll decide when/if it's best to present another season here at TWL.
As for planet being the hub of all things RtCW, that's great. The place serves a purpose. Using it as a foundation for a venue intended for constructive discourse might be a challenge, though. Our forums are here, too. There's more expectation for contructive input here and less tolerance for ill behavior. If the community wishes to truly discuss it's options, our forums are available, too." |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (26)
.:Back to Top:. |
|
|
|
| Continuing RTCW Compeition... Continued |
| Posted on Saturday, February 3, 2007 at 05:11:45 AM | MUST B H4X |
|
| |
Well, after a few days of deliberation the old thread died quickly. I want to know if there is still enough support to continue RTCW Competition. There are currently 12 teams with a total of 152 players in the 13th season of TWL OSP (80%+ active). I also know that if this were to happen, I myself could probably get 5-10 old players to start playing again, as well as caffeine may join back up with the lack of TWL influence :D. I think if people are serious about this then we need to actually talk about it rather than sitting around thinking that it's just going to happen without any input from the community. That being said, if this were to happen, there are a few things needed to consider:
1. Admins. This is an obvious one, without someone managing the competition, there is no competition. I know that there are a lot of experienced players in this community that know the game, and people such as Mortal who set up the BFB tournament and would have a bit of knowledge in the field. As well as people such as Donka who (I assume) would be able to do a good job at maintaining a website. If you think you would make a good admin, post. Perhaps we could take a vote on all of the nominations and the top 5 would become admins? Maybe this league should have admins that are community-elected? As well, hakudushi said that he was willing to take on the challenge.
2. Infrastructure. As Donka suggested, there is the option of using Donka's Wolfenstock. Highone also suggested keeping the TWL infrastructure, however I do not think that would work out as well as hoped unless TWL had absolutely no control over it, and I don't see them agreeing to that.
3. Server configuration. I believe that at this time the current TWL OSP configuration is quite good, although if there are major concerns people can voice them here.
4. Servers. I know that Dark can supply a server (possibly two) if this league is to happen. How about you? Would many clans agree to keep paying for the servers that they have up? I don't think that the league would need to provide any servers seeing as most teams have their own.
5. And of course, money. Some people suggested that the league require a fee to play, but I do not think that it's a good idea. However, I have come up with a suggestion. Since this league would be 6v6, and it would be costly to award 6 prizes, maybe if one prize were donated it could go like this: The finals match is viewed on WTV, after the match, a poll is set up and viewers vote on who the MVP of the match was for the winning team. The MVP would then win the prize. However, there does not even have to be a prize, and I'm sure that a lot of people wouldn't find not getting a new mouse or something such a big deal.
With that being said, I think that there should also be a player cap. 12 people per team sounds sufficient, that gives room for 6 starters and 6 back-ups. The more teams the better.
Post any ideas, suggestions, comments, and support.
Oh and I couldn't think of a name for the league :O |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (235)
.:Back to Top:. |
|
|
|
| ET:QW Anytime Apr2007-Mar2008 |
| Posted on Friday, January 26, 2007 at 07:51:54 PM | -doNka- |
|
| |
From Activision press release:
"The company believes that its fourth quarter results will be significantly impacted by higher legal expenses relating primarily to its internal review of historical stock option practices, including expenses relating to the previously announced informal SEC inquiry and derivative litigation, and its decision to move the release of Enemy Territory(TM): QUAKE Wars into fiscal year 2008."
No jokez.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (63)
.:Back to Top:. |
|
|
|
| TWL OSP the 13th: Week 8 UFO |
| Posted on Thursday, January 25, 2007 at 10:03:46 PM | SyndicateGromit|TWL |
|
| |
TeamWarfare OSP 13 League

The Playoffs start next week so let's start aiming for the head.
Week 8 will be played Jan 31:
Week 8 matchups
Syndicate.Soldiers v. Xtreme.$oldiers
TheJollyRGR [:x] v. Animate.gaming
Team_Trinity v. The Pain Train
Point.Blank v. CriticaL IMPulse-
|DaRk| v. Total Havoc
High Life v. Cross:+:Breed
Default Date and Time: Wed night, JANUARY 31, 2007 @ 10:00pm EST.
Week 6 Map: TE_UFO
Deadlines:
Teams and rosters are locked.
PLAYOFFS:
I suspect that we will go to an eight (8) team playoff this season. The main reason for this is that with only 12 teams at this point (last season we had 16), having every team make the playoffs would require giving 4 byes the first week. Rather than forcing the top 4 teams to wait 2 weeks between matches, I think the more reasonable thing is to drop the lowest 4 teams from the playoffs.
I am, however, willing to bend to the will of the league. Anyone who strongly favors a 12 team playoff, please post here or otherwise message me.
Assuming an 8 team playoff picture, this is a VERY important week as all but 3 teams have their final rankings up in the air. glhf.
TWL|Gromit |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (49)
.:Back to Top:. |
|
|
|
| Continuing RtCW Competition |
| Posted on Thursday, January 18, 2007 at 04:56:15 PM | Mauler [c0ff] |
|
| |
To those with interest:
After reading up on the TWL forums about the end of RtCW, it seems there is still quite a bit of interest. If I can get enough people interested, I'm willing to organize and host RtCW myself. I think the easiest way to determine this is through email.
Anyone who can field a team of 6+ people, please send me an email with your name and everyone who would be on your roster: rtcw@c0ff1.com
My long term goal is for this to start small and build up over time. When/if we build enough interest (or even for the first season if we have 8+ teams) I'm happy to do a pay-to-play system in order to keep people competitive. 8 teams x 6 players x $10 = $480 minimum, which comes out to $80 per player. If it grows we can talk about more options.
Depending on what I hear from people, I may organize something in the form of a website or forum in order to discuss the concept further. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (67)
.:Back to Top:. |
|
|
|
| TWL RTCW OSP 13: Week 5 |
| Posted on Friday, January 5, 2007 at 04:08:58 AM | SyndicateGromit|TWL |
|
| |

TeamWarfare OSP 13 League is 1/2 way to the playoffs. Week 5 wil be played Jan 10 and features the following matchups:
Week 5 matchups
Syndicate.Soldiers v. |DaRk|
TheJollyRGR [:x] v. High Life
The Pain Train v. CriticaL IMPulse-
Cross:+:Breed v. Point.Blank
Team_Trinity v. Total Havoc
Animate.gaming v. No Medics Necessary
WANsanity v. Team-Lethal Injection
deathrow.rtcw v. Xtreme.$oldiers
PLEASE REMEMBER that the rosters lock on Jan. 9, 2007 at 11:59pm est.
Default Date and Time: Wednesday night, JANUARY 10, 2007 @ 10:00pm
Week 4 Map: BASE
Revised OSP League Config:
http://www.teamwarfare.com/forums/showthread.asp?forumid=12&threadid=340569
The changes are few:
OSP - Universal Config - League and Power Ladder
- Config file renamed from o_lg.cfg to o_twl.cfg
- cl_timenudge changed from in -50 0 to in -20 0
- g_log changed from o_lg.log to o_twl.log
Deadlines:
Roster Lock: Jan. 9, 2007 at 11:59pm est
Rules:
http://www.teamwarfare.com/rules.asp?set=Return+to+Castle+Wolfenstein+League
Please note one significant change to the league scoring system. This season, forfeit losses will result in -1 league point. In the past, forfeit losses were scored 0 points:
Wins - Credited 3 League Points, 1 Win, and Rounds Won/Rounds Lost
Byes - Credited 3 League Points and 1 Win
Forfeit Win - Credited 3 League Points and 1 Win
Loss - Credited 1 League Point and Rounds Won/Rounds Lost
Forfeit Loss - Debited 1 League Point
Happy New Year, everyone.
TWL|Gromit
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (39)
.:Back to Top:. |
|
|
|
| New Poll - Sensitivity. |
| Posted on Thursday, December 21, 2006 at 07:34:54 PM | -doNka- |
|
| |
This topic will not die even when everyone switches to consoles. Mouse/controller sensitivity is a very personal preference that takes sometimes days to get used to and only seconds to lose. This is one of the most addressed variables of all times on all forums in most mouse related games.
Do you know what your sensitivity is? No everybody realizes that sensitivity is not just a number that you type in your console.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (41)
.:Back to Top:. |
|
|
|
| You Got Mice! |
| Posted on Wednesday, December 13, 2006 at 07:16:35 AM | -doNka- |
|
| |
There is one article on the internets that has been raging the ratings in the IT world for the last couple of days. Sujoy, the father of THE esports site ESReality.com, posted an amazing research on benchmarking computer mice. This is one of the most "sensitive" topics in the gaming world, so I'm sure most of you will relate to it.
Picking out the best mouse is a tricky business because we have to combine different benchmark scores. It's like judging cars where each one has a 0-60mph time, a top speed, and different suspension. A Formula 1 car might be perfect for racing at Monza, but won't do so well in a cross country rally. I've combined all of the mouse results by taking them as a factor of the top performer.
Read entire article HERE |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (63)
.:Back to Top:. |
|
|
|
| Possible Shrub Season?? |
| Posted on Friday, December 1, 2006 at 07:07:04 AM | [a]str33tz |
|
| |
Niteswine posted on TWL Forums shortly after SS won the season.
http://www.teamwarfare.com/forums/showthread.asp?forumid=52&threadid=341678
Congrats to SS on another win, and also to SeaDawg on another season. Tried some new things this last go'around, and it seemed to work out pretty well.
So, let's talk about a potential 7th league for this mod. Is there enough interest? I'm inclined to delay starting anything before the 1st, but we can determine interest-level and set up some parameters.
From the hip, I'm leaning towards a standard maps season, using the following parameters:
* No-shows will result in a -1 point, applied to their league point accumulation.
* Any team with less than 6 league points at the end of the 8 week regular season will not be advanced to the playoffs.
* There are 8 weeks in the regular season. All teams should earn at least 8 league points. A team that plays 7 matches, but no-shows on a single match will end up with only 6 league points.
* A team that no-shows more than 1 time during the regular season will be unable to participate in playoffs.
* Beginning after the second week of regular season, any team having a negative league point value throughout the remainder of the regular league will be removed from the league.
* A team joining at mid-season will need to win at least one match in order to earn 6 or more league points -- call it a risk for joining late -- so, join now! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (21)
.:Back to Top:. |
|
|
|
| TWL RTCW OSP 13: Week 2 |
| Posted on Thursday, November 30, 2006 at 06:44:09 PM | SyndicateGromit|TWL |
|
| |
 
TeamWarfare OSP 13
Week 2 matchups
Animate.gaming v. Cross:+:Breed
High Life v. Syndicate.Soldiers
Team_Trinity v. WANsanity
Critical Impulse- v. The Jolly RGR
The Pain Train v. Xtreme.$oldiers
|DaRk| v. No Medics Necessary
Point.Blank v. Total Havoc
Xtreme $trike Force - XSF is the only remaining team which forfeited last night. XSF is getting a bye, but must send me a ss of at least 5 of their players on a server (with GUIDs revealed) at matchtime next Wed. If I do not receive this ss by 11:59pm next Wed, they will be kicked from the league.
Default Date and Time: Wednesday night, DECEMBER 6, 10:00pm EST.
Week 2 Map: ASSAULT
Revised OSP League Config:
http://www.teamwarfare.com/forums/showthread.asp?forumid=12&threadid=340569
The changes are few:
OSP - Universal Config - League and Power Ladder
- Config file renamed from o_lg.cfg to o_twl.cfg
- cl_timenudge changed from in -50 0 to in -20 0
- g_log changed from o_lg.log to o_twl.log
Deadlines:
League Lock: Wed., Dec. 20, 2006 at 11:59pm est
Roster Lock: Jan. 9, 2007 at 11:59pm est
Rules:
http://www.teamwarfare.com/rules.asp?set=Return+to+Castle+Wolfenstein+League
Please note one significant change to the league scoring system. This season, forfeit losses will result in -1 league point. In the past, forfeit losses were scored 0 points:
Wins - Credited 3 League Points, 1 Win, and Rounds Won/Rounds Lost
Byes - Credited 3 League Points and 1 Win
Forfeit Win - Credited 3 League Points and 1 Win
Loss - Credited 1 League Point and Rounds Won/Rounds Lost
Forfeit Loss - Debited 1 League Point
Gromit|TWL |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (102)
.:Back to Top:. |
|
|
|
| RTCW Week: OSP 13 Starts. Info and Preview. |
| Posted on Sunday, November 26, 2006 at 11:13:06 PM | -doNka- |
|
| |
This week Shrub league will pass the flag to OSP. OSP matches start Wednesday night, Nov 29th and will continue till late february. So shake off that turkey fat you've accumulated during the weekend, wash off the gravy from your chin and get ready for the new season! It's been quite a while since OSP 12 season ended, so I'm sure people are already itching for some action.
Currently Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (26)
.:Back to Top:. |
|
|
|
| Celebrating the Big 5! |
| Posted on Monday, November 20, 2006 at 07:10:51 PM | -doNka- |
|
| |
MESQUITE, Texas - Nov. 20, 2001 - Retail outlets are bracing for the blitzkrieg with the announcement that id Software's Return to Castle WolfensteinTM for the PC is now available. Activision, Inc. and id Software confirmed today that the title has been shipped to retailers and will be available on November 20 for a suggested retail price of $49.99.
Today we're celebrating 5 years since RTCW hit the shelves back in 2001. That's been exciting time for all of us and there's more to come. During that time frame people grew, finished schools, graduated from universities, got and changed jobs, married, had kids. It's a lot of time if you try to go back and remember what happened to you while you were actively involved into RTCW scene.
Let us have a 5 years anniversary celebration OSP pub tonight at Hell Gate 1 with stats and your old friends. Attach [5] at the end of your nickname. Please, let your friends know who you are by showing up with your real nickname.
Please make sure your friends know about it. Notify them via MSN, AIM, Xfire if you wish.
Tentative start at 10pm EST. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (16)
.:Back to Top:. |
|
|
|
| Battle For Berlin - Tournament Championship Match |
| Posted on Friday, November 17, 2006 at 11:32:39 PM | Mortal :o |
|
| |

Battle For Berlin is proud to present the last match in the tournament, the tournament championship match!
.gif) Hostile Inc vs. Hostile Inc vs.  HighBot on Ice tonight! HighBot on Ice tonight!
Hostile Inc is made up of Slayaya (fX, opp), Remedy (wSw, fX), Rambo (-a-, fX) and their backup Serum (fa, -Tv-). They are a solid team, with alot of experience with each other.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (26)
.:Back to Top:. |
|
|
|
| Battle For Berlin: Second Round |
| Posted on Monday, November 6, 2006 at 09:03:34 AM | Mortal :o |
|
| |
Battle For Berlin proudly presents the second round of tournament matches!
The third day will encompass the first 8 Winners Bracket Matches, and the forth day will encompass the first 8 Losers Bracket Matches. Both Winners and Losers Bracket Matches will be played on Base.
We should have some coverage from BFBRadio (DJ: Alp!ne), Radio-iTG (DJ: Trillian, DeeAy, Vradi), and WolfTV (Cam: Digita|, Xero, PissClams, etc.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (29)
.:Back to Top:. |
|
|
|
| SmokeH3rb OLTL XSTAB |
| Posted on Saturday, November 4, 2006 at 06:26:01 AM | [a]str33tz |
|
| |
[A]nimate.Gaming is proud to announce the revival of SmokeH3rb.
For those that don't know, BULL-Z and STR33TZ decided to open up SmokeH3rb, a former OLTL XSTAB Pub. This server will be located in CHICAGO and features a 26 slot server + 4 private slots.
Now I know what everyone is wondering, what makes this OLTL XSTAB server different than the rest? Well for starters, the location is Chicago.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (18)
.:Back to Top:. |
|
|
|
| Shrub Playoffs Week 1 Results |
| Posted on Friday, November 3, 2006 at 06:41:05 AM | [a]str33tz |
|
| |
Results for the first round of playoffs are
syndicate vs BYE
-ASC- vs .:. 0-3 Assault, UFO, Frostbite
lamp-vs [op:4] 3-2 (Lamp refuses to tell us what maps were used)
-[x]- vs Dark 3-2 Axis_Complex, Assault, Beach
[a] vs rage 3-0 Assault, Ice, Base
-TAO- vs =nMn= 2-3
:+: vs -Tv- 0-3 Assault, Rocket
(!) vs :) 3-0 Base, Beach, Keep
Good luck to all teams moving on to round 2 of playoffs.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (14)
.:Back to Top:. |
|
|
|
| Shrub League Round 1 of Playoffs |
| Posted on Friday, October 27, 2006 at 06:40:36 PM | [a]str33tz |
|
| |
Season 6 will be featuring a new way of picking playoff maps...
1. Higher rated team will select first map, which will be used for the first round
2. Team losing the first round will select a map for use in the second round
3. Team losing the second round will select a map for use in the third round
4. Team losing the third round (if match is not set) will select a map for use in the forth round
5. Team losing the forth round (if match is not set) will select a map for use in the final, fifth round.
Matchups are as follows
syndicate vs BYE
-ASC- vs .:.
lamp-vs [op:4]
-[x]- vs Dark
[a] vs rage
-TAO- vs =nMn=
:+: vs -Tv-
(!) vs :)
Good luck to everyone. Let the predictions begin.
Remember please check your stocks, vote on MOTW and vote for stock predictions. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (25)
.:Back to Top:. |
|
|
|
| BFB Tournament only days away! |
| Posted on Thursday, October 26, 2006 at 05:42:26 AM | [a]str33tz |
|
| |
With Battle For Berlin only days away, lets take this time to be active on the osp servers.
Hells Gate #1
and
Hells Gate #2
Are up and running. Thanks to Donka, since 10:00 PM est. and on through the night, Hells Gate 1 has been full of pubbers. I personally took the time to get my shot back and prepare for BFB. Lets stay active until OSP season 13 starts!!!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (4)
.:Back to Top:. |
|
|
|
| Forever Rage |
| Posted on Friday, October 20, 2006 at 03:52:04 AM | Merlin@toR |
|
| |
Earlier this year Marcus Welfare was swept out to sea on a family trip with his family, shortly afterwards I decided to make a movie, with a lot of help, as a tribute to such a well liked player and one of the few public server characters-
Forever Rage
http://www.own-age.com/vids/video.aspx?id=9394 own-age movie page, swertcw and filefront links and other posted mirrors can be found here-
please note when watching that all frags are from limbo spectating and/or spectators on the server- none are from Rage's original POV
Thanks- |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (17)
.:Back to Top:. |
|
|
|
| TWL RtCW - New Ladder Competition |
| Posted on Thursday, October 12, 2006 at 04:45:30 PM | NiteSwine|TWL |
|
| |
TWL RtCW will be phasing out standard competition ladders due to inactivity. While policy suggests/recommends completely dropping ladder competition, the admin staff for this particular game wishes to provide an option we hope will benefit the community: Power Ladders.
Power ladders are different than competition ladders in many ways:
1. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (9)
.:Back to Top:. |
|
|
|
| Shrub Night Tonight |
| Posted on Thursday, October 5, 2006 at 07:53:15 PM | -doNka- |
|
| |
Tonight's the special night for shrub. First time since ..ever TWL Shrub league will have it's own predictions and stock sections set up. You can use the links below to use the site features associated with TWL shrub league matchups.
View Upcoming Matches
View/Manage Stocks
Post Predictions
Notice that Richest Stock Traders section was modified to display only active users. Let me point out that it's the best time ever to bet your money since the OSP playoffs are over and Shrub teams are starting fresh. You have several hours before stocks and predictions lock themselves down for the rest of the night.
There were several questions about MOTW section of the site. It allows users to vote for their favorite matches, but it currently uses different algorithm to determine MOTW. It goes by the closest user predictions, not by the votes. I will think what could be done about it in the nearest future.
There are currently 15 teams in shrub season, and OSP season will be coming up soon.(this is actually up to TWL admins). Even though things always look a little slow between seasons there are still people who want to play league matches and pubs after having some rest. Make sure you tell your RTCW and ET friends about current activities and let them know what's coming up.
We still have two major pub servers from =Fedz=
Hells Gate 1
Hells Gate 2 |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (8)
.:Back to Top:. |
|
|
|
| Interview with TosspoT of Radio ITG / Crossfire |
| Posted on Tuesday, October 3, 2006 at 05:46:25 AM | Mortal :o |
|
| |
I recently sat down with TosspoT, shoutcaster for Radio ITG and administrator with Crossfire. The result was quite an interesting interview.
TosspoT has accomplished much in his time in the European community, with him being apart of one of Europes largest community sites, a vast archive of shoutcasts for matches in ET, RtCW, CoD, Warcraft, and more!, and quite an interesting clan history.
He's a great guy, and I hope you enjoy the interview!
Interview: http://www.planet-rtcw.com/?page=articles&id=249 |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (8)
.:Back to Top:. |
|
|
|
| TWL Season 12 Stocks Winners |
| Posted on Monday, October 2, 2006 at 06:47:01 PM | -doNka- |
|
| |
Stocks were brought back to life at the beginning of this past TWL-12 season. Cash amounts for all users were reset and the behind-the-scenes competition started. 73 users made predictions and purchased stocks in a race for the title of the most accurate e-sports analyst in RTCW discipline. The results are in.
Top 3 E-Sports Analysts in RTCW discipline are:
1. crapshoot - $23,609.70
2. w0rd* - $19,370.71
3. /blur/Lloyd - $18,642.85 |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (18)
.:Back to Top:. |
|
|
|
| Greetings from Alias |
| Posted on Friday, September 29, 2006 at 02:03:28 AM | gisele |
|
| |
As many of you are aware, Kevin "Alias" Newman quit the internets for real-life Return to Castle Wolfenstein a few months ago when he joined the U.S. military. Both Sage and I have since received letters from him, acknowledging that he is indeed alive and well!
Alias want's everyone to know that he misses us all and says "hi.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (43)
.:Back to Top:. |
|
|
|
| Battle For Berlin - 11 slots left... |
| Posted on Sunday, September 17, 2006 at 03:17:29 AM | Mortal :o |
|
| |

Hello Planet-RtCW,
Battle For Berlin is going in the right direction with some new additions to the team list, map testing in-progress, and CVAR/rules being finalized soon.
We are still looking for 3 more EU admins to help out the tournament, aswell as 1 NA admin. If anyone is interested please contact me asap.
There are only 11 spots left out of 32, with each day 2-3 more teams sign up. Please sign up asap to hold a spot for your team for the tournament. Send a "draft" with your team name, 3 players + guids, and a team leader email (all which can be changed prior to the tournament) asap.
More info on the tournament:
Battle For Berlin News
Battle For Berlin Team Registration
Battle For Berlin Game Rules
Battle For Berlin Forums
Thanks for taking interest in Battle For Berlin! For detailed listings on our prizes, sponsors, rules, brackets, and more; please visit our website. Thanks and enjoy the tournament!
Zach "Mortal" Hooper
Battle For Berlin Tournament Director |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (20)
.:Back to Top:. |
|
|
|
| Sites Hacked |
| Posted on Saturday, September 16, 2006 at 06:28:32 AM | CyberKnight |
|
| |
Sometime today all the websites on the network including 100's of others got hacked. All the websites delete, everything.
I got the most current database I had on me atm which was from Sept 10th, its a bit old. But it is better then starting out fresh.
Sorry for the problems, the website may not be stable yet. But we are working on it. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (10)
.:Back to Top:. |
|
|
|
| Shrub Season 6 Week 1 on Assault |
| Posted on Monday, September 4, 2006 at 07:38:45 PM | [a]streetz-work |
|
| |
Week ones matchups which were made by we happy few's trinners will feature the following teams....
-[x]-Treme v We Happy Few
Squad Bravo v The Pain Train
Cross:+:Breed v The Awesome Ones
-Dark- v Team Hostility
I Love Lamp v Team Seven Sins
No Medics Necessary v Syndicate-Soldiers
onslaught v Opposing Forces RTCW
These teams did not receive a match due to not having enough players on the roster at time of posting.
D-Up
team trinity
Team Untouchable
The swat guys |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (39)
.:Back to Top:. |
|
|
|
| Battle For Berlin - We need Testers, Admins, and your opinion! |
| Posted on Sunday, September 3, 2006 at 12:01:21 PM | Mortal :o |
|
| |
Battle For Berlin needs your help! We are looking for admins to help oversee matches, help spread the word about tournament updates, and provide their personal expertice as needed.
We are also looking for teams to test custom maps. We have quite a few selected that have passed the initial admin testing, but want to see what a team of competative players thinks of it. We currently need 2 more teams.
We also want your opinion on anything and everything! We want to know what CVARs you want, what maps you want, and what we should do to make the tournament better. Any of these can be posted at any time in our forums.
Battle For Berlin is also taking donations for better prizes and more servers, if you are intersted please read more about it on our news page.
Also, Team Registration is open, but please read the recent news posts on the site, and the rules, carefully before registering. We currently have 2 teams with all the required info submitted, and about 4 still needing more required info.
I hope to see more register, and please understand one crucial thing; you can change your roster, who your starters are, who your backups are, etc. until the tournament starts. Some players got confused and thought that when you submitted your team registery it was final. We would hope it would be, but we understand things change with time. Please register with what you have now; but understand that you can change your team info until the tournament starts. After the tournament starts, no changes of roster will be allowed.
We added a bar under the banner with links to the CVARs page, Files Page, Maps Page, Teams Page, Registration Form, and Forums to help your navigation. Hope it helps and hope to here from some of you soon!
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (9)
.:Back to Top:. |
|
|
|
| TWL OSP Season 12 Playoffs!!! |
| Posted on Saturday, September 2, 2006 at 12:03:17 AM | |
|
| |
Although the brackets are awaiting TWL creation, the matchups for the Playoffs are up: http://www.teamwarfare.com/forums/showthread.asp?forumid=12&threadid=327784
The format is as follows: 16 teams (top 8 from each division) with 4 weeks composing this single elimination playoff:
Maps:
Week 1: Frostbite
Week 2: Beach
Week 3: Base
Week 4: Ice
Week 1:
- Map: Frostbite
- Default Date and Time: Wednesday, September 6, 10:00est
Allied Division:
#1 Teh Birdz v. #8 team nameless
#4 Rabia v. #5 RSF
#3 onslaught v. #6 CrossBreed
#2 Tribal Valor v. #7 ICF
Axis Division:
#1 The Jolly RGR v. #8 Team Trinity
#4 Papichulos v. #5 Dark
#3 Syndicate v. #6 Blur.rtcw
#2 Total Havoc v. #7 Breakdancers
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (196)
.:Back to Top:. |
|
|
|
| First NIC for Gamers! Reviewed |
| Posted on Friday, September 1, 2006 at 08:37:06 PM | Spiza |
|
| |
...in theory, that the CPU comes under no load for network processing, and all calls from software or games for network information go directly to the Killer NIC, eliminating numerous cycles from the CPU's processing loop. Cutting Windows' UDP protocols out of the loop also has the potential to lower latency between user and game server. The Killer NIC also prioritizes both inbound and outbound network traffic and can prioritize gaming packets above all others.
Source: http://gear.ign.com/articles/729/729557p1.html |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (19)
.:Back to Top:. |
|
|
|
| Support RTCW Players for Free |
| Posted on Tuesday, August 29, 2006 at 07:56:17 PM | fu|megs |
|
| |
"August 29, 2006 – Dallas, Texas - The CPL announced that its title sponsors AMD and ATI are offering 1,000 free spectator passes for the CPL 2006 Championship Finals taking place Wed., Dec. 13 to Sun, Dec. 17, 2006 at the Hyatt Regency Hotel in downtown Dallas.
These free spectator passes will be available online commencing, Thursday, August 31, 2006 at www.thecpl.com/register/?page=freepass&eventid=21 on a first-come, first-serve basis only.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (17)
.:Back to Top:. |
|
|
|
| GGL-DonKing is the new Santa |
| Posted on Monday, August 28, 2006 at 06:09:55 AM | gisele |
|
| |
Lots of exciting things happening amongst our community, friends! Aside from many upcoming events that will definitely benefit this game and community are some CLASSIC demos that were unreleased until now!
GGL-DonKing has been gracious enough to release some cool demos that he has had since 2002. Ever wondered how q3 allstar CZM did in RTCW?! Here's your chance to view them and see for yourself!
Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (9)
.:Back to Top:. |
|
|
|
| RTCW Players seek Q3 Victory at the CPL |
| Posted on Friday, August 25, 2006 at 06:52:12 AM | gisele |
|
| |
As many of you are well aware, the 2006 CPL Winter Championship Finals competitor registration began on August 10, 2006. According to thecpl.com as of 11 pm last night, there were only two spots left in the Q3 1v1 tournament. Next to names such as czm, Fatal1ty, daler, Cha0ticz, RocketBoy, cooller, socrates, etc... Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (18)
.:Back to Top:. |
|
|
|
| Alias Says: 3 Days GG! |
| Posted on Friday, August 25, 2006 at 03:53:00 AM | -doNka- |
|
| |

Some of you might have seen Al!@s(dR, TV) playing on pubs with some strange looking names such as "10 days GG!". The meaning behind it is that Alias is going away to join the army in a couple of days. He's being sent to a boot camp first in South Carolina, and then.. well, who knows. Let's hope for the best. It seems for now that it's going to be a 4 year commitment with the United States Marines. Give a guy a round of applause as he leaves RTCW pubs to fight for the freedom in RL and wish him the best of luck in his endeavors.
(roger|dNk) if you gonna make a will, put one of the bulletings that your wolfenstein clan gets notified via irc
(alias`GG`3days) :) i will trust me |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (44)
.:Back to Top:. |
|
|
|
| Stumbled upon this |
| Posted on Monday, August 21, 2006 at 06:58:18 AM | -a-WarRi0R |
|
| |
"You may not know his face, but actor Tony Jay has provided his voice for a multitude of video games. On August 13, Jay failed to recover from micro surgery to remove a non cancerous tumor from his lungs and passed away. He contributed his voice talents to such titles as the Fallout series, World Of Warcraft, and Return to Castle Wolfenstein."
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (41)
.:Back to Top:. |
|
|
|
| People Like Us |
| Posted on Thursday, August 17, 2006 at 05:40:33 PM | -doNka- |
|
| |
I don't believe too many people around here are aware of the international RTCW scene. Warleagues.com:rtcw seems to be very much alive. What's interesting though, they seem to have same exact problems like we do around here: hackers getting busted every other week, rule changes, and major flaming. If 250 comments posts on planet-rtcw is not enough drama for you, go and check out euro RTCW competition website. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (14)
.:Back to Top:. |
|
|
|
| TWL Shrub Season 6 now open for sign ups |
| Posted on Thursday, August 17, 2006 at 05:38:53 AM | [a]streetz-work |
|
| |
Twl has announced the sign ups for shrub season 6. http://www.teamwarfare.com/forums/showthread.asp?forumid=52&threadid=325253
They want to encourage as many teams as possible to join. Now I know many of you hate shrub... But please put into consideration that a lot of us shrubbers have come over to play osp. So please consider making teams and competing. This would give you ospers some off season practice and keep you all active. Once a team joins, every founder can send their 3 choices of maps to be played for this season and the most popular ones will be selected. Once again please consider joining/supporting the shrub league.
For anymore information about shrub season, see the forums or contact niteswine |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (31)
.:Back to Top:. |
|
|
|
| The remainder of our RTCW community. |
| Posted on Monday, August 14, 2006 at 11:23:25 PM | [a]streetz-work |
|
| |
In recent events that have occured, TWL Admin Vixen has resigned. As you can see here http://www.teamwarfare.com/forums/showthread.asp?forumid=12&threadid=324773 Niteswine and staff is not happy about this and neither are the "Big Guys" over at TWL. Pretty much to make a long story short, they are thinking about shutting down our RTCW community. This pretty much means CUT THE SHIT EVERYONE!! We can't let stupid things get to us and let it upset people and make this small community look bad. Right now the only thing we can do is prove to the big guys over at TWL why rtcw should remain an active game at TWL. This means e-mail TWL, and the number 1 thing we should be doing now is involving everyone, the bani players, shrub players and osp players need to come together and post at TWL and show them the interest we still have for this game. Tell them why they should keep this game going and why this game is great. This event should encourage the whole RTCW community to come together more and participate in more leagues together.
Also, because of the departure of Vixen, we may not have enough servers next season if TWL doesn't shut us down that is. So lets see what we can do to get people to either donate torwards getting some servers or see if someone can donate them to us. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (73)
.:Back to Top:. |
|
|
|
| TWL Results |
| Posted on Thursday, August 10, 2006 at 04:14:11 AM | c[_]`Wippuh |
|
| |
3 Dark - 0 Hostility
3 Breakdancers - 0 Morbid X (Forfeit)
3 Onslaught - 0 Precision
3 Rabia - 1 Cross Breed
3 ICF - 0 RSF
3 TH - 2 SS
3 Blur - 0 -x- (Forfeit)
3 Rgr - 1 Papichulos
3 Trinity - 1 TSG
And then the drama llamas came out to play in...
3 TV - 2 Birds
From Caff:
"last round 2-2 birds hold 4:04 or 4:14 on sub. birds on offense w/ 50 seconds left in the match, 3 birds mysteriously "crash" (like, the big freeze, can't bring down console or alt+enter or end program, crash). so grom decides, on his own, that it didn't warrant a round reset. 3 birds (who were all alive and pushed into the sub) crashed. so those 3 players had to /kill w/ 9 seconds left on spawn, leaving a 3 on 6 until 41 seconds left on the clock. good admins."
New Poll up, tell us what you think! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (264)
.:Back to Top:. |
|
|
|
| Free Fear |
| Posted on Wednesday, August 9, 2006 at 02:35:14 AM | Spiza |
|
| |
SIERRA ANNOUNCES F.E.A.R. COMBAT
F.E.A.R. Multiplayer to be made available for free.
LOS ANGELES, CA – (August 8th, 2006) – Sierra Entertainment today announced that the multiplayer component from the award winning PC title F.E.A.R.™(First Encounter Assault Recon), has been renamed F.E.A.R. Combat, and will be made available to the public as a free download on Thursday August 17th, 2006.
F.E.A.R. Combat is the complete multiplayer component of F.E.A.R. and includes all the updates, additional official maps and additional official game modes all in one downloadable file. F.E.A.R. Combat users will be able to play against the owners of the retail version of F.E.A.R. as well as the other F.E.A.R. Combat users.
F.E.A.R. Combat features:
* 10 Multiplayer Game modes.
* 19 Multiplayer Maps.
* 12 different weapons.
* Punkbuster support for anti cheat support.
* The capability to download user generated content.
To play F.E.A.R. Combat, consumers simply go to www.joinfear.com and register to obtain their free, Combat keycode. When the file is made available for download on Aug 17th 2006, consumers can install, enter their keycode, and get ready to join F.E.A.R. Combat!
To get more information on F.E.A.R. Combat, please visit www.whatisfear.com or www.fearfans.com.
F.E.A.R. Combat will be available for download on August 17th 2006. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (27)
.:Back to Top:. |
|
|
|
| Gothlips - The E! True Gamer Story |
| Posted on Tuesday, August 8, 2006 at 09:40:11 PM | gisele |
|
| |
Today's Gamer Life over at the GGL is one of our very own - Gothlips!
What is the point of doing something if you are not going to at least try to do it the best? There is no excuse for settling for sub-par. You only live once, why not live it the best? I take a lot of pride in my accomplishments, as few and as far between as they may be. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (18)
.:Back to Top:. |
|
|
|
| Qcon Return to Castle Wolfenstein Banners!! |
| Posted on Monday, July 31, 2006 at 11:05:41 PM | KeP |
|
| |
Alright, so I didn't get any REAL submissions of ideas for the banners, so they will be pretty generic. Here is the image I used, it's the image from the front of the RtCW box.

There will be two of them printed out and pasted onto a foamboard backing. (Vinyl banners would have been about $200, kinkos wanted $160. So instead we have some easy prints on a foam backing)
They will be propped up on the table. Each is 32" x 42" so they should be fairly large and visible. In order to fit all the rtcw players onto a single table or several tables in an area, the area will be setup in a back corner. This will be a lower traffic area which leaves more space open for our fellow wolf players. The BYOC opens at 8am Thursday. Depending on when I get in, they will be setup that morning - sometime before noon. So if you are a wolf player setting up in the BYOC, keep an eye out for the 3 foot by 4 foot signs propped up on the table!!
Hope to see you all there! And I hope you can see the signs! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (13)
.:Back to Top:. |
|
|
|
| Gamer Life: Shea "Gisele" Smith |
| Posted on Thursday, July 27, 2006 at 04:18:13 PM | -doNka- |
|
| |
GGL continues their series of interviews with the one and only Shea "Gizle" Smith:
Yet you have a passion to game a lot. What makes gaming so great for you?
It used to be my love for the game - RTCW. I was so obsessed with that game that I would literally stay up all night playing. Since the current gaming scene is in a weird position right now, it is mainly the relationships with people I have come to know and love playing with over the years, that keeps me around. Any game can be fun if you are playing with the right people. That is all it is for me - fun. (Also, I really do love watching males get angry when I kill them!)
Read the whole article HERE
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (165)
.:Back to Top:. |
|
|
|
| TWL OSP League: Week 5 Postponed for QCon |
| Posted on Monday, July 24, 2006 at 10:48:52 PM | SyndicateGromit|TWL |
|
| |
Although I'm still reeling from the news that an eight 5-man team ET tournament won out over RTCW, we've decided to pay our respects to id software and those of you traveling to Dallas next week by postponing Week 5 from Wednesday, August 2 to Wednesday, August 9.
The submarine will continue receiving short-lived repairs while awaiting its destruction on August 9.
Please note that this announcment pertains to WEEK 5, not this week's match on Village (I'd like to think that last statement is not necessary, but I think we all know that it is ;)) |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (26)
.:Back to Top:. |
|
|
|
| Week 3: UFO Exploits |
| Posted on Monday, July 17, 2006 at 08:57:51 PM | SyndicateGromit|TWL |
|
| |
NOTICE:
Both the top and backside of the mountain to the North of the radio building are OUT-OF-BOUNDS this week.
For anyone who wonders why, please go to the backside of the mountain and head West. There, you will find huge clipping errors which allow a player to see much of the front, side and back of the map while remaining concealed.
These situations are covered quite clearly in the TWL rules:
TWL RtCW General Rule set
§4.4 Exploits and Bugs
... 7. On some maps it is possible to see through walls, floors, and ceilings into other areas of the map. These clipping errors are not to be exploited during match competitions.
I apologize if this disrupts any team plans.
http://www.teamwarfare.com/forums/showthread.asp?threadid=319564&forumid=12 |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (13)
.:Back to Top:. |
|
|
|
| Thinking About A Hardware Upgrade? Now Is Your Chance… |
| Posted on Friday, July 14, 2006 at 11:01:59 PM | pissclams |
|
| |
Thinking About A Hardware Upgrade? Now Is Your Chance…
There may not have been a better time within the past 5 years to upgrade than now. What’s driving this? In the bitter CPU war between AMD and Intel, it’s been AMD on top, delivering price and performance over anything that Intel was able to offer the market. That’s now changed.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (43)
.:Back to Top:. |
|
|
|
| First NIC for Gamers! |
| Posted on Friday, July 14, 2006 at 03:56:53 PM | c[_]`Wippuh |
|
| |
Is there any doubt that the nerds who obsess over their mousepads will be all over this.
Here's a nice little quote, MaxFPS technology frees up CPU cycles typically taken up by heavy network traffic by offloading the required processing onto the Killer NIC’s 400MHz network processor. UltimatePing technology lowers ping by optimizing data delivery to games faster while PingThrottle technology allows users to increase or decrease ping accordingly.". |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (15)
.:Back to Top:. |
|
|
|
| QuakeCon Waves Hit European Coast. |
| Posted on Thursday, July 13, 2006 at 06:47:18 AM | -doNka- |
|
| |
As we all saw (below) Quakecon announced its games for 2006 tournament. With 20 days to go people are running around looking for airfare/hotel and sponsors to pay for all that. There're no need to remind that QuakeCon has been a prime international video games competition event for many years. However, this year the strength and the excitement of the worldwide competition is in serious danger. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (28)
.:Back to Top:. |
|
|
|
| Qcon2k6 Tournament announcement... |
| Posted on Thursday, July 13, 2006 at 12:40:37 AM | hollywood |
|
| |
Get ready to fire the rail gun again this year....
QUAKE 4 1v1 - $35,000
Two people, thousands of rounds, hundreds of rockets, only one champion. The first Quake 4 championship held at QuakeCon already promises to be a vicious battle to the finals. Don't miss it!
1st Place ... $15,000
2nd Place ... $7,000
3rd Place ... $5,000
4th Place ... $3,000
5th Place ... $2,000
6th Place ...Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (35)
.:Back to Top:. |
|
|
|
| ET:QW Release Delayed |
| Posted on Wednesday, July 12, 2006 at 03:39:37 AM | gisele |
|
| |
As part of a special developer diary series on Gamespy, Paul 'Locki' Wedgwood - head designer and developer at Splash Damage - announced some news that might make everyone awaiting ET:QW a bit uneasy:
"It's also been a challenging year, as the team here has given extraordinary effort towards completing the game this year. Unfortunately, sometimes effort isn't all you need -- sometimes you just need more time.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (24)
.:Back to Top:. |
|
|
|
| Stock Portfolios Have Been Reset! |
| Posted on Friday, July 7, 2006 at 11:04:07 PM | -doNka- |
|
| |
I've received numerous complaints about certain users' stock balances going to zero amounts. This happens when clans are being shuffled around in a preparation for a new league. And since nothing has been done since CAL-8 there had been a lot of preparations to be made. As a result of all this user portfolios have been reset to default amounts. For everyone. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (15)
.:Back to Top:. |
|
|
|
| Sign Up Your Clan! |
| Posted on Sunday, July 2, 2006 at 03:17:47 AM | -doNka- |
|
| |
I'm motivated to manage stocks and predictions for currect TWL season. Feel free to submit your clan for the competition. To do that you will have to go to "Admin/Sign Up Your Clan" menu and fill out simplest information about your team.
PS: I'll try to bring existing clans from inactivity, so if you think that your team already exists in the database PM me before submitting a new one. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (26)
.:Back to Top:. |
|
|
|
| Quakecon 2006 RTCW Banner BYOC |
| Posted on Thursday, June 29, 2006 at 08:50:04 PM | KeP |
|
| |
Now that Quakecon 2006 has been announced many people are scrambling to make their reservations and trip arrangements. But what about when you get to the BYOC? Standing in lines for hours among gamers that you don't know to be realeased into a large room full of 1800+ computers and people and possible confusion. Where do you set up your computer? Who do you sit next to? You don't want to be stuck in an area where you don't know anyone. Wouldn't you rather be sitting in an rtcw area or at least know where you could go to find some rtcw folks?
Last year at Quakecon there were several distinct camps of rtcw gamers and others scattered around not knowing where they might be able to find refuge.
This year I'll be attending again, and I want to help avoid that confusion.
So here is the deal. I'm going to be making up a large banner that will be hanging over an area to denote where rtcw folks can come and gather. It will be put in a lower traffic area so that the spots on the tables don't fill up so quickly with noobs that don't know what "class up" means.
What will the banner say? Well that's up for YOU to decide. Come up with your own design for the banner! Post the image you create on the thread here. The selected design will be printed on a 4 foot by 8 foot banner.
Remember that the banner will be fairly large so the image resolution must be high, and be visible from a distance in a large, possibly darkened room.
I hope to see some great images flow from the artistic members of the community! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (53)
.:Back to Top:. |
|
|
|
| When WoW is More than a Feeling... |
| Posted on Thursday, June 29, 2006 at 12:02:17 PM | gisele |
|
| |
AMSTERDAM, Netherlands (AP) -- An addiction center is opening Europe's first detox clinic for video game addicts, offering in-house treatment for people who can't leave their joysticks alone.
"Like other addicts, Bakker said, gamers are often trying to escape personal problems. When they play, their brains produce endorphins, giving them a high similar to that experienced by gamblers or drug addicts.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (10)
.:Back to Top:. |
|
|
|
| TWL RTCW Season #12 Preview! |
| Posted on Monday, June 26, 2006 at 09:54:15 PM | :+:VirUs047` |
|
| |
TWL-RTCW - Season #12 Preview:
When BOBIII was first announced, the general excitement that was buzzing around the RTCW community was of big name teams that were returning, old school players who were reinstalling and that wolf was very much alive again. TWL Season #12’s announcement was almost pushed from the radar in a matter of seconds when the BOBIII tourney began.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (31)
.:Back to Top:. |
|
|
|
| RTCW, private tunneling vs server? |
| Posted on Monday, June 26, 2006 at 03:35:22 AM | (7*up)LoXodonte |
|
| |
Read up on something called Hamachi. Could this be used in RTCW?
UDP is the fastest most "real time" standard IP protocol available. It literally just a packet being immediately sent to the recipient without any delay or other overhead at all. This is why, for example, VoIP (voice over IP) uses UDP.
One thing you definitely want to do, however, with UDP is to make certain that you have DIRECT links to your other gaming friends instead of needing to go through a third-party server.
If you don't know about "Hamachi" yet, you should definitely check it out. Gamers are LOVING it, since it works through their personal home NAT routers and lets them build very high performance networks to connect their machines as if they were all on a single LAN in one room -- but across the Net.
I did a Security Now! MP3 audio podcast talking all about Hamachi which you and your friends should definitely check out if you don't already know about Hamachi ...
http://www.grc.com/securityNow.htm#18
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (11)
.:Back to Top:. |
|
|
|
| Losers in RTCW Land |
| Posted on Tuesday, June 20, 2006 at 07:32:52 AM | gisele |
|
| |
Nope, I'm not talking about u5. Unfortunately, there is some pathetic soul in this community that may be worse than Silo.
Tonight around 1 am CST, people reported in #wolfpug that Hell's Gate had been hijacked. The hijacker renamed the server and apparently posted links to a certain website that I do not wish to name. He also messed with some server settings and pissed off alot of late night pubbers.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (30)
.:Back to Top:. |
|
|
|
| BoB3 Finals!!!!!! |
| Posted on Tuesday, June 13, 2006 at 08:57:29 PM | cD`V1X3N |
|
| |
We're finally here. It's been a long road and a lot of great matches. Along the way we've seen some terrific fights and lots of memorable moments.
Wednesday night at 10pm EST, we will have the final match of this epic tournament. west Side wolves faces Team Exodus on the Beach.
Last week saw wSw dominate affliction in the battle for mouse pads. Who will slaG bring to the match Wednesday?Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (32)
.:Back to Top:. |
|
|
|
| Quakecon Anyone? |
| Posted on Wednesday, June 7, 2006 at 02:04:37 AM | gisele |
|
| |
Well, well. Say it ain't so, but Alric (Executive Director) of Quakecon has this to say about Quakecon 2006:
QuakeCon 2006 is NOT cancelled
There have obviously been a number of rumors circulating recently, but this is to let everyone know that QuakeCon 2006 has NOT been cancelled. We've had a number of issues securing a venue and dates that suit the needs of the event, the attendees, and the staff.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (50)
.:Back to Top:. |
|
|
|
| Bob3: Elite 8 Results FINAL *UPDATED* |
| Posted on Thursday, June 1, 2006 at 06:30:39 AM | hollywood |
|
| |
EDITED.... Bob3 results *UPSET*
Map: mp_village
Affliction > Jolly rgr 3-1
wSw > Scourge 3-0
Exodus > Arise 3-0
teh birdz < united5 3-0
wow, who would have 'thunk' it ? United 5 got revenge Thursday night and won 3-0 on mp_village. Hold the phones!! more rtcw drama on the way. There could be some controversy because u5.alea did play in this match. TWL|Rob told wtv viewers that even if united 5 wins, the birds will still advance. Caffeine says, give them the win and let united5 move on to play exodus.
Next weeks matches:
Map: mp_assault
Affliction vs. wSw: TBA
Exodus vs. teh birdz / united 5: ?????
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (139)
.:Back to Top:. |
|
|
|
| Ties and the like |
| Posted on Wednesday, May 31, 2006 at 05:02:19 AM | a//shatter |
|
| |
So, we all (well, those of us with a clue) watched -a- and RGR last night.
Now, I will make no bones about it, I WANTED -a- to win only because donka was on the other team, but hey, that's me and my opinion.
That said, what do you all think of ties equalling a point per team? In a regular season match, I can understand (although not like it) it and go with it. But in a money tourney? Come on now. If two teams can stand each other up like that, then the round should be considered null and void? Right? Wrong? I'd like to hear what the community thinks. Ties are for Hockey and Football, not REAL sports like Baseball and Basketball. Never a tie, EVER. IMO. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (57)
.:Back to Top:. |
|
|
|
| Shoutcasting, bob3 show, ect |
| Posted on Monday, May 29, 2006 at 01:04:27 AM | -x-cKyAs$ |
|
| |
Hey guys well the last two shoutcasts i did i had a good 18 listeners, but i would like to have more.I am going to try my best this week to get in on all the big casts, looking foward to wsw vs scourge as well as affliction vs rgr. I would like to get inside both teams ventrillo's aswell if possible, but I was wondering if you guys would like a bob3 talk show, i can interview players, get peoples predictions, and give my own views on the community. Just wondering if any of you have any idea's... so reply to this and let me know. Thanks
link to my shoutcast is
http://69.123.67.8:8000/listen.pls" target="_blank">http://69.123.67.8:8000/listen.pls
If i am onair please idle in #team_exodus if you have to contact me, or would like to make a special guest appearance. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (48)
.:Back to Top:. |
|
|
|
| BoB 3 Great 8 Schedule |
| Posted on Monday, May 29, 2006 at 01:04:01 AM | icf|r0b`GG |
|
| |
After two weeks, we have arrived to the final 8 teams as they do battle on mp_village, an amazind doc running map. Who will make it to the final 4? Find out, starting Tuesday!
Below is the schedule:
Tuesday, May 30
10:00pm Affliction vs Jolly Roger
11:00pm West Side Wolves vs Scourge
Wednesday, May 31
10:00pm Exodus vs Arise
11:00pm The Birdz vs United 5
All Times are Eastern (EST)
All Matches available on WTV at 67.18.221.194:27970 |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (26)
.:Back to Top:. |
|
|
|
| Since it hasn't been said yet... |
| Posted on Friday, May 26, 2006 at 11:24:04 PM | gisele |
|
| |
We should all take this opportunity to pause the hate and thank all of those involved in making Bob3 so successul. Major props go out to all TWL staff, working their asses off for this, SnipeTX, DynosauR, id Software, iTG, Laws c/o HiDef, WTV and all major gaming news source outlets for spreading the word.
Also to Hollywood for being so persistent about making this really happen and getting players back.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (53)
.:Back to Top:. |
|
|
|
| BOB 3 Round Two Wrap Up!! |
| Posted on Thursday, May 25, 2006 at 05:35:14 PM | pissclams |
|
| |
With one match left to play tonight (Trinity vs. West Side Wolves) Round 2 of BOB III will come to a close and so far the tourney has been a resounding success. Of the 29 teams signed up, only one team forfeited -Transit's :o) TWL has done a awesome job of keeping this thing organized and the players have shown great sportsmanship throughout. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (178)
.:Back to Top:. |
|
|
|
| Policy Change |
| Posted on Thursday, May 25, 2006 at 03:33:08 PM | c[_]`Wippuh |
|
| |
While having a long standing policy against blatant personal attacks, there comes a time when the whining and crying of certain individuals warrants leniency. The current lone occupant of this list at Planet-RtCW.com is the one and only Invisible Man.
Planet-RtCW.com is now happy to add Donka to the above list! With posts both public and private, Donka has gone above and beyond to include himself on this distinguished list. Feel free to show Donka the love he certainly deserves.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (70)
.:Back to Top:. |
|
|
|
| BOB 3 Round 2 Begins Tonight |
| Posted on Tuesday, May 23, 2006 at 12:13:26 AM | pissclams |
|
| |
There are some great matches scheduled for tonight, Monday May 22, 2006.
Round 2 Bob III Schedule (All Times & Dates Subject To Change)
-------Monday Night BOB3 WTV Schedule-------
10:00pm Jolly Roger vs. Locked On Target
10:30pm West Side Wolves vs. Trinity
11:00pm Affliction vs. Unorthodox *time changed from earlier
#gtv on gamesurge
Radio ITG (http://www.radioitg.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (10)
.:Back to Top:. |
|
|
|
| RETURN OF THE 5v5 OSP LADDER! |
| Posted on Monday, May 22, 2006 at 07:32:55 PM | SyndicateGromit|TWL |
|
| |
It’s time: time to smoke pork butt in the backyard; time to get your pasty white butts outside for some sun; and time FOR THE RETURN OF A 5v5 OSP LADDER AT TEAMWARFARE! 16 teams were dispatched from the first round of BOB3 and 8 more are soon to follow. We’re several weeks away from the start of OSP Season 12 and even when it starts we’re going to need a 2nd competitive outlet for organized play. Sign up and challenge like it’s the Preakness Stakes [that is, aggressively and foolishly, knowing that many of you will splinter your right, rear ankle and spend the next 6 months hoping that you don't die before getting the chance to have sex in a grassy field (much like you all spent your first 19 years )]
Sign up now!
Format:
- 5v5 (although 6v6 is encouraged) with panzer
- Based on the OSP league config
- Each team selects one map with Defender selecting map order
Ladder Information:
http://www.teamwarfare.com/viewladderdetails.asp?ladder=RTCW+%2D+OSP+%2D+5v5
Rules:
http://www.teamwarfare.com/rules.asp?set=TWL+RtCW+OSP+5v5 |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (11)
.:Back to Top:. |
|
|
|
| Gamer Life: Klaudia 'ToxicGirl' Sroka |
| Posted on Sunday, May 21, 2006 at 09:25:53 PM | -doNka- |
|
| |
GGL.com started a new series of interviews called "Gamers Life." One of those interviews features ToxicGirl, a member of our community most people knew, or should have known.
...you are fairly famous in the ET/RtCW gaming community. How does that work?
...it was ]NARF[ (one of the top US RtCW clans back then) that I was asked to join, it followed with QuakeCon 2003 in Dallas and me being one of the GameTV admins of the event. Now I am still camming for WolfTV from time to time and I'm being a part of ClanBase Crew.
Interview at GGL.com (pics included) |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (10)
.:Back to Top:. |
|
|
|
| Australian RTCW One Night "Austourney" Cup |
| Posted on Friday, May 19, 2006 at 04:39:26 PM | mo*ringo |
|
| |
On Sunday May the 14th Australian RTCW clans got back together for a comeback to RTCW, in the first competition in the game in years. The teams lineup included past RTCW champions of Australia, Team dot and intel sponsored Team Immunity, it also included several team with highly rated Enemy Territory teams featured among these Quakecon participants Modus-Operandi. There were to be three rounds played, single elimination on base then ice and finally beach. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (15)
.:Back to Top:. |
|
|
|
| Karma |
| Posted on Wednesday, May 17, 2006 at 07:19:47 PM | c[_]`Wippuh |
|
| |
Arsenal's starting goal keeper, Lehmann, has been red carded and kicked out the ongoing UEFA champions league championship (thanks to comrade Yogi for correcting that) between Arsenal and Barcelona. This leaves Arsenal down a man and gives the offensive Barcelona a great advantage.
.:.Opio was unavailable for comment. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (75)
.:Back to Top:. |
|
|
|
| BoB3 Posts Galore |
| Posted on Monday, May 15, 2006 at 05:15:48 PM | c[_]`Wippuh |
|
| |
We've got lots of preview stuff for the upcoming BoB3 matches... Check them out!
Verrel Interview - The ET team comes to RtCW and expects nothing less than the finals. -a- in round 2 might have something to say about that.
Round 1 predictions - Crappy predictions by a crappy writer. Add your input and tell everyone what you think.
BoB3 overall predictions - The community chimes in with division favs, darkhorses, players to watch and much more. An ongoing article that will continute to grow as responses are sent back, be sure to check in often.
So far there's predictions from Zydoran, Wipp, s*00t, Mario, Slag, Militant, Holly and ckyass! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (7)
.:Back to Top:. |
|
|
|
| Top10 has been reset |
| Posted on Saturday, May 13, 2006 at 05:25:11 PM | pissclams |
|
| |
Results from last week's Top10:
Cal Main Top 10
1. Team Effect with 265 points and 13 number one votes
2. Team Exodus with 177 points and 1 number one vote
3. Splash My Nuts with 169 points and 9 number one votes
4. Trinity with 36 points
5. Team Inertia with 26 points and 1 number one vote
6. EggnogSquad with 22 points
7. Scourge with 20 points
8. We Happy Few with 14 points
9. Full Metal Jacket with 12 points
10. Hair Pullers with 11 points
Cal Open Top 1
TWL Alpha Top 1
1. Splash My Nuts with 1 point and 1 number one vote
TWL Beta Top 1
1. SerialKillers with 1 point and 1 number one vote
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (9)
.:Back to Top:. |
|
|
|
| BOB3 Information... Turn in your forums! |
| Posted on Friday, May 12, 2006 at 04:29:50 PM | hollywood |
|
| |
http://www.niteswine.net/twl_bob3_captain_form.html
NiteSwine|TWL v | | #
Don't know why so much attention is given to the team list for this tournament. It's nothing but an indicator. The only teams actually signed-up and approved for this tournament are the 12 that have submitted the captains form. Anyone can sign-up for the tournament; thus, the continual presence of asshats that join and have no association with RtCW. We'll keep removing them, but it's really pointless ... we'll simply add and remove teams once sign-ups are over so only the teams approved for play are on that list. And, at the moment, it looks like a fair number of teams with RtCW players are going to be removed ... fill in the form! Submit it! I'll post a follow-up with additional information.
Once again, here is the link: http://www.niteswine.net/twl_bob3_captain_form.html |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (32)
.:Back to Top:. |
|
|
|
| Bob III signups/roster locks end TONIGHT at 11:59 est! |
| Posted on Thursday, May 11, 2006 at 06:48:21 AM | hollywood |
|
| |
The signups were extended to Friday, May 12 at 11:59pm EST. At that time, the signups will close and rosters will lock. All teams have to be at a max of 8 players, with at least 6 to qualify.
The first matches start *THIS* Monday, May 15. Please check in at #twl_bob3 and ask an admin if you have any questions. I assuming the brackets will be up by Sunday night.
31 Teams signed up.
27 Teams are cleared to play.
4 Teams need players.
1 More team can sign up
Teams that need to fill their rosters:
-[x]-TremeSold!ers - -[x]- NEED 4
Ninja Pirate Badasses - -=NPB=- NEED 4
Team Necrotic - necrotic- NEED 3
squad ! up - uP NEED 1
Week 1 - May 15th-18th, 2006 - Map: Ice
Week 2 - May 22th-24th, 2006 - Map: Base
Divisional Finals - May 30rd-31st, 2006 - Map: Village
Tournament Semi-Finals - Wednesday, June 7th, 2006 - Map: Assault
Tournament Finals - Wednesday, June 14th, 2006 - Map: Beach (what else?)
#twl_bob3 & #wolfpug on irc.gamesurge.net |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (21)
.:Back to Top:. |
|
|
|
| More Quake Wars Info (hands on) |
| Posted on Wednesday, May 10, 2006 at 07:52:07 PM | v1k!ngISCG |
|
| |
http://www.gamespot.com/e3/e3story.html?sid=6149812&pid=928340
I'm not sure everyone will be able to view that link so here's some of it:
"One big draw is sure to be the vehicle interaction. It's nothing new to this kind of game, but the handling of the individual vehicles looks fairly authentic. If you're in a four-wheel drive you'll be able to climb steeper inclines and make it over rough ground, whereas if you're on a smaller ATV, you'll be able to traverse places unreachable by the larger vehicles. One particularly entertaining ride looks to be the helicopter-jet combo--though, create too much havoc and you'll no doubt become a priority target for the enemy."
- Source: Gamespot |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (15)
.:Back to Top:. |
|
|
|
| Busy monday at id Software |
| Posted on Monday, May 8, 2006 at 10:05:48 PM | hollywood |
|
| |
"Attention Quake III Arena, Return To Castle Wolfenstein and Wolfenstein: Enemy Territory users:
We have released updates to all three games to fix some security issues discovered following our release of the Quake III Arena source code under GPL.
You need to upgrade to the latest through the usual installers first, and then replace the engine binaries with the newer ones contained in the zip files below.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (31)
.:Back to Top:. |
|
|
|
| LFG? |
| Posted on Sunday, May 7, 2006 at 05:00:08 AM | gisele |
|
| |
I noticed there were quite a few people on pubs and in #wolfpug that are still clanless. Many teams are also looking for more players. I'd like to make this post and the following thread available for everyone who is still looking. If you are looking for a clan, please leave comments. If your team is looking for more players, leave a comment with your IRC channel so people can contact you.
Also, reminder: BOB3 rosters can only have EIGHT players. If you have more than that, TWL will contact you. So instead of benching, join/make a team.
Thanks everyone and please stop thinking you're all going to join Affliction, their roster is full. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (50)
.:Back to Top:. |
|
|
|
| Bob3 Turnout 5.8.06 @ 2:30 |
| Posted on Saturday, May 6, 2006 at 09:13:00 PM | hollywood |
|
| |
28/32 Teams signed up.
24 Teams are cleared to play.
ASC - ASC CLEARED
=FMJ=Clan E. - =FMJ= CLEARED
=The Awesome Ones= - =TAO= CLEARED
Arise - a// CLEARED
Blur.rtcw - /blur/ CLEARED
briphido - pewpew CLEARED
Chosen1s - c1 CLEARED
CloudNine - cloud9 CLEARED
Forgotten Kings - -King* CLEARED
High Voltage - HV NEED 2
Los Batos Locos - LBL CLEARED
Office Space - c[_] CLEARED
onslaught- - on- CLEARED
Saint| - Saint| CLEARED
scourge . gaming - s| CLEARED
Syndicate-Soldiers - -|SS|- CLEARED
Team Affliction.rtcw - -a- CLEARED
Team Necrotic - necrotic- NEED 4
Team Unorthodox - udX CLEARED
Team_Trinity - tTt NEED 1
Team>>Hostility - (!) NEED 1
Team-Exodus - -x- CLEARED
Teh Birdz - ..|., CLEARED
The Jolly RGR - RGR CLEARED
Tribal Valor - -Tv- CLEARED
United 5 - u5* CLEARED
West Side Wolves!!!!!! - wSw CLEARED
x Locked on Target x - )x( CLEARED
Looks like Team Necrotic need help filling their roster and we need four more teams.
http://www.teamwarfare.com/tournament/default.asp?tournament=Battle+on+the+Beach+III |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (29)
.:Back to Top:. |
|
|
|
| And The Braggin Rights Go To.... |
| Posted on Friday, May 5, 2006 at 04:03:12 AM | -doNka- |
|
| |
Today in a set of very intense games on mp_beach, 7+ season old Team Birds held a win against -1 season old u5 team coming straight from Enemy Territory.
The final score awards the win to The Birds 3-1-2, but who's got the bragging rights once the time was up? No doubt, U5 did an impressive job holding the new ground against the defending champions of RTCW. Once again caffeine got lucky having descent teammates backing his ass up after flaming et forums... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (157)
.:Back to Top:. |
|
|
|
| Enemy Territory: Quake Wars Interview #2 |
| Posted on Wednesday, May 3, 2006 at 04:10:53 PM | cK AnimeMan |
|
| |
I havent posted on here in years, but anyways, here is a little artcle that was posted yesterday on firing squad about ET:QW, it asks better questions about multi player aspects then the shackes interview from yesterday. Take a gander. FiringSquad: It's interesting that you chose to add vehicles in the game, since the original Wolfenstein: Enemy Territory was basically vehicle-free and came out as an excellent class-based infantry game. What were some of the risks vs. rewards you feel you took by adding vehicles to the Enemy Territory franchise? Was it a desire to satisfy player's demands that pushed the decision, or a genuine belief they'll make the game better?
Paul Wedgwood: We definitely believe our vehicles make ETQW better. Adding vehicles certainly has risks
You can read the rest of the interview here |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (18)
.:Back to Top:. |
|
|
|
| The Kolosok RTCW Pack |
| Posted on Tuesday, May 2, 2006 at 02:36:45 PM | KolosoK)nG( |
|
| |
I'm sure most of you don't remember who I (Kolosok) am. I was an original member of FuZioN's clan =Next Generation=, a member of the clans xcalibur (don't call hacks on me, 0.8 kill ratio ftw :P), Chao$ Krue, SiN, & the Forgotten Kings.
In the good old RTCW days, I have gotten into RTCW map editing. I've learned a lot through tutorials and was soon able to make full scale maps.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (10)
.:Back to Top:. |
|
|
|
| OH YEAH!!! |
| Posted on Monday, May 1, 2006 at 03:03:58 PM | c[_]`Wippuh |
|
| |
Battle on the Beach III presents
An unofficial preseason bragging rights match.
TWL's last 3 season Enemy Territory champs, United 5.et, will face TWL's last season rtcw champs, Teh Birdz, for an unofficial bragging rights match. This game will be held on Thursday 5/4/06 at 10:00pm est on the map, mp_beach. This game will provide a shoutcast by radio itg and wolftv for all you fans out there. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (163)
.:Back to Top:. |
|
|
|
| ETQW: Lead Designer Interview |
| Posted on Monday, May 1, 2006 at 02:22:39 PM | -doNka- |
|
| |
" Both id Software and Splash Damage are fans of Battlefield (and both companies are known for running Battlefield game servers for their staff and friends), but ETQW should be thought of as a different kind of game with different development and gameplay goals.
ETQW is fundamentally built with the goal of creating gameplay where teamwork makes a significant difference in whether or not you complete objectives. The game is also unique in pitting asymmetrical forces against one another; It’s no longer just a choice between two similar but differently-named machine guns: the choice of whether to play Strogg or GDF is significant, the strategies are different, and the experience is different.
ETQW’s builds on Wolf ET’s successful team play approach that has won millions of fans the world over, but is set a century after those World War II battles."
Read the entire inteview at Shackes
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (18)
.:Back to Top:. |
|
|
|
| A Movie That Will Make You Piss Your Pants! |
| Posted on Monday, May 1, 2006 at 02:21:56 PM | -doNka- |
|
| |
Most people love watching gaming movies. Most people here prefer watching RTCW related flix, and maybe ET and CS on occasion.
However, this time around I'd like to inform you that the best movie ever came out and it's dedicated solely to trickjumping. After this movie you will be sorry about 2 things:
1. You'll never make a movie that good
2. You've never been on a quake3 trickjumping team
Editing is simply amazing in all aspects and it includes the popular fly cam technology which makes FPS game look 10x better. Don't forget this game came out nearly 7 years ago :()
Enough talkin', original post here:
http://www.esreality.com/?a=post&id=1070515 |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (16)
.:Back to Top:. |
|
|
|
| Official Battle of The Beach III - Announcement On Tuesday, May 2 at 6pm EST!!! |
| Posted on Saturday, April 29, 2006 at 02:14:36 PM | icf|r0b`GG |
|
| |
Sorry to keep everyone in the dark for so long, but we appreciate the wait. Big news on the third installment of Battle of The Beach will be coming in just a few days. Most of your questions will be answered. Stay tuned to Planet-RTCW and IRC (#bob3) for more information.
Signups will begin on Wednesday, May 3. Come join old and new friends in some of the best competition that the RTCW Community has to offer.
The first 32 teams to sign up with all their information will be eligible for the tournament. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (71)
.:Back to Top:. |
|
|
|
| Australian RTCW gets a Revive!!! |
| Posted on Saturday, April 29, 2006 at 02:14:09 PM | mo*ringo |
|
| |
"The inaugural Austourney 6v6 RtCW Cup will take place on Sunday May 14, with round one matches scheduled to begin at 6pm AEST. Eight teams will compete in the knockout style competition, but there can only be one winner. A mix of ET players and old-school wolfers have signed up, including GameArena Season 3 RtCW champions team.dot and GameArena Season 3 Enemy Territory champions Modus Operandi. First round matches will be played on mp_base, while the semi-finals will take place on the chilly grounds of ice. The competition will conclude on the legendary and in many ways nostalgic map, mp_beach."
Add to that the entry of intel sponsored(and rtcw season 4 winners) Team Immunity And this cup looks to have as many if not more big name teams than aus wolf in its prime!
pro bracket at : http://img132.imageshack.us/my.php?image=brackets3xl.jpg
Hopefully wtv will be up and running for this one night cup, tune in to watch some highly entertaining games! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (7)
.:Back to Top:. |
|
|
|
| More and more nups pouring in… |
| Posted on Friday, April 28, 2006 at 11:59:16 PM | hollywood |
|
| |
SilentsTorm v | | # |HV is coming back.
Grimdeath, Vjay, Deftone, Silence, Xavier, Myself...should be fun
Only problem is we are having a hard time find a place to play..
u5., III, wSw, -a-, -x-, cloud9, scourge, The Birds (teammate), jollyrgr, -tv-, a//, now |HV!!! are the most noted teams that are back/new.
This asks a question..... Where is North America's favorite rtcw team, team]NARF[, during all this ?
Ask them yourselves :)
#narf on irc.gamesurge.net
[07:15:26p] * Query with obliv (user@cpe-67-49-9-45.socal.res.rr.com)
04.27.06 @ [07:15:52p est] me, beaverman, sp1ke, da_g, sephy so far
Who said RTCW was DEAD?
#wolfpug, #wolfscrim, #bob3 on irc.gamesurge.net |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (21)
.:Back to Top:. |
|
|
|
| FYI: Carpal Tunnel Syndrome |
| Posted on Wednesday, April 26, 2006 at 09:05:10 PM | -doNka- |
|
| |
This is not related specifically to RTCW, but to PC gaming in general. In his article over at GGL.com, Mahmood explains his research on Carpal Tunnel Syndrome. The disease can affect anyone who spends hours behind PC wiggling a mouse left and right.
Any seasoned Quake player will immediately see the problem with deviation. The circle-strafe jump, the basis for all skilled movement in Quake, is accomplished primarily through fast radial and ulnar deviation. These motions are repeated fifty to hundreds of times per game depending on the player. Perform these motions for 15 to 20 hours a week, for five years, and you have the dictionary definition of “repetitive stress injury.” That’s not even taking into account standard aiming and flick shots.
Playing With Pain
WARNING: The content of the article is not recommended to highly sensitive people. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (22)
.:Back to Top:. |
|
|
|
| The Nups Keep Pouring In |
| Posted on Tuesday, April 25, 2006 at 10:44:49 PM | c[_]`Wippuh |
|
| |
With the lazy afternoon sliding away in #wolfpug, you might have missed this tasty little tidbit...
join: (III-Busta)
(III-Busta): Empire is willing to play but we don't really have tons of time to devote to it ..more of a "relive old fun rtcw days"
(c[_]`Wippuh): busta, who would be playing?
(III-Busta): not sure yet ..only a few of us online right now ..Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (114)
.:Back to Top:. |
|
|
|
| Return to Castle Wolfenstein: Original Blackbox Edition $10.00 |
| Posted on Friday, April 21, 2006 at 10:50:15 PM | hollywood |
|
| |
http://www.idsoftware.com/store/index.php?view=wolfenstein
You no longer have to search ebay for your own copy of rtcw + a cd key!
It’s come to my attention that our friends at idsoftware are now selling rtcw again. Please order your copy ASAP if you’re interested in playing Battle on the Beach III. They are charging $7.50 for shipping ups ground and if ordered Monday should arrive no later then next Friday 4/28/06.
Please idle in #wolfpug on irc.gamesurge.net for more information about bob III and a list of new, old, and current players that are looking to put together a team.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (16)
.:Back to Top:. |
|
|
|
| RTCW 2006: New School vs. Old School |
| Posted on Thursday, April 20, 2006 at 03:47:43 AM | -Raze- |
|
| |
Return to Castle Wolfenstein has been deemed one of, if not the, greatest team based game ever made. We've seen 12 seasons of great teams come, and go. About a month ago, forum regular and RTCW faithful Wippuh suggested that we have a "draft" to rejuvinate the RTCW community, and hopefully bring some gamers back to the game that we all love. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (62)
.:Back to Top:. |
|
|
|
| Qcon Interview! |
| Posted on Monday, April 17, 2006 at 07:28:12 PM | c[_]`Wippuh |
|
| |
You wanted it so Holly went out and got it for you guys, an interview with Nate, "Director of Competitions" at Quakecon! The goal of this interview wasn't to pimp a certain game over another but to dig a little deeper and get an inside look at the workings of the event and hopefully provide some insight on how one can go about supporting their game. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (3)
.:Back to Top:. |
|
|
|
| Nate Wants Some! |
| Posted on Wednesday, April 12, 2006 at 05:29:32 PM | c[_]`Wippuh |
|
| |
Nate, director of Tournament Operations for Qcon, has agreed to an interview with Planet-RtCW.com. Being the community lovers that we are, it's time to collect some questions from all the nups out there in CommentsLand. So, post away on what you'd like to ask and then we'll put the trained monkies to double work picking out the ones to include in the interview. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (59)
.:Back to Top:. |
|
|
|
| Looking For Hackers In a Box of Crackers |
| Posted on Tuesday, April 11, 2006 at 01:25:04 AM | -doNka- |
|
| |
Here's a breif recap on on people that made headlines in hack5-0 reports:
Multitask
Link to Post
Well, multitask’s guid showed up on the MBL and instantly triggered many people’s attention. IP, however, was not linked directly to multitask, or no where near him. It’s pointing somewhere in Canada(surprise). Could multitask give out/lose his cekey to someone? Maybe. Could he hack simply of boredom? Possibly.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (79)
.:Back to Top:. |
|
|
|
| Pug League on downfall ? Rtcw needs your help! |
| Posted on Monday, April 10, 2006 at 07:48:07 PM | hollywood |
|
| |
Suggestions for the PUG League: *SUGGESTIONS ONLY*
Redo Pug League ?
- Re-pick the team
- Better, more reliable, Captains that know what is going on with the league and how things should be run. Experienced captains from previous CAL/TWL teams. People that know how to take charge and get shit done.
Match Night ?
- Is Sundays a bad time for a match night?Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (76)
.:Back to Top:. |
|
|
|
| New Server Coming Soon Friends |
| Posted on Sunday, April 9, 2006 at 01:42:45 AM | gisele |
|
| |
A new OSP server is currently in the works. The server is located in Dallas, TX. Before you bitch and moan, remember it is a pub and all you get for having the best ratio in a pub is the pub all-star award. So screw your 48 ping, just play.
The current map rotation will be Assault (1-round), Base, Beach, Ice, Frostbite, Chateau, Tundra Rush (1-round), Village, Sub.
Big shout-out to Skeeve|TWL for hooking this up, if you see him around be like "OMG SKEEVE I LOVE YOU, THANKS FOR THE SERVER!!111"
IP + More details in a few days when the server is up. It's called "The Lumber Yard OSP"
I need some feedback about bans. Do you think hackers should be banned right away or give them another chance? |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (28)
.:Back to Top:. |
|
|
|
| Remedy Facts. |
| Posted on Friday, April 7, 2006 at 03:00:33 PM | -doNka- |
|
| |
Inspired by Chuck Norris facts :()
Some newb tried to aimbot Remedy. He shot himself in the face.
Remedy doesn't just shoot ppl, he shoots their souls.
Nobody yet could count 4th bullet while dueling remedy.
Once remedy had too many headshots. OSP had to do a bell curve to the point when everyone was left with zero headshots.
As frogs don't see non-moving objects, remedy doesn't see non-helmeted objects.
If you defend base against remedy, you better figure out a way to blow your own radars.
Remedy doesn't cornercamp grave stones. Grave stones cornercamp remedy.
There are no corners while playing against remedy. There're places where walls end.
Aquaman sleeps in water. Remedy sleeps in inner compound.
Just like loch ness monster never leaves the lake, remedy does not leave inner compound.
Whoever thought remedy would not get any headshots on empty server... was wrong.
Every person who accused remedy of hacking is a hacker who couldnt outgun remedy.
Bullet better get a headshot when it's fired by remedy.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (50)
.:Back to Top:. |
|
|
|
| Calling Xbox Modders |
| Posted on Tuesday, April 4, 2006 at 08:22:56 PM | (7*up)LoXodonte |
|
| |
Seems I remember a few people round here have chipped or softmoded Xbox's. Just finished up tweaking a custom skin this week for unleashX. If anybody wants it go ahead and pm me on irc and I'll hook ya up. Contains a hidden RTCW movie teaser :p. Also, if you're wanting to softmod your xbox and need a bit of help, I could help ya out their too. You don't even need a chip these days, just a $10 used "action replay" or a friend with one. You can even dump in a larger hdd via softmod now. :) Once you're modded you can play games online without the xblive service, stream internet music w/visuals like winamp, stream videos/music/pictures from your pc, play burned xbox games (RTCW tides of war!), play homebrew games, play nes, snes, mame...etc etc etc.
I don't endorse all of the above tho...tbh.
http://i16.photobucket.com/albums/b10/LoXodonte/Xbox/Dash/Project-Maytrix-03.jpg |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (22)
.:Back to Top:. |
|
|
|
| News....Bad News. |
| Posted on Saturday, April 1, 2006 at 08:46:23 AM | -doNka- |
|
| |
It's been a shitty week for me so far, but at the end it just couldn't stop getting shittier. A buddy of mine, who likes to bash anything that isn't CSS linked me to a 4 days old article on GameSpot.com... so much to say, just read it yourself:
MESQUITE, Texas - Mar. 27, 2006 - Return to Castle Wolfenstein 2, the latest joint project of id Software and Raven Software promises to combine amazing Doom 3 technology and World War II-theme enhanced by supernatural resistance of the Third Reich. The singe player element of Return to Castle Wolfenstein 2, currently in development by Raven Software and executive produced by id SoftwareTM and Gray Matter Interactive, offers players an outstanding First Person Shooter quest on Xbox 360 and PS2 platforms.
"It just doesn’t get any better than the intense single-player and cooperative multiplayer action in Return to Castle Wolfenstein 2" said Todd Hollenshead, CEO, id Software. To the question about multiplayer mode Todd Hollenshead replied, "Id Software and Nerve Software had to part their ways due to inability of Nerve Software to align their goals with the scope of the project. As a result, the multiplayer side of the game will only feature cooperative multiplayer with maximum of four players."
Return to Castle Wolfenstein 2 is developed by Raven Software and is executive produced by id Software. The Xbox 360 game is a sequel to the award winning PC title, Return to Castle Wolfenstein: Tides of War, originally developed by Gray Matter Interactive studios and Nerve Software.
Some of the things are simply obvious, this isn' the first time you should be screaming that Id Software went cold heart commercial. They did it with Doom3, Quake4, and now... there isn't even a multiplayer competition mode!! Less obvious, or rather ambiguous message, or lack thereof, is that PC isn't even mentioned as a platform. Well, console titles bring big bucks nowadays with platforms like Xbox 360, PS2, and upcoming PS3. Full size multiplayer isn't as popular on consoles as it is on PCs. So if you guys wanna play some RTCW2 co-op, you might wanna trade your new video card for an xbox, and co0l wireless controls.
GG kids, been fun.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (32)
.:Back to Top:. |
|
|
|
| WolfPUG update (the whole deal on this incredibly changing thing) |
| Posted on Saturday, March 25, 2006 at 04:45:58 AM | cD`V1X3N |
|
| |
There are 8 captains total. The final captain will be chosen by Saturday morning. Teams will be chosen Saturday. The pick order has been decided.
Our first match is to be Sunday, March 26th at 10pm Est on Village!!!
Thank you so much to everyone for participating. I really have been surprised at the impressive amount of players that have signed up.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (19)
.:Back to Top:. |
|
|
|
| Wolf PuGz Captains Chosen: Draft to take place Sunday March 26th |
| Posted on Thursday, March 23, 2006 at 11:20:25 PM | -Raze- |
|
| |
The captains have been selected for the upcoming "Pug" style tournament for RTCW. Last Sunday: Mutha, Donka, Newton, Vid, and Digital were all selected as the captains for this event. As of now (4:30EST, Wed March 22nd) there are 35 players within the player pool. Each team appears to be consisting of 7 players.
Please visit www.wolfplayer.us to check out the list of players and any other changes.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (60)
.:Back to Top:. |
|
|
|
| id Software's History of Community Support |
| Posted on Thursday, March 23, 2006 at 11:20:10 PM | gisele |
|
| |
Just found this on PlanetQuake4; thought it was interesting...figured you guys might as well.
id Software's History of Community Support
by RogeR
With the recent release of Quake4, id Software has come under fire by the community for releasing a game that contained a problem ridden multiplayer component. Only a month or so after the game was released, unhappy members of the Quake community wrote articles announcing death of Quake4.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (7)
.:Back to Top:. |
|
|
|
| Sign up for the PUGs |
| Posted on Wednesday, March 15, 2006 at 03:18:59 PM | cD`V1X3N |
|
| |
The Pick Up Games will be informal matches. The format will be relatively what Wippuh suggested. Sign up on this thread to play, and Captains will be picked next week. Those captains will then pick their teams. Pick order will be determined by a random order mechanism. Each Captain's pick selections will be saved (and posted) so that teams can select stand-ins in case a player isn't available for the match. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (159)
.:Back to Top:. |
|
|
|
| Finals on the Beach!!! |
| Posted on Saturday, March 4, 2006 at 02:35:37 AM | cD`V1X3N |
|
| |
We're finally to the finals. Given the trials and tribulations of this season, I'm definately looking forward to this one!
For the home team, we have Teh Birdz, who took down Syndicate Soldiers 3-1 on Ice to get here. Some amazing shooting going on, as well as some fine teamwork. Well done, Birdz. Props to caffeine for...something...I'm sure he did something well in the match. ;)
The visiting team is Jolly RGR.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (118)
.:Back to Top:. |
|
|
|
| syndicate soldiers clearly frightened of public humiliation |
| Posted on Friday, March 3, 2006 at 03:58:18 AM | Mauler [c0ff] |
|
| |
9:30 PM EST, Syndicate Soldiers point out to vixen that they will not be allowing shoutcasting in the twl rtcw semi final match this evening. though twl rules state "In the event a server is not specified by TWL RtCW Administration, any team participating in either a division final or league final match must make available spectator slots for shoutcasting providers, including iTG, TsN and WTV." - however TWL does not actually enforce this rule. this would be the third matchup between the two teams this season and the public seemed interested, we had 12 listeners.
unfortunately, SS got cold feet and backed out after confirming shoutcasting at 9 PM EST. we're attempting to move over to Tribal Valor and Jolly RGR at this time. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (91)
.:Back to Top:. |
|
|
|
| Clean, dry, was my body and hair - I threw on my brand new Fatal1ty underwear... |
| Posted on Thursday, March 2, 2006 at 11:46:13 PM | gisele |
|
| |
Snoop Dogg and the Global Gaming League announced today (March 2) the formation of the Hip-Hop Gaming League, GGL's newest online video game community where MCs and international gaming champions compete and showcase their skills.
Snoop will serve as the league's first commissioner, ensuring that all matches played online via Xbox Live for the Xbox 360 are fair.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (46)
.:Back to Top:. |
|
|
|
| Attention RTCW Community!!! |
| Posted on Sunday, February 26, 2006 at 07:15:56 PM | :+:VirUs047` |
|
| |
STA-RTCW is actively searching for teams to participate in a small, yet competitive RTCW Shrub league!
The leagues matches would be held on Tuesday nights, and more details will be released pending interest in such a league is out there. Currently we have three teams that have given us their approval and are willing to participate in such a league.
STA-RTCW currently wants three more teams before we will move on opening the league for sign-ups and begin actual league play. We believe this is an important effort to keep competitive RTCW around in any form, as we wait for RTCW2’s release.
If your team is interested, please contact Gotcha or Virus047 on IRC or visit the following thread on the STA-RTCW Forums!
STA-RTCW Shrub Interest Thread: Click Here!
Thank you! GL HF!
#sta-rtcw @ irc.gamesurge.net
http://shrub.sta-league.org/
-STA-RTCW Shrub Admin Staff |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (34)
.:Back to Top:. |
|
|
|
| Season 11 Playoff Picture |
| Posted on Thursday, February 16, 2006 at 06:09:12 PM | c[_]`Wippuh |
|
| |
With Season 11's regular season over, the current standings look like...
1. Teh Birdz 16 points 5-1
2. The Jolly RGR 14 points 4-2 (+10)
3. Syndicate-Soldiers 14 points 4-2 (+5)
4. Tribal Valor 14 points 4-2 (+2)
5. Chosen1s 12 points 3-3
6. -Colorblind- 10 points 3-1
***cut off point for playoffs***
7. Collateral Damage 10 points 2-4 (head to head win over ASC)
8.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (74)
.:Back to Top:. |
|
|
|
| TWL-Alpha OSP Week 6 - Assault |
| Posted on Monday, February 13, 2006 at 11:49:19 PM | c[_]`Wippuh |
|
| |
With Juventus, the most dominant sniper left in wolf, not playing this season, things are looking WIDE OPEN! Do it, do it!
-Colorblind- vs Random much?!
Syndicate-Soldiers vs Collateral Damage
Rampage, animal, DingDong, nosferatu, caffeine, iggy88, goose, Mesh, pimpplaya, SonicReducer and Spuddy vs Chosen1s
The Jolly RGR vs {NoX}Senate
Problems Valor vs Squad Bravo |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (111)
.:Back to Top:. |
|
|
|
| [N4L] Shrub Pub Rotation is up and running. |
| Posted on Tuesday, February 7, 2006 at 07:41:36 PM | DynoSauR |
|
| |
In an effort to give the competitive Shrub players a place to play I have got up a Shrub server with rotation. It has most of the TWL comp settings but, I did update to the newest version of Shrub so that there would be full stats in the console and also hitsounds among a few other minor differences. I think the main reason TWL does not use the newer version is because of the ability to do the "shrub jump" with the newer version. At any rate, the server is located in Dallas and it has almost the same map rotation as Hell's Gate minus mp_rocket which I put mp_beach2e in it's place. Once again this server was graciously provided by NGWaves of www.f3dz.com. I am not going to be strict about names on this server since a lot of shrubbers out there have never competed but, I will continue to try to keep the hackers off. If you have any suggestions or questions about the servers then feel free to drop by www.wolfplayer.us and post at the forums.
67.18.221.196:31000 |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (9)
.:Back to Top:. |
|
|
|
| PUG Bot and IRC channel |
| Posted on Wednesday, February 1, 2006 at 01:44:08 AM | Defend.Blank |
|
| |
I recently have started a new project a pug bot to help the community organize pugs more easily. The channel is #rtcwpug on gamesurge. So far the commands that are available are as follows..
@join – Join the pug once 12 people are joined it will auto shuffle teams
@players – See what players have joined along with team assignment
@vent – set and view vent info for the current pug
@leave – Leave the pug
@newpug – Start a new pug clears out server choice and pug roster along with setting the server to be used
@shuffle – shuffles team assignment
@status – shows the status of servers available for pug
@help – shows cmds, examples, descriptions
@server – shows or sets the server for the pug match
@start – starts the pug by changing the selected server to the correct mod and cfg settings
Available Servers
--TX1-- IP:207.210.236.36:27960
--TX2-- IP:66.151.255.154:27960
--CHI3-- IP:66.151.31.14:27960
--CHI4-- IP:66.151.31.54:27960
Any comments, questions, problems msg me on the channel
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| ET:QW Looks Better With Every Review! |
| Posted on Tuesday, January 31, 2006 at 01:21:04 AM | -doNka- |
|
| |
There's new review of ET:QW over at planetquak4.com. It covers some of the player class details and other pretty exciting features, check it out:
He(field ops) carries a machine pistol and can deploy a variety of artillery such as Field Gun Artillery, Rocket Artillery, Strategic Strike Missile and Air-Strike Uplink. These can be controlled by laser painting enemy targets...
...Splash Damage has been able to integrate some very intriguing things.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (43)
.:Back to Top:. |
|
|
|
| OSP Week 4 - Ice |
| Posted on Saturday, January 28, 2006 at 01:38:14 AM | cD`V1X3N |
|
| |
Another cold week puts us on Ice. Another gib-fest flag-grabbin hallway-ownin massacree in the snow! Matches for this week are:
Teh Birdz (3-0) V Random much?!(The FNG's)
Jolly RGR (2-1) V Colorblind (2-0)
Tribal Valor (2-1) V Syndicate Soldiers (2-1)
{NoX} (1-2) V Chosen1s (1-2)
Collateral Damage (1-2) V Wolf Players (1-1)
ASC Squad Bravo gets the bye this week.
Good luck to all!!!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (58)
.:Back to Top:. |
|
|
|
| A Lot More Details On ET:QW |
| Posted on Monday, January 23, 2006 at 12:14:51 AM | -doNka- |
|
| |
ComputerAndVideogames.com conducted an interview with a lead designer at Splash Damage - Paul Wedgwood. Some new info can be found in this 4-page interview + screenshots.
Wolfenstein had about 11,000 QA hours at Activision to balance the game and make it work. With Quake Wars we're probably going to have to use the same kind of heuristic evaluation method...
There're also some insights on vehicles, XP, and other features.
READ IT HERE |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (35)
.:Back to Top:. |
|
|
|
| Shrub Season #4 Week 3 |
| Posted on Saturday, January 21, 2006 at 04:21:30 PM | bull-z-@ |
|
| |
This week everyone will put their pub skills to the test... Lathering up the sunscreen on mp_beach will be...
Chosen1s vs Super Soldiers Inc.
Devil Stomper Battalion vs Syndicate-Soldiers
Noobs 4 Life vs We Happy Few
Mongoloids vs Invite Only
Due to the departure of ex0t1c, ASC will have a bye this week.
-=SS=Leafie |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (16)
.:Back to Top:. |
|
|
|
| TWL OSP Week 3 - Chateau |
| Posted on Friday, January 20, 2006 at 05:51:59 PM | cD`V1X3N |
|
| |
Week 3 of OSP competition brings us the lovely Chateau with it's fine shootable pottery and wonderful flag-grab gib-fest. Here's the matchups for this week:
Wolf Players (0-2) vs {NoX} (1-1)
Collateral Damage (0-2) vs Squad Bravo (0-2)
Syndicate-Soldiers (1-1) vs Chosen1s (1-1)
Tribal Valor (1-1) vs The Jolly RGR (2-0)
Teh Birdz (2-0) vs Colorblind (2-0)
Good luck to all!!! Let the predictions roll.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (150)
.:Back to Top:. |
|
|
|
| TWL OSP Week 2 Schedule |
| Posted on Saturday, January 14, 2006 at 02:18:29 PM | pissclams |
|
| |

TWL's second week of Season 11 OSP schedule has been released, this week looks like some good match ups on mp_submarine.
-Colorblind- vs. ASC Squad Bravo
{NoX}Team vs. Collateral Damage
Chosen1s vs. Tribal Valor
Syndicate-Soldiers vs. The Jolly RGR
Teh Birdz vs. Wolf Players
Props to TWL for a quick schedule, let's get some WTV coverage this week!
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (165)
.:Back to Top:. |
|
|
|
| TWL OSP Week 1 Results |
| Posted on Thursday, January 12, 2006 at 06:30:06 PM | pissclams |
|
| |
TWL OSP League Week 1 Results - Mp_village
Squad Bravo vs. Teh Birdz (0-3)
{NoX}Team vs. Syndicate-Soldiers (1-3)
Chosen1s vs.Wolf Players vs. TWL (WP Forfeit?)
The Jolly RGR vs. Collateral Damage (3-0)
Tribal Valor vs. -Colorblind- (2-3)
Looks like their was some e-drama involved with the WP vs C1 match, imagine that! Hopefully they get it worked out.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (150)
.:Back to Top:. |
|
|
|
| Season 11 Knowledge From Those In the Know! |
| Posted on Wednesday, January 11, 2006 at 03:50:12 PM | c[_]`Wippuh |
|
| |
Tonight's the night! Season 11 of TWL fires up and it's time for some early season predictions! With the crack staff of trained monkies here at planet-rtcw.com, we went far and wide to gather some thoughts on the upcoming season. The only thing that seemingly everyone could agree on was that no one would approach the faggotry of teh birdz this season. Not much of a surprise there! Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (81)
.:Back to Top:. |
|
|
|
| Attention Nerds- AMD Releases FX-60 cpu |
| Posted on Tuesday, January 10, 2006 at 08:11:17 PM | pissclams |
|
| |
Today AMD released the latest addition to their FX family of processors, the FX-60 cpu. The FX-60 is AMD's final Socket 939 release; going forward all new chips they release will support the AM2 socket, which will add DDR2 support to the AMD processors; expectations are that the AM2's will ship late 1Q06 or early 2Q06.
Starting with the FX-60, the FX line will now be a dual core cpu.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (47)
.:Back to Top:. |
|
|
|
| A Host of Updates! |
| Posted on Tuesday, January 10, 2006 at 03:46:06 PM | :+:VirUs047` |
|
| |
We have a few updates on planet-rtcw.com that I would like to make note of if they haven't already been posted someplace. Including: Interviews, Predictions and STA News!
New Interview
There has been a host of new interviews recently. Most recent is Mesh from the Birds! The recently posted Interview of: Mesh from Teh Birdz is up on the Articles section of the planet-rtcw.com webby.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| 60 Minutes Broadcast Date Announced |
| Posted on Monday, January 9, 2006 at 04:20:46 PM | bull-z-@ |
|
| |
Producers for 60 Minutes have informed the CPL that the segment about Johnathan "Fatal1ty" Wendel and the CPL, originally scheduled for Sunday, December 11, 2005 will be rescheduled to January 22, 2006.
The story, presented by 60 Minutes correspondent Steve Kroft, will include coverage from the Dallas CPL Winter Event and the World Tour Grand Finals in Times Square, New York City.
Any single episode of 60 Minutes attracts a bigger journalism audience than any other journalism outlet in the United States, between 12 to 18 million people.
-caleague.com
fire up the tivo and jack it to online pics of whoever you try to pass off to be your girlfriends. put in a pizza, take a shit, its emmy time. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (8)
.:Back to Top:. |
|
|
|
| playertracker returns |
| Posted on Monday, January 9, 2006 at 01:22:22 AM | lacerate |
|
| |
Well I usually dont do this type of thing so dont expect pro questions but seeing the the lack of news on planet-rtcw
asides from whos hackin threads or frog maps, theres nothing really interesting to read. Well Rtcw was my favorite game
and seeing rtcw2 is still a ways off, im hoping that this site can stay up till then. Which brings us to the present situation...Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (12)
.:Back to Top:. |
|
|
|
| The God of FPS Has Spoken |
| Posted on Sunday, January 8, 2006 at 12:05:10 AM | -doNka- |
|
| |
John Cramack, that guy who always makes you want to buy a new video card, has given two interviews recently. None of the interviews are really worth reading, but there are two moments that I'd like to bring to your attention:
One out of four October news posts about RTCW2 mentioned that ID and Raven are working on RTCW2.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (9)
.:Back to Top:. |
|
|
|
| Do you want Remedy on Hell's Gate? |
| Posted on Sunday, January 8, 2006 at 12:04:56 AM | DynoSauR |
|
| |
I have been receiving quite a few complaints about Remedy's ownage on Hell's Gate and inquiries as to why I have not banned him already. That is why I'm posting here and now. This is a simple question to you players who still play OSP. Do you want to have Remedy on Hell's Gate or not? A lot of discussion is not necessary. I do wish this site had a poll but, a simple yes or no vote will suffice here. Thanks |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (107)
.:Back to Top:. |
|
|
|
| Happy New Years! |
| Posted on Sunday, January 1, 2006 at 10:47:17 PM | -Raze- |
|
| |
Despite all of the drama and e-rage that we show one another, I figured it would be proper to wish all of you a happy new years. This is one of the only times of year when its completely acceptable to get drunks and have sex with a random person. Its also a time when we look back at where we've been, and attempt to fathom where we are headed. A lot of us know each other from the many years of gaming we've spent with one another. A few don't know, and a lot just enjoy hating on each other. But, for one day, i hope to cast aside the hate, e-rage, and all the other bullshit that I, along with many others enjoy stirring up.
From my house to yours, have a Happy New Years and please be safe. Regardless of whom we dislike, none of us wish death or an unfortunate incident. I hope that you all make a solid resolution and stick to it. So, I raise my e-glass and toast to each of you, my fellow wolfers.
See ya in 2006 and again, please be safe.
Ryan Raze |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (30)
.:Back to Top:. |
|
|
|
| Teamwarfare League RtCW OSP season 11 Open for signups!!! |
| Posted on Tuesday, December 13, 2005 at 07:32:06 PM | cD`V1X3N |
|
| |
RtCW Season #11 of OSP competition is open for signups. This season we start January 4, 2006 with one week of pre-season competition. The pre-season matches will be held on a new custom map designed by a fellow Wolfer! The map will be available in the week before January first. Keep your eyes on the news for download links! This should add a new level of excitement for the season. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (53)
.:Back to Top:. |
|
|
|
| TWL PBSS Updates! |
| Posted on Saturday, December 10, 2005 at 07:08:57 PM | cD`V1X3N |
|
| |
There's been some controversy regarding PB screenshots. Just so everyone understands the Teamwarfare League Policy:
-PB Screenshots are a very important tool for RtCW server admins.
-PB SS will be a required part of the TWL match.cfg for match servers starting with OSP season 11.
-Players that return the same picture more than 3 shots in a row will be suspended for 1 month (4 matches).Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (21)
.:Back to Top:. |
|
|
|
| Do you miss intense OSP teamwork on a Pub? |
| Posted on Friday, December 2, 2005 at 05:48:25 PM | DynoSauR |
|
| |
The Hell's Gate by F3dz 20 slot OSP server is up and running @ 67.18.221.194:30000 It's got a good rotation of all the popular maps and it's recently been drawing in some quality players from the old and not so old days. Everybody from Alpha to Opz is playing right now. So come on by and relive why OSP competition was the best there ever was. Also, if you have any map recommendations that are not already in the rotation then let me know. Right now Rocket is in the rotation but, it's often getting voted past so think up a good map to replace it.
PS. If you've been caught hacking any game within the past year don't bother trying to connect. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (143)
.:Back to Top:. |
|
|
|
| Frostbite Tribute Movie by doNks |
| Posted on Wednesday, November 30, 2005 at 11:13:16 PM | -doNka- |
|
| |
I'm glad to present a movie that I've made as a tribute to the game we've all play/ed for years. When I got the idea of making a movie I didn't want it to be the greatest video where one aliased guy gets 2-man corner camps on a pub and all that crap. I wanted to reflect the feeling of wolf that comes from the team play value of the game. This movie is a demonstration/overview of the gameplay on only one map te_frostbite. Only match competition footage was used to cover the aspects of the map objectives, offense and defense side-by-side.
Get the movie from filefront and another mirror.
Matches:
eurostandard vs DSA
Kinetic vs dT Cal-5
Kinetic vs CCCP TWL-3
Saint(CE) vs Scourge CAL-7
Tribal valor vs FMJ TWL-10
*CE = Cowboy Edition |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (47)
.:Back to Top:. |
|
|
|
| Ev1L = TWL Lead Anti-Cheat admin quits. |
| Posted on Tuesday, November 29, 2005 at 05:40:30 AM | DynoSauR |
|
| |
Ever since Ev1L joined TWL he has met with much resistance. He not only did his job beyond the call of duty as ET Lead Anti-Cheat admin but, he also spent much time catching RTCW hackers since he loved both games. WHen he first joined TWL he ended up going through a ton of RTCW server log files and uncovered many hackers who had never been turned in to TWL. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (124)
.:Back to Top:. |
|
|
|
| [DP]Dracus Passed Away |
| Posted on Monday, November 28, 2005 at 01:34:52 AM | :+:VirUs047` |
|
| |
November 17th, 2005, this community lost an outstanding member and long time friend to many. [DP]Dracus from Dead Presidents has passed away due to heart failure. Nothing more is known at this time, but Lloyd Roberts (Dracus) leaves behind a huge legacy of friendship and sportsmanship to his name. He will be missed by all who knew him! I’m happy to have played with him this past season in Collateral Damage. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (18)
.:Back to Top:. |
|
|
|
| More ... New TeamWarfare Administrators Announced |
| Posted on Friday, November 25, 2005 at 08:41:17 PM | NiteSwine|TWL |
|
| |
TeamWarfare RtCW wishes to announce three more new admins the the Return to Castle Wolfenstein community. NoName joins up as a technical staff member. His main focuses will be continued development and implimentation of WolfTV and Shoutcasting (along with some new concepts), TWL RtCW game server management, TWL RtCW config and support files managment, and we'll even let him participate, too, in helping out run competition. Many of you know NoName very well. He's definitely been in the community a long time, and many of us have already benefited by his involvement in keeping this game and organized competition alive.!MALABER also joins the competition staff. He'll be much involved in the OSP League, which we expect to have some announcements on very soon. !MALABER's got some ideas for some mini-tourneys and some alternative competition concepts. He'll be presenting some of those to the community in hopes of putting together some short-term tournaments. He's got good experience leading his clan and is well-known by many of you.Gromit also joins the TWL RtCW administrative team as a competition staff member. He's a straight-shooter, knows how to handle contentious issues, and has a lot of experience and knowledge that will benefit both the community and the TWL RtCW admin team. He comes from a good group of serious and classy players and is very well known in many pub groups.It's a pleasure to welcome each of these gents to the TeamWarfare RtCW administrative team. I hope you'll do the same (before this thread goes in some bizarre tangent). This announcement does not necessarily round-out our new administrative team member announcements. We're still looking at a few other excellent candidates. In restructuring and adding new members, it's our intent to continue providing the best possible competition experience available to the RtCW community. Happy Holidays! NiteSwine, TeamWarfare RtCW Competition Manager |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (50)
.:Back to Top:. |
|
|
|
| New TeamWarfare Administrator Announced |
| Posted on Friday, November 18, 2005 at 08:25:58 PM | NiteSwine|TWL |
|
| |
TeamWarfare RtCW will be adding a number of new admins over the next few weeks. The intent is to provide a greater mix of representation from the community and lend more support to the offerings of TWL RtCW.
Stronger Than All has requested coordination with the next Shrub league, and we see nothing but benefits for the community. To that end, I've expedited the first admin selection, who is ...
Leafie of Syndicate-Soldiers
Many of us know that Leafie's been around since beta. He's also been instrumental in the development and management of the BeetleJz Los game servers for many years. His involvement and success with -|SS|- is no small accomplishment, either. He's a level-headed sort, dedicated to the RtCW community, and has a great deal of OSP and Shrub experience.
It's my pleasure to welcome him first to the admin team, and its my expectation that he'll do his best to earn your appreciation in his new role as a TWL RtCW administrator.
NiteSwine, TeamWarfare RtCW Competition Manager |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (50)
.:Back to Top:. |
|
|
|
| Video Killed the Radio Star |
| Posted on Wednesday, November 16, 2005 at 03:41:56 AM | gisele |
|
| |
With all the new games coming out, the need for a decent PC is becoming a crucial part of playing the new games. We all know that not everyone is a Fatal1ty-born prodigy gamer, and some gamers attribute all their skill to their super leet PC's.
So my questions for you all are: What video card are you currently using? How well does it run the Doom 3 engine?Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (153)
.:Back to Top:. |
|
|
|
| Shrub vs OSP in TWL |
| Posted on Monday, November 14, 2005 at 03:38:56 PM | c[_]`Wippuh |
|
| |
The TWL Shrub season champs are going to face off vs the TWL OSP season champs in a massive slugfest! This will pit the smack talking [x] vs the current buzzard holding TV, for all the marbles!
This Thursday at 10est
1st 2 rounds, shrub mod on [x]'s choice of map
2nd 2 rounds, osp mod on TV's choice of map
Tiebreaker, shrub mod on TV's choice of map!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (45)
.:Back to Top:. |
|
|
|
| STA-RTCW Shrub LL - Preseason Week #1 Schedule! |
| Posted on Sunday, November 13, 2005 at 11:57:06 PM | :+:VirUs047` |
|
| |
The First Week of the Preseason's Schedule has been released!
Map: Assault
Date: 11/13/05
Default Time: 9:30 PM EST
-|SS|- vs. ..I.,
Tn4 vs. -0v-
vs. _c1
You can find the complete schedule here: http://shrub.sta-league.org/schedule
We have plenty of great looking match ups on Assault this week. So get your mauser dusted off and sharpen that knife, because the preseason is kicking off! Best of luck to all teams this coming season. We look forward to a wonderful season, and of course having lots of fun. GL HF!
Reminder to all team captains: Check the Captains Forums for Match Coms with your scheduled opponent. Any questions or concerns, contact an admin! Thanks!
-STA-RTCW Shrub Admin Staff |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (28)
.:Back to Top:. |
|
|
|
| Logs proving sage and Lucky-B hack. |
| Posted on Friday, November 4, 2005 at 09:34:12 PM | logro||er |
|
| |
I was going through my computer irc logs looking at some old readings. Come to my surprise i found a log of sage and lucky-b sharing hacks in the flatline channel, late one night. This log should be all that is need to ban both lucky-b and sage for-ever. It has links to hack sites, and twl admins moms phone numbers. Now this could be sages step cousins moms brother. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (47)
.:Back to Top:. |
|
|
|
| TWL Semi Final Match Results (Part 2) |
| Posted on Thursday, November 3, 2005 at 04:12:48 PM | pissclams |
|
| |
As many of you are aware, last week Team Exodus was forced to forfeit all of their wins in the TWL playoffs because of the incident involving LuckyB. The result of that happening is that TWL scheduled a rematch of that side of their playoff bracket's Semi Final game, putting Mongoloids (insert original name here) vs. Defense 4 (da' Birds w/ Rampage) last night, on te_ufo. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (84)
.:Back to Top:. |
|
|
|
| TWL RtCW Seeks Admin Candidates |
| Posted on Thursday, November 3, 2005 at 02:47:07 PM | NiteSwine|TWL |
|
| |
TeamWarfare: Return to Castle Wolfenstein is screening candidates for several administrative positions. Despite much of the grief, which tends to be a focus of much discussion on this site, there are a great number of players in this community who want this game to continue being supported for organized competition. If you're one of those people and the level-headed sort, you just might be what we're looking for. For more information, please visit this link. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (34)
.:Back to Top:. |
|
|
|
| The Summer of 2006: RTCW 2 Returns |
| Posted on Tuesday, November 1, 2005 at 03:45:03 PM | -Raze- |
|
| |
While the announce date has not been solidified, it has been written that Return to Castle Wolfenstein will be making its second run for the PC. It is widely believed that this version will bring back most of the teams who helped establish Return To Castle Wolfenstein as the best multiplayer team based game to date.
Basically, I'm wondering if we will see the return of some of the top North American clans to the competitive gaming scene.
I'm talking WSW, NARF, FX, -a-, WS, dr, EMPIRE, Darkside, Amish, 82nd, Uprise, LoT, HV, LoT, and the assortment of others.
What teams do you expect to see back for the new revolution of RTCW? |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (217)
.:Back to Top:. |
|
|
|
| STA Announces their |
| Posted on Sunday, October 30, 2005 at 05:48:23 PM | Gotcha! |
|
| |
STA is now accepting registrations for their next season of RTCW Shrub competition. Named as the "Season of Giving", this competition will consist of the typical 2 Pre-Season, 8 Regular Season, Playoff Finals format… but with a twist. Based upon an idea presented and encouraged by Clan Syndicate-Soldiers (-|SS|-), STA-RTCW Shrub's Season #1 Champs, this season's winning clan will have more to take pride in beyond the coveted Championship crown. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (18)
.:Back to Top:. |
|
|
|
| Final Four |
| Posted on Thursday, October 20, 2005 at 06:35:11 PM | *c0ff1 |
|
| |
the final four has been set for season 10!
-x- vs d4
damage/ vs -tv-
predictions? rants? everyone wanna say damage doesn't belong? hehe... looks like there were some good matches on assault last week. exodu$ showed up very strong against a solid mongoloids team and dominated for a 3-0 victory. -tv- and d4 won their matches in similar fashion. damage worked really hard to defeat a well prepared buzzurds team...Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (48)
.:Back to Top:. |
|
|
|
| Rtcw 2 is coming! |
| Posted on Sunday, October 16, 2005 at 12:25:11 AM | digital |
|
| |
Religion and Faith
Harry KnoxYom Kippur begins this year on October 12 at sunset and continues through nightfall, October 13th. The word literally means Day of Atonement and is the most solemn and sacred holiday of the Jewish year.
Rabbi Denise L. Eger has graciously written a sermon, Turning Toward Holiness and Strength for HRC in honor of this most holy of days. Rabbi Eger is a long-time activist and spiritual leader for the LGBT community. She is the founding Rabbi of Congregation Kol Ami in West Hollywood, Calif. She is also Vice-President of the Southern California Board of Rabbis and steering committee member of California Faith for Equality.
Rabbi Eger writes that “[w]hen the LGBT community comes together in strength and solidarity we do change the world. We enrich it with our vision of our world where men and women are truly equal. We enrich it with our commitment to equality and justice. We enrich our world with our commitment to honor all of our families! Indeed, we are choosing life.”
I hope you find this sermon as inspiring as I did and may Yom Kippur be introspective and life affirming.
With hopes for a blessed year,
Harry
Harry Knox
Director, Religion and Faith Program |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (70)
.:Back to Top:. |
|
|
|
| TWL Playoffs Round 1 Tundra Rush |
| Posted on Thursday, October 13, 2005 at 02:23:35 PM | Senatorrov? |
|
| |
Week 1 of TWL playoffs was held tonight
(5) NoX > (12) B|ASC (3-0)
(6) FMJ < (11) -|SS|- (0-3)
(7) cD/ > (10) [DSB]
(8) ]WqC[ < (9) m//
Scores arent listed in match results, so i dont know what the score of cd-dsb and wqc-m are. someone post them if they know.
Week 2 of playoffs is on Assault. MOTW will be shoutcasted on Radio ITG.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (48)
.:Back to Top:. |
|
|
|
| GameSpot | GameFAQs | Metacritic | MP3.com | TV.com |
| Posted on Tuesday, October 11, 2005 at 08:31:26 PM | desolate |
|
| |
One of the bigger surprises of Microsoft's X05 press conference yesterday was that id Software was working on a new installment in its Castle Wolfenstein franchise for the Xbox 360. But there was nothing mentioned about a PC version of the game.
Given the recent success of Doom 3 on the Xbox, many PC devotees could be excused for fearing that id might have been wooed into making its first console-only title. While id Software has never debuted a new game on a console before (unless you count altered ports like Return to Castle Wolfenstein: Tides of War on the Xbox), many a heartbeat of many a PC gamer skipped in fear that this would be a new first.
Activision today calmed those fears with confirmation that the next Wolfenstein is indeed coming to both the Xbox 360 and the PC, with Raven Software handling development duties and id Software executive producing. While little is known about the game so far, bits of the story have been revealed. Players will be dropped behind enemy lines in World War II Germany and tasked with stopping technological and supernatural Nazi experiments that could change the course of the war. Activision has also indicated that the gameplay will mix straightforward guns-blazing action with exploration and stealth elements.
Wolfenstein will be the second id game simultaneously developed for PC and consoles. Raven Software is also handling the development of Quake IV, due out on the PC October 18 and on the Xbox 360 later this year. For more news out of X05, check out GameSpot's previous coverage.
Source:
http://www.gamespot.com/news/6135078.html |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (24)
.:Back to Top:. |
|
|
|
| - TeamWarfare Play-Off OSP and Shrub Tournaments Announced - |
| Posted on Monday, October 10, 2005 at 02:18:45 PM | NiteSwine|TWL |
|
| |
First rounds are scheduled to begin this next Wednesday and Thursday evenings. Your TeamWarfare RtCW administrators wish to thank the members of the RtCW community for a (somewhat bumpy but otherwise) smooth and successful regular season. :p Also, best of luck in what will be some serious competition during the post-season play-off tournaments. More information may be viewed at each of these links:
TWL RtCW OSP League Play-Off Tournament
TWL RtCW Shrub League Play-Off Tournament
TeamWarfare is working to assure that as many matches as possible will be covered by either/both WolfTV as well as iTG and/or TSN shoutcasting services.
Following the final matches, TeamWarfare RtCW intends to host some all-star matches, including one that will pit the respective tournament winners head-to-head in a final, multi-mod match-up that will put to rest the question of what mod has produced the best players and best teams once and for all. Look for more details on the TeamWarfare forums and in future PlanetRtCW news postings.
GL. PF. BN. HF. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (57)
.:Back to Top:. |
|
|
|
| TWL Week 7 - Sub Results |
| Posted on Friday, October 7, 2005 at 10:17:42 PM | Senatorrov? |
|
| |
final week of regular season is in the books
nox 3:2 damage
fmj 3:0 dsb
exodus 3:0 mongoloids (for some reason exodus got no points for this win)
defense4 3:0 teh buzzurds (ff win)
tribal valor 3:1 -SS-
quebec 3:0 RSF (ff win)
asc 3:0 -[x]-tremos
office space vs tna (match was canceled/ not showing up/ dual ff's)
SI vs ION (match was canceled/ not showing up/ dual ff's)
playoffs start next week |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (16)
.:Back to Top:. |
|
|
|
| Wolfers Day 2 Date Change, Extra Site Features, and MORE!!! |
| Posted on Thursday, October 6, 2005 at 06:26:59 PM | -doNka- |
|
| |
After a long and painful debate about the date of the Wolfers Day 2 tournament the administration decided to move the date to Sunday 15th, three days before Quake 4 comes out (might be your last chance to win something :D). We make this tournament for the people and we listen to their opinions. We want to give wolfers enough time create the teams to play with. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (68)
.:Back to Top:. |
|
|
|
| New Wolf for the xbox360 |
| Posted on Wednesday, October 5, 2005 at 06:40:54 PM | dFThinBe@gle |
|
| |
Raven announced that is allready developing the next Wolfenstein game. Not a whole lot was mentioned, or shown even (although it was clear it was a continuation of the mad scientist type world of Return to Castle Wolfenstein)
, but the Xbox 360 is the primary development platform for the game and it's based on new technology; a sort of extension of the MegaTexture tech used by ET: Quake Wars. Basically, expect Wolfenstein to have one huge game world. No more loading individual levels. No special title or release date was specifically mentioned, except that the Xbox 360 would be the exclusive first platform to receive the title.
http://www.ferrago.com/story/6668 |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (41)
.:Back to Top:. |
|
|
|
| TWL Week 6 - Frostbite Results |
| Posted on Sunday, October 2, 2005 at 07:21:19 PM | Senatorrov? |
|
| |
-[x]-Treme$old!3r$-[x]- vs Feel My Pain (no word yet, watch for the forfeit from TNA.)
{NoX}Team 3:0 Devil Stomper Battalion
Collateral Damage 3:0 Squad Bravo
Defense 4 3:1 Mongoloids
It's over now... 0:3 RENEGADE STRIKE FORCE ]EVOLUTION[ (ff win)
Suicidal Intent // 0:3 Office Space (ff win)
Syndicate-Soldiers 3:0 Wolfenstein Québec
Team Buzzurd 0:3 Exodu$
Tribal Valor 3:1 =FMJ=Clan E.
ggs, the next week is mp_sub.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (22)
.:Back to Top:. |
|
|
|
| week 7 schedule |
| Posted on Friday, September 30, 2005 at 05:51:18 PM | *c0ff1 |
|
| |
lucky 7 has finally come. most of the matchups should be real good games, looking forward to seeing the results. i realize that office space and TNA have been scheduled together before, but i figure lets schedule the teams that show up to play eachother... no point in putting a forfeiter vs a team that shows up!
again, if anything's messed up let me know. also, map should show sub and time/date should show 10EST next wednesday. if i messed those up, sorry. but you know
nox vs damage
fmj vs dsb
exodus vs mongoloids
defense4 vs teh buzzurds (the real motw imo?)
tribal valor :( :( :( :( vs -SS-
quebec vs RSF
asc vs -[x]-tremos
office space vs tna (motw: who will show?)
SI vs ION (motw#2: who will show?)
glhf to everyone |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (36)
.:Back to Top:. |
|
|
|
| New Logitech G5 Mouse and Icemats |
| Posted on Wednesday, September 28, 2005 at 07:47:56 PM | Sage-Buzzard |
|
| |
Just wanted to warn anyone that was in the market for a new mouse and uses an icemat, if you don't already know, the Logitech G5 mouse will not work on an icemat at all, the new laser system they use cannot penetrate the glass of the icemat, I also was reading that the new Razer Copperhead has Similar issues when using an icemat, but I myself have not tested a copperhead icemat combo yet. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (36)
.:Back to Top:. |
|
|
|
| TWL Week 6 - Frostbite |
| Posted on Sunday, September 25, 2005 at 09:55:55 PM | Senatorrov? |
|
| |
good ol' frostbite
-[x]-Treme$old!3r$-[x]- vs Feel My Pain
{NoX}Team vs Devil Stomper Battalion
Collateral Damage vs Squad Bravo
Defense 4 vs Mongoloids
It's over now... vs RENEGADE STRIKE FORCE ]EVOLUTION[
Suicidal Intent // vs Office Space
Syndicate-Soldiers vs Wolfenstein Québec
Team Buzzurd vs Exodu$
Tribal Valor vs =FMJ=Clan E.
BYE: TNA
"IF YOU KNOW YOU WILL HAVE TO FORFEIT, LET ME KNOW SO WE CAN SUBSTITUTE TNA IN FOR YOU!!!" - anyone else get a chuckle outa that? |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (169)
.:Back to Top:. |
|
|
|
| Your gaming rig?? |
| Posted on Saturday, September 24, 2005 at 03:41:28 PM | (7*up)LoXodonte |
|
| |
I got a kick out of reading what binds people use for their mouse. This topic is dedicated to expanding that conversation into other peripherals you use to wolf, or game in general. I remember deathstar used a Bilkin speedpad instead of a keyboard! He was pretty damn good with it too. I remember end0 telling me he once used a mead notebook as a mousepad! Weither your rig is ghetto, leet, or traditional post your details here. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (146)
.:Back to Top:. |
|
|
|
| TWL Week 5 - Base Results |
| Posted on Saturday, September 24, 2005 at 03:41:06 PM | Senatorrov? |
|
| |
Team Buzzurd 3:0 Office Space (ff win)
Tribal Valor 3:0 Defense 4
Syndicate-Soldiers 3:0 -[x]-Treme$old!3r$-[x]-
Devil Stomper Battalion 3:2 Wolfenstein Québec
It's over now... 0:3 =FMJ=Clan
Feel My Pain 0:3 Mongoloids
Collateral Damage 3:1 RENEGADE STRIKE FORCE
{NoX}Team 0:3 Exodu$
ASC 3:0 TNA (wow tna didnt ff)
next week is frostbite
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (6)
.:Back to Top:. |
|
|
|
| #Wolfers Day Winners, Games, and Stats |
| Posted on Wednesday, September 21, 2005 at 04:57:21 PM | -doNka- |
|
| |
#Wolfers Day tournament has started 18th of September at 8PM EST and ended about 4 hours later. There were some nice games gamed and plays played during the tournament. All of the matches were reviewed on the official site. You can find the stats and demos if you look carefully through the overview post. The final word and global stats coming in a few days. Stay tuned... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (47)
.:Back to Top:. |
|
|
|
| Week 5 schedule for TWL OSP Season 10 |
| Posted on Monday, September 19, 2005 at 06:03:48 PM | bull-z-@ |
|
| |
TWL Week 5
Team Buzzurd vs Office Space
Tribal Valor vs Defense 4
Syndicate-Soldiers vs -[x]-Treme$old!3r$-[x]-
Devil Stomper Battalion vs Wolfenstein Québec
It's over now... vs =FMJ=Clan
Feel My Pain vs Mongoloids
Collateral Damage vs RENEGADE STRIKE FORCE
{NoX}Team vs Exodu$
ASC vs TNA
-----------------------------------------------------------
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (43)
.:Back to Top:. |
|
|
|
| hey! |
| Posted on Sunday, September 18, 2005 at 11:53:30 PM | yoshi |
|
| |
hey alien team was not busted alien yakuza is my friend he was the founder whit alien boom and sometime yakuza was playing on my comp on rtcw whit my key so is why maybe you think am yakuza and i dont have the same ip of yakuza he dont play wofl annymore long time ago so .... and do you have proof for the ip |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (49)
.:Back to Top:. |
|
|
|
| Wolfenstock Preview |
| Posted on Sunday, September 18, 2005 at 06:15:03 PM | -doNka- |
|
| |
The spots are filling up and the picture is starting to clear up a bit. Here’s my overview of the wolfenstock teams:
DISCLAMER: NONE OF THE INFO BELOW IS FINAL
Teh Birds
Roster: Mesh, caffeine, spuddy, sonic, rampage +?
Currently they play in TWL as Defense4 with an impressive 4-0 record. This team has shown that they can play against anyone in the last season of CAL.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (25)
.:Back to Top:. |
|
|
|
| Wanna pub? |
| Posted on Friday, September 16, 2005 at 02:34:52 AM | ChumChum |
|
| |
For those of you who would like another place to pub, we have put up a new server with a *gasp* rotation! The server is located in Atlanta and is provided by Hi-Definition Gaming. Since this is our match server, we will take it down if we have a match on it. Since we do not scrim, that should mean we only make it private for a couple of hours a week on Wednesdays.
Hi-Definition Gaming provides high quality gaming servers along with high quality service. These guys truly do provide only the best performing servers for the following games:
Counter-Strike 1.6
Call of Duty
Call of Duty: United Offensive
Return to Castle Wolfenstein
Enemy Territory
Quake 3 Arena
The server is called Locked Box OSP Competitive Public and can be found at 63.251.78.36:27960
As of now, the rotation is base, beach, assault, chateau, ufo, ice, frostbite, sub, and village. I stuck to the TWL map list for now but would very much like to add customs if people are willing to play them.
Chocula, Pissclams, and myself will have ref to the server so any issues with players should be directed to us. We want this to be a fun server that everyone can enjoy. This is not a server to stroke your ego. Just play and have fun. If you get killed, shut up and spawn like everyone else. It will probably only be up for this season as I plan on playing F.E.A.R. when it comes out ;)
#hidef #itsovernow on Gamesurge |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (45)
.:Back to Top:. |
|
|
|
| #Wolfers Day Tentative Format, Schedules, and Maps Posted |
| Posted on Thursday, September 15, 2005 at 07:51:12 PM | SnipeTX |
|
| |
#Wolfers Day is getting even closer with the announcement of the maps and schedules for this upcoming Sunday. The front page has the information about maps and times of the tournament, as well as pissclams' recipe for Hot Jalapeno Crab Dip (sounds delicious).
One a side note, I've noticed that not all of the site users have signed up for the actual tournament. If you plan to play in #Wolfers Day(8-11pm Sun 18th) make sure that you've also signed up for the actual tournament. Hurry up and register your teams. MAX # of teams was set at 8(eight).
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (17)
.:Back to Top:. |
|
|
|
| TWL Week 4 - Assault Results |
| Posted on Thursday, September 15, 2005 at 07:49:52 PM | Senatorrov? |
|
| |
bzz 3:0 nox
xtreme soldiers 0:3 fmj
cd 0:3 mongoloids
tv 3:0 dsb
rsf 2:3 wqc
os - tna (rescheduled, will update as soon as results are in)
asc 3:0 feel my pain (ff win)
exodus - Itsovernow (awaiting results)
ss 0:3 d4 (second time for this matchup this season)
BYE: Suicidal Intent
if the 1 ff win is the worst that happens, the week went alright
lookin foreward to week 5 base
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (9)
.:Back to Top:. |
|
|
|
| #Wolfers Day Tournament Signups Open. |
| Posted on Tuesday, September 13, 2005 at 10:38:34 PM | -doNka- |
|
| |
As it has been announces in the previous thread, the signups for #Wolfers Day tournament were open. You can visit the tournament site here:
#Wolfers Day
Please feel free to look around, sign up, vote for maps, and get a team going. As much as I like how fuZion got excited about a draft tournament I hope it's not going to happen. Let me explain myself. The way the site is set up right now can allow draft(pug) teams to be created later when pug has a descent amount of people. But I strongly believe that it is in your best interest to create a team that YOU want to play with. I strongly believe that it is in your best interest to be on a team that consists of people you know and that will actually show up for the day.
Tentative schedule will be up Saturday morning and the Tournament will be held Sunday night-ish. Get your team signed up and look for people in the pug section to fill the gaps. Roster lock will never technically happen, but a user can only play for one team throughout the event. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (46)
.:Back to Top:. |
|
|
|
| One Day Tournament From #Wolfers |
| Posted on Monday, September 12, 2005 at 02:51:31 PM | -doNka- |
|
| |
#Wolfers has decided to conduct a market research in order to determine a demand for a one day RTCW tournament.
What would be the tournament like?
Length: most likely - one day
Maps: Standard
Format: 6v6, best of three(all different maps). SE if there will be more than 8 teams, otherwise DE
Player Eligibility: must not show up red on TWL, MBL, and PBL.
Teams: any bunch of six+ eligible players
The rest is to be determined from received feedback. Desired days and times for matches as well as all other suggestions post here.
Vote here: www.donkanator.com/wolfers |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (45)
.:Back to Top:. |
|
|
|
| TWL Week 3 - TE_UFO Results |
| Posted on Thursday, September 8, 2005 at 07:05:13 PM | Senatorrov? |
|
| |
Tribal Valor 0:3 Team Buzzurd
Suicidal Intent 0:3 =FMJ=Clan
Defense 3:0 vs Collateral Damage
{NoX}Team 3:0 It's over now...
RENEGADE STRIKE FORCE 2:3 Devil Stomper Battalion
Syndicate-Soldiers 0:3 Exodu$
ASC vs Office Space (awaiting results)
Mongoloids 3:0 Wolfenstein Québec
-[x]-Treme$old!3r$-[x]- 3:0 TNA
no ffs this week, lookin good. hopefully many more to come
(unless its the ASC vs Office Space match, which is still awaiting results.) |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (21)
.:Back to Top:. |
|
|
|
| Comedy Of Haxors Staring Method |
| Posted on Thursday, September 8, 2005 at 04:17:29 AM | pissclams |
|
| |
Stumbled across this thread at the Ganja Palace Forums, apparently Method got caught hacking on a shrub server and was banned from Ganja Palace recently. In a superstar attempt at getting unbanned, the aforementioned Method wrote up a very sincere but incredibley lame and hilarious post apoligizing for not hacking but only testing the hack. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (112)
.:Back to Top:. |
|
|
|
| TWL Week 3 TE_UFO |
| Posted on Monday, September 5, 2005 at 05:46:28 AM | pissclams |
|
| |
Oh wtf, we're week 3 into Season #10 over at the TWL OSP league (http://www.teamwarfare.com) and the schedule has been posted. Looks like some good match ups on this week's map te_ufo. Kiss your FPS goodbye and say hello to spammy defenses.
Enjoy!
Tribal Valor vs Team Buzzurd
Suicidal Intent vs =FMJ=Clan
Defense 4 vs Collateral Damage
{NoX}Team vs It's over now...Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (146)
.:Back to Top:. |
|
|
|
| TWL Week 2 - Beach Results |
| Posted on Friday, September 2, 2005 at 10:03:09 PM | Senatorrov? |
|
| |
-[x]-Treme$old!3r$ 0:3 Defense
Exodu$ 3:1 =FMJ=Clan E.
Mongoloids 1:3 Team Buzzurd
Office Space vs. Collateral Damage (no report yet, awaiting results)
RENEGADE STRIKE FORCE 0:3 {NoX}Team
Suicidal Intent 0:3 Syndicate-Soldiers
TNA 0:3 Devil Stomper Battalion
Tribal Valor 3:0 Feel My Pain
Wolfenstein Québec 0:3 (ff win) Team RAStronauts
It's Over Nox had a BYE
this weeks only ff was from WQC, didnt expect that
once again ggs this week, hopefully more to come
keep it up
(woulda added colors but i have nfc what everyones colors are) |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (29)
.:Back to Top:. |
|
|
|
| #Wolfers On Gamesurge.net Opens With RTCW Trivia |
| Posted on Wednesday, August 31, 2005 at 03:14:26 PM | -doNka- |
|
| |
#Wolfers is meant to bring together the remained masses of RTCW players. Those players that are scattered across irc networks, channels, vent server, AIM, ICQ, and even MSN(lame) groups.
#Wolfers is for players to meet their ex-teammates that shared seasons of RTCW together.
#Wolfers if for chatting, scrimming, pugging, whatever RTCW purposes and more.
#Wolfers goes public this Wednesday, last day of this RTCW summer.
#Wolfers will be having famous RTCW Trivia at 8pm EST
#Wolfers is YOUR channel if you read this site.
#Wolfers should be in your autojoin.
#Wolfers is for real wolfers.
PS: winners of the trivia will be put on hall of fame on www.donkanator.com/wolfers |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (33)
.:Back to Top:. |
|
|
|
| TWL Week 2 - Beach |
| Posted on Monday, August 29, 2005 at 02:27:39 PM | Senatorrov? |
|
| |
***Home team listed first***
-[x]-Treme$old!3r$ vs. Defense
Exodu$ vs. =FMJ=Clan E.
Mongoloids vs. Team Buzzurd
Office Space vs. Collateral Damage
RENEGADE STRIKE FORCE vs. {NoX}Team
Suicidal Intent vs. Syndicate-Soldiers
TNA vs. Devil Stomper Battalion
Tribal Valor vs. Feel My Pain
Wolfenstein Québec vs. Team RAStronauts
got preds? |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (53)
.:Back to Top:. |
|
|
|
| TWL Week 1 - Village Results |
| Posted on Thursday, August 25, 2005 at 02:14:43 PM | Senatorrov? |
|
| |
[x] 2:3 (with 1 tie) {NoX}
FMJ 1:3 Defense 4
cD 3:0 DSB
exodu$ 3:0 Feel my Pain
It's over Now 3:0 OS
Mongoloids 3:0 (ff win) phx
RSF 0:3 SI
SS 1:3 Buzzurd
RAStronauts 3:0 (ff win) Alliance
TNA 0:3 (ff win) TV
Phx and teh alliance were expected to ff, and did so.
Some gg's so far. Hopefully many more to come.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (200)
.:Back to Top:. |
|
|
|
| TWL Preseason Results |
| Posted on Monday, August 22, 2005 at 03:59:56 AM | -doNka- |
|
| |
Format: OSP SW 6v6
Map: mp_chateau
Week: Preseason
(Winnders on the right)
-[x]-Treme$old!3r$-[x]- 3:2 Wolfenstein Québec
Tribal Valor 3:2 {NoX}Team
Mongoloids 3:0 Office Space
Defense 4 3:2 Syndicate-Soldiers
=FMJ=Clan E 3:0 Collateral Damage
Exodu$ 3:0 Suicidal Intent
RENEGADE STRIKE FORCE 3:0 Devil Stomper Battalion
Team Buzzard FF TNA
Feel My Pain FF Team RAStronauts
Team omen ??? teh alliance
As a result we have THREE very close games, 2 matches were not yet reported and only ONE forfeit loss. What a great kick off for a TWL season 10. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| TWL Season 10 Preseason Kicks Off! |
| Posted on Tuesday, August 16, 2005 at 12:03:12 AM | Senatorrov? |
|
| |
(Home Vs. Away)
-[x]-Treme$old!3r$-[x]- vs Wolfenstein Québec
{NoX}Team vs Tribal Valor
TNA vs Team Buzzurd
Team omen vs teh alliance
Team RAStronauts vs Feel My Pain
Mongoloids vs Office Space
Defense 4 vs Syndicate-Soldiers
Collateral Damage vs =FMJ=Clan E
Suicidal Intent vs Exodu$
Devil Stomper Battalion vs RENEGADE STRIKE FORCE
Something is wrong with their system so they cant set them all up the normal way, so they put it a forums post. It should be fixed soon.
gg's gl
predictions? |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (49)
.:Back to Top:. |
|
|
|
| TWL Launches 4 RtCW Servers |
| Posted on Monday, August 15, 2005 at 04:52:18 PM | Mortal :o |
|
| |
TWL recently launched 4 servers for RtCW pub/competition. Two of them are OSP and two of them are Shrub. They are sponsored by ETGameHosting.net. Heres more info from the TWL forums...
Teamwarfare League announces the availability of four new servers for your wolfing pleasure. These servers are located in Texas and Chicago. They should ping well for the majority of gamers.
They are hosted by our friends at etgamehosting.com. If you would like to check them out, I'm sure Knuckles would appreciate it!
The servers are as follows:
206.123.111.254:27960 Texas (Default Shrub) TWL-RtCW 1
206.123.111.234:27960 Texas (Default OSP) TWL-RtCW 2
64.182.103.51:27960 Chicago (Default Shrub) TWL-RtCW 3
66.254.112.109:27960 Chicago (Default OSP) TWL-RtCW 4
These servers are available to teams to reserve for matches and scrims as available. They will remain public at all other times. Please see any of the admins in #twl_rtcw to reserve one.
Good luck this season and let's have some fun!!!
wo0t :O |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (7)
.:Back to Top:. |
|
|
|
| TWL Forum Frenzy |
| Posted on Wednesday, August 10, 2005 at 09:48:03 PM | Mortal :o |
|
| |
If you all miss the usual banter between idiots and poor english in high quantity; then you should definately hop on over to the TWL forums. They have been having alot of it lately!
Recent spree's of players from the Tribes 2 forums have been posting alot on the Wolfenstien forums... and its all about what game is better. Its interesting, as most Tribes 2 players posting are blind rampant fools.... some of the RtCW crowd does a good job blending.
Enjoy.... TWL RtCW Forums @ its finest. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| TWL OSP Season #10 Predictions |
| Posted on Tuesday, August 9, 2005 at 03:08:21 PM | Mortal :o |
|
| |
Though Season #10 hasn't even gotten under way, I know some players have a good mind of who will fold, who will stay, who will win, and who will be in the finals.
Any thoughts?
I think alot of teams will fold, but I wouldn't be suprised to see some decent competition between Buzzard, cD, SI, -x-, and TV. I would see TV and -x- ( if they stay together ) in the finals.
Never know tho, small spirts of game love die fast... and teams fold mid-season no matter what the win loss ratio is. Hopefully we will see some teams stick with it, have fun, and play some good matches. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (33)
.:Back to Top:. |
|
|
|
| Gamecloud/ Speakeasy RTCW servers to shut down within the month. |
| Posted on Monday, August 8, 2005 at 02:16:26 PM | Senatorrov? |
|
| |
I talked with citizen today to try to see what was being done to fix the problem with the speakeasy servers, and I found this out.
(over irc)
"...
rov: your the head admin for gamecloud RTCW servers right?
citizen: i guess you could say that - i set them up but rarely am able to look at them these days
citizen: they won't be up much longer tho tbh - those servers are going to get repurposed in the near future for a big project i am working on
rov: o
rov: i was wondering if anyone was really looking at them
rov: cause theyve gone straight down the toilet
rov: how much longer will they be up?
citizen: a month or so at most i think
..."
Gamecloud is making some new system thats suposed to be pretty sweet. Some games are already set up with the new system, but RTCW is not one of them. Citizen mentioned that RTCW would not be in the new system, and that it would likely be replaced by ET.
I wish Gamecloud would have had a little more quality control to keep their servers hack free and keep the 12 year olds out of ref. but anyway, thanks for the many servers that let us match/scrim/pub on. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (11)
.:Back to Top:. |
|
|
|
| El Nova 5 |
| Posted on Thursday, August 4, 2005 at 03:04:39 PM | c[_]`Wippuh |
|
| |
From cached.net
It's been way to long, way to long. It's that time of the year again folks, EL NOVA 5 (not TDM) takes off to bring you heart pounding action again. This time how ever I’m breaking the rules, it's no longer going to be Quake III Arena Team Death Match. Oh no, that's way to easy to play, I decided to even stray away from the same ol' Quake 3 nonsense.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| 5v5 Ladder closure |
| Posted on Monday, August 1, 2005 at 02:19:33 PM | fu|megs |
|
| |
The time has come to close down the 5v5 ladder. It has had a great run and lots of great past teams have played on it. (Hostile comes to mind) Looks like DSB has been the most active 5v5 team and has been on the ladder for years.
This is an official notice that the ladder will be closing effective immediately.
Thanks,
-Skeeve |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (24)
.:Back to Top:. |
|
|
|
| Interest in Forum Games? |
| Posted on Tuesday, July 19, 2005 at 03:15:52 PM | c[_]`Wippuh |
|
| |
Remember Friday Night Madness? Remember the precursor to that Forum Game Friday? Hosted by a ton of different groups, this was a hugely popular passworded pub game organized on planetwolfenstein's forum. Well, it looks like there's still some guys trying to rebuild the forum game mentality!
XPlates, of Timelord fame, tried last week to set up a forum game for Thursday night. Sadly, not many still visit Planetwolfestein anymore.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (24)
.:Back to Top:. |
|
|
|
| ET Getting Hit Hard |
| Posted on Tuesday, July 19, 2005 at 02:44:22 PM | c[_]`Wippuh |
|
| |
ET, the little sister of RtCW, is getting hit extremely hard in their competitive scene by hackers. Following the path that RtCW took, the main participants seem to be a lot of lower level league players who are just not that good.
The Guild (think Superheros, just not as mature) has recently had 4 members suspended in CAL and TWL is updating their ban list weekly it seems.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (15)
.:Back to Top:. |
|
|
|
| Quake 4 to be released by Christmas. Will RtCW 2 be far behind? |
| Posted on Tuesday, July 19, 2005 at 10:12:28 AM | -opp bigbear- |
|
| |
Activision CEO and President Ronald Doornink recently confirmed that Quake 4 and other games will be released in 2005. Among these games will be the much anticipated Quake 4:
"As part of Activision's earnings call today, CEO and president Ronald Doornink answered the customary questions from game industry analysts.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (12)
.:Back to Top:. |
|
|
|
| RtCWforLife Looking For Founder |
| Posted on Wednesday, July 13, 2005 at 06:10:30 PM | c[_]`Wippuh |
|
| |
RtCWforLife is the new team that is to be formed on the TWL 8v8 CS:S ladder. There's already a RtCW4Life but the roster is full and there's several more people wanting to join. If anyone is willing to be the founder, I can help them get everything else set up.
Also, if anyone wants to set up an RtCW4Life on other TWL ladders, please let me know :) |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (12)
.:Back to Top:. |
|
|
|
| Fatal1ty wins US CPL Tour Stop. wombat finishes in the $$$ |
| Posted on Monday, July 11, 2005 at 08:00:37 PM | -opp bigbear- |
|
| |
Fatal1ty picked up the title in the Painkiller event at the summer CPL which doubled as the US stop in the $1,000,000 World Tour. Fatal1ty picks up $15,000 for this impressive win over VoO and is already qualified for the Championship Event at the end of the tournament. wombat formerly of The Doctors in RtCW and dr./[3D] in CoD picked up 6th place winning $2.500. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (26)
.:Back to Top:. |
|
|
|
| Powers Gaming Wins CPL CS:S Championship |
| Posted on Monday, July 11, 2005 at 04:57:06 PM | -opp bigbear- |
|
| |
Powers Gaming featuring ex-rtcw players NightFaLL and Warmachine has won the $60,000 (total prize money split between the teams that placed not the 1st place team) CS:S tournament at the Summer CPL event. PG cruised through the tournament without a single loss. After losing their CAL-I runoff match with Visual Gaming prior to the start of the official CPL event PG went all business and dominated the field ending with a 16-5 win on de_dust2 against Upper. This is NightFaLL's second CPL championship in his second game (he was the team leader of a CoD CPL champion) and Warmachine has been a member of several top CoD and CS:S teams since leaving RtCW.
For more information on all CPL events visit:
http://www.gotfrag.com/cs/filters/296/ |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (10)
.:Back to Top:. |
|
|
|
| A New Direction |
| Posted on Thursday, July 7, 2005 at 04:15:25 PM | c[_]`Wippuh |
|
| |
Since it's been well over a week with no news submitted, it's time to shift the focus of planet-rtcw. We'll now be keeping up with exRtCW players in other games (CS:S, ET, CoD, etc...). We'll mix in any news about RtCW2 of course and keep this site as the meeting place for RtCW players who are interested in what their old pals are doing out in the competitive gaming world. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (37)
.:Back to Top:. |
|
|
|
| 4 NA Teams Make it to Qcon |
| Posted on Thursday, July 7, 2005 at 04:10:51 PM | c[_]`Wippuh |
|
| |
For the ET tourney, only 4 NA teams made into the official tourney. They are...
United5
No Remorse (Skeeve, Nard)
Darkside (illshot, stiegl, nothx)
Kinetic
Expect more NA teams to be named to the bracket as the overseas teams drop due to money issues. Affliction was considered a heavy favorite to make it in, but dropped out of the qualifiers after deciding they didn't want to go to Dallas?Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (21)
.:Back to Top:. |
|
|
|
| PowersGaming Falls to VisualGaming |
| Posted on Thursday, July 7, 2005 at 04:05:14 PM | c[_]`Wippuh |
|
| |
In CPL news, PG, led by former RtCW players Nightfall and Warmachine, lost to VG 16-13 on de_train. This was a make up match of the CAL-I final where Skull beat PG but was later found to have a player toggling hacks on their roster.
We'll keep you updated on PG's progress through CPL as the official tournament starts. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (3)
.:Back to Top:. |
|
|
|
| STA ULTL Shrub League |
| Posted on Sunday, June 26, 2005 at 11:53:08 PM | :)Trinners |
|
| |
STA is creating an unlimited lives Shrub league for all those hardcore Wolfers that aren't ready to see the game die or succumb to inferior games. This league will feature a 6v6 format with a 1 panzer limit. Matches will be played on either Mondays or Tuesdays at 21:30 EST (9:30PM) based on clan feedback.
If all goes well, competition should start in mid-July. To sign-up, visit http://wolf.sta-league.org. You can also join in the discussions on the forums with regard to match nights, maps, et cetera.
STA LL Shrub, meanwhile, is still going strong as it heads into the Season #2 playoffs. If you'd like to join for Season #3, visit http://shrub.sta-league.org. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (25)
.:Back to Top:. |
|
|
|
| Objective Taken - New Movie Trailer |
| Posted on Thursday, June 23, 2005 at 09:10:53 PM | f.EAu' sala |
|
| |
I have recently completed the trailer for my current project, Objective Taken. This is an RTCW frag movie feating the North American player spec opz whose past clans
include Superheroes, Star, Flatline, Mauser Rage, Hair Pullers, Metal Gawds, and Splash My Nuts. This is as much a frag movie as it is a truly cinematic experience
celebrating the amazing game that we simply call "wolf."
Big thanks to own-age.com and swertcw.com for hosting.
Work will continue on the feature presentation to be released later this summer. I hope you enjoy it and look forward to any and all feedback I may receive.
link: http://www.own-age.com/vids/video.aspx?id=5156
More mirrors to come in the future.
#filanthropy @ irc.quakenet.org
http://www.filanthropy.com
-james
~fin~ |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (45)
.:Back to Top:. |
|
|
|
| gg's |
| Posted on Monday, June 6, 2005 at 09:43:49 PM | sonicreducer |
|
| |
Removal of RTCW from CAL
Due to lack of participation from the community, the number of reported FF's, and other variables, The Cyberathlete Amateur League would like to inform the remaining participants that we are closing down the RTCW division of CAL. We appologize for any inconvenience this might cuase to the remaining clans who are active. We would like to remind everyone that ET will be remaining in CAL.
Posted by Chris Kitto on Mon, Jun 6, 05 at 14:41
http://www.caleague.com |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (207)
.:Back to Top:. |
|
|
|
| May 9th - Victory Day |
| Posted on Tuesday, May 10, 2005 at 07:09:50 PM | -doNka- |
|
| |

On May 9th 1945, the new government of fascist Germany announced capitulation, and by that after almost 6 years the Second World War ended.
Not many people in the USA know that today, on May 9th, in some parts of the world people are celebrating the great victory over the fascist Germany. There was not a single country on the planet that was not affected by the World War 2. Young generation must remember the price that was paid by our grand relatives for the world we live in. Please pass congratulations to the WW2 veterans if you have them among your family and friends.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (57)
.:Back to Top:. |
|
|
|
| Rabia Season 9 movie now available for download |
| Posted on Friday, May 6, 2005 at 12:35:42 AM | kalamazoologist |
|
| |
Well, I'm finally as finished as I'll ever be with this thing. Hard to believe season 9 was so long ago. To put it in perspective, during all those hurricanes last year the power was out at my house, so I had to take my PC into the office to play our match vs. Xcal on tundra, then drive home in pitch black Orlando with all the traffic lights dead. Good times. At times Rabia felt like an unstoppable force, the amount of invididual talent, teamwork and chemistry was impressive. We had a great undefeated season until we hit the fX brickwall. Good games to my friends in Rabia and all the teams we played (Affliction, Made Men, Excalibur, Team Effect, Collateral Damage, High Voltage, Minions, Eggnog Squad, ASF, Band-aid, Growers Anonymous). Hope to meet some of you at Qcon.
It's not a revolutionary movie, but hopefully entertaining to those still around. No widescreen, no elaborate intro or nasty effects, just highlights from our season put to music with a few EDV edits. Just making a fragmovie here, not trying to start my own production studio.
You can get it from own-age at:
http://www.own-age.com/vids/video.aspx?id=4723
Or if that doesn't work, directly from:
http://www.aequitas-owns.com/Rabia-Season_Nine.zip
Thanks to fretn for hooking me up with the latest unreleased EDV source. I didn't use the new EDV features as much as I could or should have, but it was a tremendous help to be able to add the display features I wanted to the existing freecam stuff. Also thanks to hiki for his suggestions, and elliott for giving me a place to upload it. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (76)
.:Back to Top:. |
|
|
|
| Made Men comeback |
| Posted on Thursday, May 5, 2005 at 03:04:07 PM | [M2]Retired |
|
| |
Yah, don't look now, at least one team is coming back and hopefully won't be giving forfeit losses away :P
Pretty much all of the standard recent lineup is coming back for one more go at it.
Saint, Turk, Ham, Chase, Scotty, Tonka and Goddess have already signed up and Ugly says he's down. The only recent member not in there is MC/Hexum who will probably say what the hell if we ever get a hold of him.
Anyways, not much of a news, but for a squad that has been around since December 2001 to be making its comeback, hell we just can't let this game die yet. :)
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (23)
.:Back to Top:. |
|
|
|
| Week 2 Results. |
| Posted on Monday, May 2, 2005 at 04:57:49 PM | c[_]`Wippuh |
|
| |
Absolute Synergy vs BYE 3-0
Absolute Synergy- vs ~ Return to Divnity ~ 3-0 FORFEIT
Accurate vs Team Excess 3-2
FMJ|E. vs Team Exodus 3-0 FORFEIT
Godfathers of Destruction vs Teh Admin Clan 3-0 FORFEIT
Hair Pullers vs Clutch 3-0 FORFEIT
Team Trinity vs Fear Us 3-0 (5vs4)
FMJ|C. vs NoX Team 3-0
2 real matches played :-/ |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (88)
.:Back to Top:. |
|
|
|
| STA-RTCW Shrub Season #2 starts this Sunday |
| Posted on Friday, April 29, 2005 at 02:15:50 PM | :)Trinners |
|
| |
Just a reminder that STA-RTCW Shrub Season #2 (6v6, no panzers, limited lives (6)) kicks off this Sunday, May 1st on Assault. Fourteen teams are currently signed up for Season #2. Teams may join through Week #3 and still be eligible for the playoffs. Below is the map list/schedule.
05/01 Week 1: Assault
05/08 Week 2: Frostbite
05/15 Week 3: Ice
05/22 Week 4: Axis Complex
MEMORIAL DAY WEEKEND HIATUS
06/05 Mid-Season ProBowl
06/12 Week 5: UFO
06/19 Week 6: Infamy
06/26 Week 7: Beach
JULY 4th HOLIDAY HIATUS
07/10 Week 8: Final Stand
07/17 Playoffs begin followed by the Post-Season ProBowl Best of luck to all this season!
-STA-RTCW Admins |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (8)
.:Back to Top:. |
|
|
|
| STA-RTCW Season #8 |
| Posted on Friday, April 15, 2005 at 06:16:46 PM | :)Trinners |
|
| |
STA is introducing a few changes to reflect changes to the community. Starting in Season #8, which will begin on Monday, May 2nd, STA will feature the OSP mod in a 5v5 format. We are currently debating whether or not to allow 1 panzer in this configuration so please share your thoughts on the forums.
In addition, STA is going to go with an all custom map season. If there is a custom map you've been dying to play in competition, again please share your thoughts in the forums. Please keep in mind that all custom maps need to be reviewed for bugs first.
We are currently accepting applications for the upcoming season so spread the word with your fellow clans. One final note, Season #8 will feature no preseason. There will, however, be: an 8-week regular season, playoffs, and a probowl. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (77)
.:Back to Top:. |
|
|
|
| Syndicate Soldiers, STA-RTCW Shrub Season #1 crown |
| Posted on Wednesday, April 13, 2005 at 07:05:45 PM | :)Trinners |
|
| |
-|SS|- and -nJ- proved to be formidable opponents as the two faced off on Base in the STA-RTCW Shrub finals match. Once again, congratulations are in order for both teams for making it into the finals. -nJ- fought valiantly and gave -|SS|- a run for their money, despite having to play down a man, but came up short. -|SS|-'s 3-0 victory topped off a perfect season--an amazing achievement--to be crowned STA-RTCW Shrub Season #1 champs! Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (158)
.:Back to Top:. |
|
|
|
| Hello! |
| Posted on Wednesday, April 13, 2005 at 01:20:44 AM | CAL-rtcw|Pattison |
|
| |
I'm sure most of you know now that I'm a new CAL rtcw admin. I just want to let everyone know that I'll do the best of my abilities to help out the community in any way possible. A few things I have thought of so far are.
-I will be present in a server for a match that I will choose for whatever reason (rumors of hacking, etc etc) or a high profile match that I think I should be there for. I will also be idling in irc so if there is any need for me to hop onto another server to settle a dispute I can be there.
-I have turned my auto accept in irc on. This is so I can leave my irc on all the time so people can send me demos, screenshots or whatever to me. Please have all these files made into a zip or rar file.
-Trying to implement new CAL rules, but first I have to go over these with my CAL coleagues. A few things are 1. A GUID that must be atleast 2-3 months old on the speakeasy.net database 2. Changes in the cvar settings 3. Custom maps
Pretty much everything that was discussed at the CAL Careface meeting.
-I tend to pub a lot. So I assume I will be given ref passwords on the speakeasys. If I see anyone playing out of place or causing trouble they will get a warning then the boot. I could also be on irc and someone could come message me if trouble arises.
Anyhoo these are just a few of my thoughts of what I could do to make this community better. Any feedback would be great. :) JAVOHL!
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (119)
.:Back to Top:. |
|
|
|
| Scrimnet RtCW ScrimBot Added! |
| Posted on Tuesday, April 12, 2005 at 05:32:18 PM | Mortal :o |
|
| |
notice in #Scrimnet:
> Scrimnet(notice) ( we're adding rtcw support again (hopefully people show an interest this time... to get a rtcw scrimbot please visit our website to apply, www.scrimnet.com -diarmuid )
To easily sign up for a scrimnet bot simply go to the site ( http://www.scrimnet.com and click the "Apply" tab at the top. You can then type your channel name, needs @ least 10 idlers, and your email. You can select more then 1 game by selecting one, then holding ctrl and selecting anouther. Same with the location selection. Hope you guys get this setup and use it, should be fun!
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (12)
.:Back to Top:. |
|
|
|
| 5 vs 5 League Play? What Are Your Thoughts... |
| Posted on Sunday, April 10, 2005 at 02:12:37 AM | pissclams |
|
| |
During the CAL League meeting I suggested the league consider going to 5's. It's harder and harder to find 6 guys to scrim/match/etc and I just think it's time. The game can support 5's pretty well as the success of the TWL 5 vs 5 ladder would testify to, I put up a new poll here at the site and want to know what you guys think.
What are your comments- |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (53)
.:Back to Top:. |
|
|
|
| GGs |
| Posted on Friday, April 8, 2005 at 01:45:21 PM | gisele |
|
| |
Announcing Quakecon 2005 Tourney Games
DOOM 3, ET, Quake 2 and 3 back for another year
You've waited for it, practiced with your teammates, and chomped at the bit for more information about the Quakecon 2005 Tournaments, and we're finally ready to give you a preview of the action in August.
Oil your mouse, clean your keyboard, and practice that strafe jump for 4 white-hot tournaments.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (143)
.:Back to Top:. |
|
|
|
| Comcast Hacked |
| Posted on Friday, April 8, 2005 at 03:55:06 AM | Thorian |
|
| |
Evidently Comcast was hacked today, and it pretty much killed the ability for a lot of customers to surf the Internet and use various online services. The component that is causing the failure are the Comcast DNS servers. These servers are responsible for converting domain names (like www.yahoo.com) into IP addresses (66.94.230.48). Obviously if you had to surf to every website by its IP address there would be no way to remember them all, hence the use of domain names.
While we wait for Comcast to resolve the issue with their DNS servers, there is a way to manually switch to using another third-party set of DNS servers (such as Verizon's). Here is how to do so:
1. Find "My Network Places" and right click - select "properties."
2. Right click on "Local Area Connection" - select properties again.
3. Double-click TCP/IP Internet Protocol.
4. At the bottom of the form, select "use the following" under the DNS area.
5. Enter 4.2.2.1 and 4.2.2.2 as the two ip addresses to use.
6. Hit OK until you have cleared all windows.
This will start using the Verizon DNS servers (thanks to Imposter for providing the IPs and instructions), and allow you to surf the web again. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (12)
.:Back to Top:. |
|
|
|
| CAL Puts On a Careface. |
| Posted on Thursday, April 7, 2005 at 06:44:28 AM | -doNka- |
|
| |
From CAL's site:
"The RtCW CAL Admin team wants to hear YOUR opinion! Please come talk to us about anything and everything to do with next season! On Saturday at 9:30 EST, Charley, Justins and Daniel will be avaible to hear your opinions and suggestions for next season concerning maps, cvars, new rules or anything YOU can think of! Stop by #caleague-wolf to let us know, if you can't make it saturday please stop at your convience and hopefully myself or another admin will be able to get with you shortly!"
So if you've got nothing better to do on a Saturday night, please drop by the channel above to give some feedback on the recent actions of the newly appointed RTCW Division Manager and his et-boss - CAL|Daniel, who doesn't mind checking up on our RTCW division every once in a while. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (94)
.:Back to Top:. |
|
|
|
| An Interesting Proposal. 50 to 35? |
| Posted on Wednesday, April 6, 2005 at 04:50:35 PM | c[_]`Wippuh |
|
| |
Over at the TWL forums there's a locked thread that brings up an interesting proposal that I'm sure many of you have thought about too. As you all know the standard ping differential across both TWL and CAL is 50. That's a massive differential and there's no doubt that a team having an average ping of 51 has a signifigant advantage over a team with an average ping of 100. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (88)
.:Back to Top:. |
|
|
|
| Spread Da Love Friends |
| Posted on Tuesday, April 5, 2005 at 08:23:35 PM | gisele |
|
| |
Due to CAL's recent action to remove Wippuh (CAL|Bob) as CAL admin, I have created a petition for those interested to sign. It's basically a petition to get Wippuh back in CAL, as he is our last hope. This isn't a free bash Wippuh or CAL session either, so please refrain from such comments.
If you feel that Wippuh should be reinstated as CAL admin, I am asking that you please sign this petition.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (91)
.:Back to Top:. |
|
|
|
| Covert Operations Server says goodbye freinds! |
| Posted on Tuesday, April 5, 2005 at 07:18:00 PM | OpZ |
|
| |
Covert Ops Server says goodbye!
It has been an incredible 6 seasons of fun, fragging, laughs and emo! The Online Stomping Grounds contract has expired and I have decided to not renew as I am more or less reducing my RtCW time now as rl issues are pressing. Here are some historical things regarding the server.
Season 5 or so, the Cov0ps server is introduced hosting RtCW on OSG linux dedicated server.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (50)
.:Back to Top:. |
|
|
|
| STA-RTCW Shrub Season #1 Finals: -|SS|- v -nJ- |
| Posted on Tuesday, April 5, 2005 at 04:44:54 PM | :)Trinners |
|
| |
Congratulations to Syndicate Soldiers (-|SS|-) and New Jersey (-nJ-) for making it into the finals for STA-RTCW Shrub Season #1. The two will face off on Base as they fight for control the North and South Radar Controls on Sunday, April 10th at 21:30 EST (9:30PM). STA would like to Shoutcast the match. If you would be interested in shoutcasting, please contact either Gotcha! or myself) or pm us at #sta-wolf on irc.gamesurge.net. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (24)
.:Back to Top:. |
|
|
|
| Here comes the paintrain, kiddies.... |
| Posted on Saturday, April 2, 2005 at 11:38:34 AM | fX AlphA |
|
| |
Sup kids? Welcome aboard.
Read the following if you so desire, it is not my prerogative nor my inclination to influence anyone’s opinion by posting text on a screen.
Well, as you can see, I’ve been “caught hacking”. Good game.
First, let me publish the AlphaNeo biography… and for good reason…
MP Demo—man, I fucking loved it.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (290)
.:Back to Top:. |
|
|
|
| Who NOT da champs?! |
| Posted on Friday, April 1, 2005 at 07:56:17 PM | gisele |
|
| |
Taken directly from the CAL website:
Team Effect Removed from CAL
After fX AlphA being caught with an aimbot, all members of Team Effect have been banned from CAL-RtCW for repeatedly having hackers found within their ranks. Any members of fX who wish to return to CAL must first contact an Admin and receive clearance before joining a new roster or rejoining the league in any manner.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (179)
.:Back to Top:. |
|
|
|
| Upgrading Soon? It May Pay To Wait... |
| Posted on Thursday, March 24, 2005 at 04:02:02 PM | pissclams |
|
| |
According to sources at Intel, the company may begin shipping their dual-core processors sooner than expected. Originally set to be available by the end of June, the chipmaking giant has now up'd the ante on AMD and noted that they will ship even sooner than that. AMD's dual-core CPU's are not slated to become available until 3Q05. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (78)
.:Back to Top:. |
|
|
|
| TWL Shrub Season #2 |
| Posted on Wednesday, March 23, 2005 at 12:08:17 AM | -|ts|-Ulu4 |
|
| |
TWL Shrub Season #2 is here. Preseason will only be 1 week on March 31,2005. Regular season will start the following week. Let's see if Hairpulling OSP vets can goomba their way to another Shrub title or will the +saluting, weapon-swapping shrub-clan high jinks knock them off of their throne? So come join in all of the unlimited lives, panzer-passing shrub fun. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (43)
.:Back to Top:. |
|
|
|
| STA crowns Season #7 champ |
| Posted on Tuesday, March 22, 2005 at 05:43:13 PM | :)Trinners |
|
| |
STA would like to congratulate both NoX and Flatline for making it into the STA finals match. Both teams fought valiantly on Final Stand. In the end, Flatline took home the crown and became a 2x defending STA-RTCW champ. Kudos also goes out to Flatline for going undefeated this season. GGz guys.
The STA Admins would also like to give a shout of special thanks to Dynosaur from WolfTV for broadcasting the match. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (30)
.:Back to Top:. |
|
|
|
| Logitech Releases MX 518 "Gaming 'Grade" Mouse |
| Posted on Monday, March 21, 2005 at 06:45:29 AM | pissclams |
|
| |
Taken from our friends at Gamespot-
Armed with its 1600 DPI sensor and 16-bit data path, the Logitech MX 518 Gaming-Grade Mouse hopes to wipe the Razer Diamondback from the planet.
The MX 518 Gaming-Grade Mouse packs enough hardware to rival the only other respectable gaming mouse on the market--the Razer Diamondback.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (27)
.:Back to Top:. |
|
|
|
| Want to be a DeGenerate? |
| Posted on Monday, March 21, 2005 at 03:54:17 AM | TRAM Design |
|
| |
You bet you do! Version 1.0 of DeGeneration, a multiplayer modification to Return to Castle Wolfenstein, has arrived and is ready to download!
DeGeneration brings new weapons to Wolfenstein like the Snooper Rifle, FG42 and Tesla gun as well as features such as Parachuting, movable MG42s, Deathmatch, Assault and a gameplay that PC Gamer US called "Novel, Gripping and Fun". PCZone says "Classy maps, great atmosphere, enjoyable gameplay and more make this a top-class mod."
Here's what PC Gamer UK said about DG. "Take a flat-packed weapon of mass destruction, some gun-toting Axis and Allies types and one ingenious idea and you have the DeGeneration team play mod for Return to Castle Wolfenstein."
You can grab the mod and get more information @ TRAM Design - http://www.planetwolfenstein.com/tramdesign
http://www.tramdesign.net
See you on the servers!! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (6)
.:Back to Top:. |
|
|
|
| RTCW Highlights movie |
| Posted on Friday, March 18, 2005 at 03:36:58 PM | BiRdZ meshugr |
|
| |
Calling all players! Production is being started on a new movie to feature some of the great highlights of RTCW, from any season, from any team. Everyone and anyone is encouraged to send in their demos of team highlights, clutch moments, and memorable moments for the purpose of creating a historical movie to remember our favorite moments in wolf....
If interested, post here or find me on irc, idling in #birdcage or #teamburque |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (65)
.:Back to Top:. |
|
|
|
| A League for All Player Levels |
| Posted on Wednesday, March 16, 2005 at 10:20:34 PM | aS valor |
|
| |
Thorian's post on a new league got me thinking, something i hate to do, so i'll be brief. If there was a league where players, despite skill level, could sign up individually and then be placed on a team with 2 other randomly selected players, would anyone be interested? I have thought about making it an elimination tournament, so u play until you lose, inorder to keep things goin quick, and so people get a chance to play with a bunch of different players. Maps: i would really not change anything, except maybe att ctf_multidemo, a great map, especially for the small teams. Anyway, tell me if you think this could work, or if i should /uninstall :) |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (25)
.:Back to Top:. |
|
|
|
| This League Sucks! |
| Posted on Sunday, March 13, 2005 at 08:59:31 PM | Thorian |
|
| |
I'm pleased to announce the creation of a new RTCW league, properly titled "This League Sucks." People are constantly complaining about one issue or another regarding CAL, TWL, STA, etc. The purpose of this new league is to restore some level of control back to people who play the game without an overbearing organization breathing down its neck. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (128)
.:Back to Top:. |
|
|
|
| TsN to cover the RtCW One Day cup |
| Posted on Friday, March 11, 2005 at 07:31:46 PM | TsN Thunder |
|
| |
The Team Sportscast Network is proud to announce the upcoming RTCW Cup being held on March 20th, 2005.
Its a one day event featuring 16 of the top teams such as rewind, team9 and mi5 just to name a few. It is single elimination play meaning if you lose you are out of the Cup.
The maps that will be used are beach for round 1, base for round 2, village for round 3 and the finals will be on ice. The times are to be determined but make sure you set aside March 20th as a RTCW day.
You can find out more information about the Cup by visiting http://www.fast-frag.co.uk/RTCWcup and on quakenet in #rtcwcup. So dont forget to join Thunder as he will be bringing you live coverage of this event.
The Team Sportscast Network - We call the shots!!!
http://www.tsncentral.com |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (55)
.:Back to Top:. |
|
|
|
| Nerd News |
| Posted on Tuesday, March 1, 2005 at 09:29:51 PM | c[_]`Wippuh |
|
| |
It always seems that the MMOROFL guys are the dorkiest corner of geekdom. However, they've completely cemeted their spot with the new /pizza console command that will allow EverQuest II players to order a pizza for delivery! Old news perhaps, but this is the first major spotlight story we've seen actually confirming its existance (thought it was just a really well done joke :/).
Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (26)
.:Back to Top:. |
|
|
|
| Tyler, Come on Down! |
| Posted on Tuesday, March 1, 2005 at 05:45:04 PM | c[_]`Wippuh |
|
| |
You're the next busted punk on the MBL!
[PsB:2456 V00193951] bfc357a06dec0950f92e2143a600de14 "Aqua-FiSh" "67.174.62.108" MD5TOOL #9002 (deliverance.dll)
That looks like an aimbot and that ip goes back to your friend and mine, dT|Tyler or Surrender on Aqua's roster.
Personal attack season on Tyler is now open... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (43)
.:Back to Top:. |
|
|
|
| Old school |
| Posted on Friday, February 25, 2005 at 02:40:46 AM | virus |
|
| |
=VODKA FRENZY= will be returning TODAY!! or tomorrow, to an rtcw game near you. The server will be 16 slots in DFW running a pub rotation with the maps that we all know and love. Give thanks to Colbanks, and other contributors on this one. Now we can frag like back in the olden days! Show the love and come play on it as soon as it's back up for action. Also, if you would like to support this server by donating money via paypal go to #banksbuddies and pm Colbanks :D |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (48)
.:Back to Top:. |
|
|
|
| OSP Emotion |
| Posted on Thursday, February 24, 2005 at 04:02:50 PM | c[_]`Wippuh |
|
| |
In a movement that all OSP'ers may unify behind, Hairpullers (#hairpullers on gamesurge) meet up with asf tonight in the finals of TWL's first ever Shrub league. Pissclams and crew looked to have started out in Shrub for some fun, but the pure shrub teams have made it personal with some mad smacktalk! Since then Pissclams has been throwing bows left and right in the TWL forums! Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (38)
.:Back to Top:. |
|
|
|
| Calling all DeGenerates! |
| Posted on Monday, February 21, 2005 at 03:58:47 AM | TRAM Design |
|
| |
DeGeneration v1.0, the team based mod for Return to Castle Wolfenstein, is being released soon and in addition to all the goodies we brought you with the beta we have a whole jolt load of new goodies for you!
Feast on this:
- 20 new maps totaling 30 including Base & Beach maps DeGenerized!
- Enjoy all new objective types in Assault style gameplay!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (17)
.:Back to Top:. |
|
|
|
| Help bring back RTCW to qcon 2005 |
| Posted on Friday, February 11, 2005 at 03:32:49 PM | tektonic |
|
| |
After reading a few comments, I started thinking
lets try to do what we can to get rtcw back into qcon 2005
i saw a post on the qcon forums with the competitions director asking people their thoughts
heres an excerpt from an email i sent their director of competitions
...
Last year, qcon 2004 kind of shut the door on the RTCW and ET community.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (36)
.:Back to Top:. |
|
|
|
| Forum Game Saturday?!?! |
| Posted on Friday, January 28, 2005 at 03:20:41 PM | c[_]`Wippuh |
|
| |
Many of you weren't around when the Forum Game Fridays were rocking hardcore on planetwolfenstein.com. However, there's been recent developments and there may be a forum/planet-rtcw.com game thrown this Saturday night in the oldschool theme like Forum Game Fridays and Friday Night Madness. Just on Saturday night before everyone goes out.
Is there any interest in this? Should we fire up Swingline and throw an organized passworded pub till the wee hours?Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (72)
.:Back to Top:. |
|
|
|
| Help Wanted - WTV |
| Posted on Wednesday, January 26, 2005 at 07:43:28 PM | pissclams |
|
| |
It still seems as though there's interest each week for Wolf TV coverage of CAL's Match of the Week as well as some TWL, STA, and of course the tons of good match ups that occur in each season's playoffs.
Unfortunately right now I don't have enough help to cover the various events and so I'm looking to bring in a couple peons to help with the effort.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (39)
.:Back to Top:. |
|
|
|
| Xfire and PB |
| Posted on Friday, January 14, 2005 at 04:50:33 PM | c[_]`Wippuh |
|
| |
From planetwolfenstein.com...
"Even Balance Inc. has confirmed that the recently released update for the Xfire instant messaging program has triggered PunkBuster Violations #90003 and #90011 when the chat overlay system is used while playing on a PunkBuster enabled server in OpenGL mode. Xfire has released a v1.31 update to correct the problem on their end. PunkBuster admins are encouraged to give players receiving either of these violations (since Dec.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (17)
.:Back to Top:. |
|
|
|
| Looking for a Team? |
| Posted on Friday, January 7, 2005 at 04:29:57 PM | Thorian |
|
| |
People seem to think there is nobody left to recruit for teams for the next season. I know this is not the case as I see lots of tagless people hanging around on IRC and on pubs. I have also seen a few people quit teams because they cannot field enough to play in scrims or matches. All this does is shrink the number of teams playing, which is bad for competition, as those players then join established teams.
I propose having anybody not currently on a team wanting to play in CAL to respond to this news topic. Those teams without enough players then know who you are, and hopefully will choose to recruit over disband. Otherwise we won't make it through the season, which would suck. Thanks. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (17)
.:Back to Top:. |
|
|
|
| Stock News |
| Posted on Thursday, January 6, 2005 at 05:02:03 PM | c[_]`Wippuh |
|
| |
***PLEASE PAY ATTENTION***
The portfolios from last season have been reset. This means that everyone has the same $10,000 to start buying stocks for this season. However, there are still some teams not registered, so you may not see their stocks listed. If you are one of these teams, please register your team (admin > sign up your team).
DO NOT register your team if you know it has been registered before.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (14)
.:Back to Top:. |
|
|
|
| Interviews anyone? |
| Posted on Wednesday, January 5, 2005 at 04:13:55 AM | Mortal :o |
|
| |
I noticed some people wanting some more interviews. I would be pleased to interview someone of relevance if you give me some names. Please don't nomminate yourself since you will be disqualified :). I was thinking of interviewing more modern players to get a larger perspective of some of our communities finest as of now; not then :). Any names would help, Thanks! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (88)
.:Back to Top:. |
|
|
|
| r$f/Team Evolution Calls it quits |
| Posted on Saturday, January 1, 2005 at 01:30:37 AM | HellbenT |
|
| |
I am sad to report this news. Team Evolution (r$f) due to an unfortunate circumstance will no longer be seen in RTCW... Eagle started up this clan 3 years ago when he broke away from UsA, and they have been in RTCW for the last 3 years, and in league play for the last 2. I was able to build a friendship with a lot of people, and I actually had a lot of fun in r$f...I hope all of you in the community give props to Eagle if you know him, or see him around from time to time...Eagle...you will be missed by all that know you, and I hope you, and yours get back on track...Evolution-Gaming does however continue on in other games... GG's Eagle, and Jackal I will miss you both, ans so will many! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (58)
.:Back to Top:. |
|
|
|
| STA-RTCW Shrub League Season 1 - The Action Begins on Jan. 9th! |
| Posted on Saturday, January 1, 2005 at 01:29:58 AM | Gotcha! |
|
| |
STA is pleased to announce that we are ready to begin competition and the start of Season #1 for our new STA-RTCW Shrub League. Configured to run as a 6v6, SW mode, limited lives (6) and no panzer competition, STA has scheduled this League’s match play for Sunday nights at 21:30 EST (9:30PM) and will begin the first of 8 Regular Season maps on January 9th, 2005. This 8-week season will be followed by playoffs and a ProBowl.
There is still time to register for those who have not yet done so.
To sign up or to find more information (configs, maps, schedules, competitors) please visit us at the STA-RTCW Shrub website located at: http://base.sta-league.org/shrub. (Note: Teams may join through Week 4. Teams that participate in 60% of the regular season will be eligible for playoffs.) |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (7)
.:Back to Top:. |
|
|
|
| te_Escape by Refuse. |
| Posted on Tuesday, December 21, 2004 at 09:15:57 PM | -doNka- |
|
| |
Refuse(damn euro) has updated his map "Escape" a little bit, here is a quote from swertcw.com:
Refuse is once again releasing te_escape this time with some updates.
I looked at it myself a couple of weeks ago. It's made of the first level single player map so it looks esthetically pleasing, at least, not like many other custom maps. I ran around for a while, and I found that moving on the map is easy and somewhat natural, that, again, only comes with ID creations. Long story short, I think this one really deserves a try compared to many others that are currently under consideration.
Read and Download
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (42)
.:Back to Top:. |
|
|
|
| Team Evolution |
| Posted on Thursday, December 16, 2004 at 09:50:08 PM | HellbenT |
|
| |
Hello this is Hellbent from Team Evolution...We are sponsored by Evolution Gaming, we wanted to have a new place to pub 24/7 on a server that will cycle through maps. Do any of you remeber good ol' NooB CentraL well it's back....this is a 30 slot server set on rotation...Please feel free to come in and pub with us...We really hope to fill this server up so if you have any suggestions on how we can improve the server drop me line in this thread or check out the server @ 67.19.185.42:27970
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (116)
.:Back to Top:. |
|
|
|
| Texas Swingline: PB Updated |
| Posted on Wednesday, December 15, 2004 at 05:09:31 PM | c[_]`Wippuh |
|
| |
Due to the leagues (well, TWL at least and we assume that CAL will too) adjusting their pb cfgs, Texas Swingline has been updated too.
Changed:
pb_sv_cvar com_maxfps in 43 125
Added:
pb_sv_cvar r_nocurves in 0
pb_sv_cvar r_swapinterval in 1 0
pb_sv_cvar r_texturebits in 32
pb_sv_cvar r_depthbits in 32
Thanks for rockin' the Swingline folks!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (53)
.:Back to Top:. |
|
|
|
| Eurocup X The Final! iN vs iN! |
| Posted on Wednesday, December 15, 2004 at 02:26:30 AM | TosspoT |
|
| |
The time is upon us once again for what is Europeans premier RTCW online event and this Eurocup has been no different, it has provided us with excitement from start to finish, many of the oldschool teams made a return, but the final, is an all swedish affair!
First of all we have KiH, formerly known as iNfensus, the newer iNfensus mainly recruited post Quakecon 2k3 and very powerful, known for their trademark strafejumping and just beautiful aim these boys were the first to get to the final, but in the final they will meet none other than...emaho, formerly known as iNfennsus....This is the lan team and previous eurocup champions! Everyone of this team has played in a Quakecon final, and although they made hard work of beating Dignitas aka [ |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (56)
.:Back to Top:. |
|
|
|
| Flatline, STA Season #6 Champs! |
| Posted on Tuesday, December 14, 2004 at 04:09:45 PM | :+:VirUs047` |
|
| |
Congrats to Flatline for winning the STA Season #6 Championship!
Flatline, down 2-1, came back to win the match 3-2 in some extremely intense games on te_frostbite. Congrats to both teams for a well-fought match. Kudos also goes out to Tribal Valor for a good season. See everyone next season! Season will start after the New Year. Happy holidays to all!
Reminder, the STA Probowl is tomorrow, Tuesday, December 14th at 9:30 PM EST! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (26)
.:Back to Top:. |
|
|
|
| STA Season #6 Final ProBowl |
| Posted on Friday, December 10, 2004 at 11:28:00 PM | :)Trinners |
|
| |
With the regular season finally over and anticipation growing about the Season #6 Finals match between -Tv- and ___, it’s time to announce the end of season ProBowlers for STA! Tune in to Alpine and Game Radio’s Shoutcast of the ProBowl, which will be held on December 14th at 21:30 EST (9:30PM) for all the action.
Red Team
SSI BladeXp
[A-S-F]DropDead
___Opz
[].Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (74)
.:Back to Top:. |
|
|
|
| STA Launches a Limited Lives Shrub League |
| Posted on Wednesday, December 8, 2004 at 05:28:03 PM | :)Trinners |
|
| |
STA is pleased to announce the launch of a new RTCW league--limited lives shrub. We are currently gathering feedback for exact settings. At the moment, we are going with 6 lives, SW mode, and no panzers (to name a few). A preliminary config has been posted to the STA-RTCW Shrub forums for community feedback.
Matches for the league will most likely be played on Sundays at 21:30 EST (9:30PM). Season #1 will feature a 2 week preason prior to the Christmas holiday and will start next Wednesday, December 15th. The regular season will most likely begin on January 9th and will feature an 8-week season followed by playoffs and a ProBowl.
Sign up now on STA-RTCW Shrub's site at http://base.sta-league.org/shrub. Teams may join through Week 4. Teams that participate in 60% of the regular season will be eligible for playoffs.
In addition, STA is looking to add two new admins to our team for the new shrub league. If interested, contact Virus047 at virus047@sta-league.org or pm an admin on irc at gamesurge.net #sta-wolf for more information and an application. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (153)
.:Back to Top:. |
|
|
|
| STA Season #6 Playoffs - Week 4 (Finals) |
| Posted on Tuesday, December 7, 2004 at 04:52:41 AM | :)Trinners |
|
| |
Congratulations to -Tv- and __ for making it to the STA Season #6 Finals! Next Monday we crown the STA champ as the two face off on Frostbite. Can __ defeat the undefeated -Tv-? Whatever the outcome, it will prove to be an exciting match and will be available on WolfTV and Shoutcast. Don't forget to tune in! Good luck to both teams.
Match Date: Monday, December 13, 2004, 21:30 EST (9:30PM)
Map: Frostbite |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (37)
.:Back to Top:. |
|
|
|
| Thursday 12/2/04 kicks off TWL's Shrub league |
| Posted on Wednesday, December 1, 2004 at 09:09:44 PM | Hotniks |
|
| |
Thats right folks tomorrow kicks off week one of the shrub league. After 2 weeks of a successful preseason things are shaping up and the league is looking mighty promising and extremely fun. Even after a few clans disgust and withdrawal from the league following the announcement to go Unlimited lives with one panzer instead of limited lives we still have 25 clans joined up and ready to frag. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (31)
.:Back to Top:. |
|
|
|
| A Proper Goodbye |
| Posted on Monday, November 29, 2004 at 04:23:32 PM | Mortal :o |
|
| |
Recently, via TWL Forums, Rahl said he was retiring from his role as a TWL admin. With his large and lengthy contributions to the community and competition alike, his respected clan in Distress, and his reputation for being an all around good guy and panzerwhore; I wanted to pay respect to the man that made this game alot of fun for alot of us, and I know alot will miss him. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (87)
.:Back to Top:. |
|
|
|
| Idea for choosing maps for the new CAL season |
| Posted on Monday, November 29, 2004 at 04:21:12 AM | E-THUG |
|
| |
I'm not sure as to when the new CAL season will start, but hopefully the first regular season game will be after Jan 1, 2005. TWL did this kind of idea a few seasons ago. The idea is that you rank your favorite maps 1-10 (assuming there will be another 10 week season), and the 10 maps with the lowest number of points get to be the maps for the new season. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (68)
.:Back to Top:. |
|
|
|
| STA Season #6 Playoffs - Week 2 |
| Posted on Wednesday, November 24, 2004 at 08:48:49 PM | :)Trinners |
|
| |
Intense. That's the only way to describe Week 1 of the STA Playoffs. SSI dominated [].AkT. :) emerged victorious in tight matches with -nJ-. And [A-S-F] conquered =SK=. Next week's brackets have been posted. Time to protect the radars on Base. Good luck to all teams!
Match Date: Monday, November 29, 2004, 21:30 EST (9:30PM)
Map: Base
:+: vs SSI
:) vs ___
[A-S-F] vs [1st]
-Tv- vs {TBA} |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (16)
.:Back to Top:. |
|
|
|
| Insufficient O/S Privileges Kick Solution |
| Posted on Monday, November 22, 2004 at 06:35:01 PM | [+ oo] rampage |
|
| |
I keep getting kicked by PunkBuster for "Insufficient O/S Privileges". Is there some way to modify my system configuration to be an administrator equivalent from PunkBuster's perspective in XP Home, or for Pro Users that get their rights reset?
Download and run this file from any location, it will check for adware that stops you from being able to play on PB servers.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (13)
.:Back to Top:. |
|
|
|
| New Movie Project! |
| Posted on Friday, November 19, 2004 at 04:04:31 PM | NfluX |
|
| |
Ah the good ol' days... Back when no one could talk more shit than shogun...
Anyway, I've taken up a new video project of remembering those days, and showing the newbies what those days were like... However... I may need help from some of those old timers on demos. So, I have quite a few demos from the following teams:
Doctors
paradigm shift
clan Kapitol
Darkside
Hostile Inc.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (119)
.:Back to Top:. |
|
|
|
| wolf dream team... |
| Posted on Thursday, November 18, 2004 at 04:18:37 PM | caffeine |
|
| |
talking w/ slow ass donka on irc sparked a thought. if you could pick any starting 6 for your rtcw dream team who would it be? why?
rules: must be still active (meaning they participated this current season - no bullshit from 3 years ago), must be a NA player (canadian's are included). put em up suckas! my list to come soon...
post script: please don't use this thread as a "OH WOW HE FUCKING HACKS" dumping zone. vomit in your own toilet! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (122)
.:Back to Top:. |
|
|
|
| But PB is Dead... |
| Posted on Wednesday, November 17, 2004 at 09:31:42 PM | c[_]`Wippuh |
|
| |
Tuesday 11.16.2004 [2:30PM]
Version 1.120 of the PB Client for RtCW has been released to our PB Master Servers for auto-update and to our website download page.
Release Notes for PB Client v1.120:
* starting with this version 1.120, the PB Client now requires the game to be run as the administrator user or equivalent under Windows XP/2K (see our FAQ for more info).Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (32)
.:Back to Top:. |
|
|
|
| Splash My Nuts & Team Effect Battle On The Beachhead!! |
| Posted on Wednesday, November 17, 2004 at 06:27:37 AM | pissclams |
|
| |
Two teams are set to square off next week to determine CAL Main's Season 9 Champion and it's of little surprise to anyone that the two teams that most people expected to meet in the finals have made it this far...Splash My Nuts and Team Effect will match up next Tuesday night to determine this season's Championship on the uber classic map which has brought us so many great memories over the years, mp_beach. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (66)
.:Back to Top:. |
|
|
|
| STA Season #6 Playoffs |
| Posted on Wednesday, November 17, 2004 at 05:58:40 AM | :)Trinners |
|
| |
Sharpen your knife and polish the panzerfaust because Beach, Base, Ice, and Frostbite will be the playoff maps for Season #6 in STA:
Round 1: November 22nd - Beach
Round 2: November 29th - Base
Round 3: December 6th - Ice
Round 4: December 13th - Frostbite
Eleven teams qualified for playoffs. Instead of choosing the top 8 teams, an 11-team playoff schedule has been devised. Brackets are available on the STA-RTCW Web site.
In Week 1, Teams #5-11 (with the exception of #8) will face off on Beach. Teams #1-4, plus #8 will have a BYE.
[].AkT vs SSI
:) vs -nJ-
[A-S-F] vs =SK=
BYE: -Tv-, :+:, ___, [1st], {TBA}
GL to all teams and players! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| semi-final predictions |
| Posted on Monday, November 15, 2004 at 01:50:09 AM | caffeine |
|
| |
down to the final 4! the best 4 teams in wolf - duking it out on an intense doc run map. lots of communication and smarts needed to win here on the frozen tundra of lambeau field!
fx vs rabia
this could go either way. fx always, always has the capability to come out and 3-0 anyone in the league (including smn). fierce guns all across the board. has the sleeping giant finally woken?Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (102)
.:Back to Top:. |
|
|
|
| Teams Returning Next Season |
| Posted on Thursday, November 11, 2004 at 11:14:36 PM | caffeine |
|
| |
Well gang another season is coming to an end. Just thought I'd throw up a post so we can have an idea of who's coming back, who's not, who's recruiting, who needs a team etc...
Birds coming back next season (vengeance is done)...
Roster: lt goose, spud, mutha, paladin, mesh, pimplaya, eights, spetz, animal, and myself (I think I got everyone)...
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (103)
.:Back to Top:. |
|
|
|
| TsN Clanbase MoTW for 15/11/04 |
| Posted on Tuesday, November 9, 2004 at 08:41:58 PM | TsN Thunder |
|
| |
TsN is proud to bring you continuing saga of Unique.NL, GF.Move and rTg.
This is the match that rTg are the most interested in. If you recall, GF.Move beat them (rTg) on sunday night. then on Last Nights Clanbase MoTW, Unique.NL finished off Geeks With guns. that put them into 2nd Place in the playoff fight.
Now If GF.Move win next monday night. it's ttfn to the Eurocup for this season to rTg. this obviously is what they dont want. what they DO want is Unique.NL to win (taking first in the process) but leaving rTg in 3rd place ahead of GF.Move.
Who will win? Who Knows, but GF.Move have already been the underdogs in this playoff Position fight. can they do it again? Find out Next Monday Night on The Team Sportscast Network
http://www.tsncentral.com |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| This weeks RtCW Action on TsN |
| Posted on Sunday, November 7, 2004 at 09:17:40 PM | TsN Thunder |
|
| |
The Latest installment of the Clanbase 1944 night is almost upon us.
unique.nl v gwg face off against each other at 7:30 gmt (2:30 EST) Tomorrow. If unique.nl win tomorrow then they potentially could steal the second place from rTg. but that all depends on how well rtg play tonight.
As for tonight? well we'll have rTg facing off against GF.move (who play unique.nl tomorrow night). That battle is happening at 8PM GMT (3PM EST) Live on TsN.
Also dont forget our weekly CAL Main matchup on tuesday nights at 8PM EST as Team Exodus face off against Team Effect.
See you on the battlefield - http://www.tsncentral.com |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (45)
.:Back to Top:. |
|
|
|
| Texas Swingline pbbans.dat |
| Posted on Thursday, November 4, 2004 at 06:42:19 PM | c[_]`Wippuh |
|
| |
OS is now making public their pbbans.dat file available to the public. This file is a combination the following
- Texas Swinglines bans
- The leagues bans
- Punksbusted.com's master ban list
- pbbans.com's master ban list
If you would like to add a ban, please post in the comments and link to the appropriate Gamecloud screenshot that we have missed along the way.
Just dl the file from...
Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (70)
.:Back to Top:. |
|
|
|
| News from Citizen |
| Posted on Thursday, November 4, 2004 at 05:31:50 PM | c[_]`Wippuh |
|
| |
During a recent email exchange with Citizen about the current state of the Gamecloud servers, some interesting tidbits arose.
"Something is currently in development that will really change the way the servers are used in the near future. It is a good thing I think though. One small feature is that accounts will have to be created to even use the system. It is much fancier than just that though.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (31)
.:Back to Top:. |
|
|
|
| Toni Tony Tone |
| Posted on Monday, November 1, 2004 at 11:54:13 PM | c[_]`Wippuh |
|
| |
Besides being laws_69's favorite band, Tony Ray is the main man at Punkbuster and guess what...
"Hello,
I'll be glad to do an interview for your site.
-Tony"
You've got the next 24 hours to post intelligent and well formed questions in the comments. The best 5 or 6 will be thrown in and asked during the interview. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (48)
.:Back to Top:. |
|
|
|
| RtCW Returns To The Team Sportscast Network |
| Posted on Monday, November 1, 2004 at 05:44:14 PM | TsN Thunder |
|
| |
After an excruciatingly long wait, Return to Castle Wolfenstein returns to the Team Sportscast Network. We will have an awesome european matchup from clanbase every monday night at 20:00 GMT (21:00 CET, 3PM EST).
This week it's the turn of Unique.NL vs GF.Move (placed 3rd last season) to face off in TsN's RtCW Night.
So please join us in rejoicing that 1944 is still alive and kicking in European TsN.
For More information goto http://www.tsncentral.com
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (14)
.:Back to Top:. |
|
|
|
| STA Mid-Season ProBowl |
| Posted on Tuesday, October 26, 2004 at 04:01:33 PM | :)Trinners |
|
| |
It's been a great season to date! With only three weeks left, It's time to announce our mid-season probowl. Tune in to WolfTV on Sunday, November 7th at 9:30PM EST. The following is a list of the probowl selections:
Red Team
Captain: :+: VirUs047
1. :) Thresh
2. :+: Evil
3. [].AkT CompWiz
4. SSI Slingblade
5. ASF Highone
6. -Tv- Jaytee
7. [1ST]Jebus
8. -nJ- Abomb
9. =SK= GreatOne
10.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (46)
.:Back to Top:. |
|
|
|
| STA-RTCW looks to expand |
| Posted on Monday, October 25, 2004 at 02:37:33 PM | :)Trinners |
|
| |
STA-RTCW is looking into the possiblity of creating two additional divisions--ULTL Shrub and OLTL Shrub leagues. We would like to have at least 14 interested teams before creating a new division.
If you or your team would be interested in one or both of these leagues, please respond to the STA forums at http://wolf.sta-league.org.
If you have any questions, concerns, or suggestions, please contact Virus or myself on gamesurge.net at #sta-wolf. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (8)
.:Back to Top:. |
|
|
|
| week 10 predictions - chateau |
| Posted on Monday, October 25, 2004 at 02:33:56 PM | caffeine |
|
| |
the final week, playoff implications everywhere, gl die!
merc vs nj
nj forfeit for twl last week so i'm not sure where their priorities are. troll's pf on this map is very scary. should propell them to a victory...
merc 3-1
we happy few vs eggnog squad
as the holiday season approaches the dairy isle begins to fill w/ the sweet nectar that is eggnog.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (11)
.:Back to Top:. |
|
|
|
| Clutch |
| Posted on Tuesday, October 19, 2004 at 06:55:45 PM | c[_]`Wippuh |
|
| |
For the next Poll we're going to go with clutch and its definition to you in RtCW. One of the things that set truly great games apart from all the rest out there are the clutch moments and how they form the legacy of a game.
What are those moments to you in RtCW? Top 10 suggetions from the comments will be taken and put into the new poll. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (60)
.:Back to Top:. |
|
|
|
| Speakeasy's Gamecloud Launched |
| Posted on Tuesday, October 19, 2004 at 04:14:17 AM | pissclams |
|
| |
Some of you may have noticed that the Speakeasy servers have changed names! Don't fear, the servers are still the same great servers we've played on over the years, but now they are part of a new product line that Speakeasy has introduced called Gamecloud.
In a nutshell, Gamecloud will provide gamers a one stop shop offering Speakeasy DSL, GameDaemon game servers, Webhosting from NetFire.com, and File downloads from FileShack.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (11)
.:Back to Top:. |
|
|
|
| Anger leads to hate. Hate leads to Photoshops! |
| Posted on Friday, October 8, 2004 at 06:48:22 PM | c[_]`Wippuh |
|
| |
That's right! In order to get some blood boiling, lets get some friendly rivalries going! Feel free to photoshop the team snapshots of your opponents as you powerdowngrade them off the server before you destroy them on the server!
Rules = no images bigger than 600 pixels in width!
v57! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (30)
.:Back to Top:. |
|
|
|
| Just a Quick Reminder! |
| Posted on Monday, October 4, 2004 at 08:40:35 PM | gisele |
|
| |
Please don't even bother submitting news or articles regarding hack accusations or links to hacks. May we remind you that even if said news/articles are submitted, they will NOT be posted. If you have information about hackers and/or links to hacks or any other type of concerns of that nature, please contact your league admins and Evenbalance. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (25)
.:Back to Top:. |
|
|
|
| RTCW4Ever The movie. |
| Posted on Monday, October 4, 2004 at 05:05:11 AM | -doNka- |
|
| |
I don't know how many people around here browse through euro sites and how often, but let me point out the movie that came out a couple of weeks ago. I think it was not noticed in the NA community, and that's a shame because of what a wonderful movie it is. Made by the folks from clan @dvance(?), not really a famous clan around here. The skill level is not as impressive as it is in the raziel and intact movies, BUT the editing and the content of the movie make up for all of that. There are some wicked panzer shots, grenades, gun multi kills, and all of that is shown at it's best due to amaZing editing. The makers used a lot of free cam techniques as well as video enhancing effects and a lot more of those eye candy stuff.
Weight: 289 Kg
Download mirrors are here, I recommend. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (19)
.:Back to Top:. |
|
|
|
| Finalizing States Cup Teams |
| Posted on Wednesday, September 29, 2004 at 04:07:05 AM | ==*{SGT.DICK}*== |
|
| |
WE WILL NOT BE USING CLANBASE - YOU MAY STOP SIGNING UP - STAY TUNED
Read my comments below this news post:
Abi Normal, Jestah, Megatron, Deathcharms, EYES, GhostrideR, Walker, Orbyte, SplurGn, UnderDog, Predator, Kray-Z, Turdy, Vortex, Loyalguard
Maynard, Xero, Patton, aHIGHone, Neo, knifey, Crowbar, Sinister, Lakmir, Casino
yoeasy, Warchild, Gradius, Conscious, Casualty, BADMAN, SURGE, Falcon, cK-sirex, Private, Penguin
0ne, LaK, Blackhole, Del3, Princess, Pe4ce, Sgt. Death, Skoob, 8Ball, pov!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (63)
.:Back to Top:. |
|
|
|
| Clanbase.com RTCW States Cup Announcements |
| Posted on Monday, September 27, 2004 at 11:59:27 AM | ==*{SGT.DICK}*== |
|
| |
Okay, because this is the first time everyone is a little confused about States Cup procedures and what not. This is partly due to my work schedule being practically ALL weekend long. Not every team has a captain yet, but hopefully they will by Monday night. Some teams have made selections already. Some captains need to make theirs or are waiting to hear back from players to finalize. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (34)
.:Back to Top:. |
|
|
|
| This just in........ another PUNK BUSTED! |
| Posted on Monday, September 27, 2004 at 02:23:02 AM | Randy |
|
| |
Player name = xTc Synergy
Guid = 11c7ef501c8f188b0f094eb417f7a92d
Server = Anarchy I (pb auto screenshot)
Date = Sept 24th while scriming vs. -redline-
Picture 1 (top left)
notice the second axis coming up the strong hold ladder?
Picture 2 (top right)
notice the uniforms worn by the two axis in front of him. they look kind of weird.
Picture 3 (bottom left)
notice flag pole, explosion, and the blue signs on top of his team-mates?
Picture 4 (bottom right)
is it just me, or is that a see through wooden crate?
clicky
word of advise?? don't "try" a hack in a scrim/match/pub. Especially in servers with automatic screenshot enabled.
*** As soon as these screenshots were viewed by Anarchy admins, the leader of xTc was informed and they took immediate action by removing him from the roster** |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (126)
.:Back to Top:. |
|
|
|
| xTc = Totally gone? |
| Posted on Sunday, September 26, 2004 at 10:57:02 PM | c[_]`Wippuh |
|
| |
Just saw this being chatted about on irc, went to caleague.com and this was found posted...
"After repeated rule violations, Ecstasy has been removed from CAL Main RtCW. Any members of Ecstasy who wish to return to CAL must first contact an Admin and receive clearance before joining a new roster or rejoining the league in any manner. Any team found with members of Ecstasy on their roster will be suspended immediately from further competition." |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (36)
.:Back to Top:. |
|
|
|
| c[_]`Texas Swingline Update |
| Posted on Friday, September 24, 2004 at 08:20:14 PM | c[_]`Wippuh |
|
| |
In quick news, the Texas Swingline server has been updated. Due to certain people continiously fagging it up on Castle, it has been removed and replaced with TrenchToast. Good times while Castle lasted. Be sure to keep a look out as Castle may return for a few hours in the future :) Also, Chateau has been replaced by UFO.
In other news the Master Ban List provided by punksbusted.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (20)
.:Back to Top:. |
|
|
|
| One last update on P-RTCW for States Cup |
| Posted on Thursday, September 23, 2004 at 03:05:45 PM | ==*{SGT.DICK}*== |
|
| |
Just to let everyone know, announcements will now be made from our Clanbase-hosted site: http://www.clanbase.com/news_league.php?lid=1722 .
Format has been decided as well, it will be a 32 team affair with 8 groups of 4 teams each. There's more news on the site itself.
Thank you for the huge support we've received over the last few days, nothing can be a success without the players participation. Let's keep everything going and I hope to be able to announce a really good sponsor to hook the winners up with some hardware or even money soon as a reward for your support.
Again, put http://www.clanbase.com/news_league.php?lid=1722 on your favorites for updates from now on. Remember to register before the Friday evening deadline as well. Late signups will be allowed through contacting me on IRC if there's a good reason why (internet was down, vacation, etc.). |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (14)
.:Back to Top:. |
|
|
|
| Top 10 - Cal Main - After Week 5 |
| Posted on Wednesday, September 22, 2004 at 08:05:13 PM | c[_]`Wippuh |
|
| |
Huge drops and a few hidden surprises are the theme of this week's top 10 list. See where the heavy hitters have gone and who's making a name for themselves with some recent impressive wins.
(+/-) denotes previous spot in the top 10
- Out of the top 10 - dox
10. Vengeance (0) - Vengeance gets another win, but surprisingly drops a round to Cellular.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (23)
.:Back to Top:. |
|
|
|
| Bread Goes Stale... |
| Posted on Wednesday, September 22, 2004 at 04:33:16 PM | Sage-Buzzard |
|
| |
NEW YORK (CNN/Money) - Interstate Bakeries, maker of Wonder Bread and Twinkies, filed for bankruptcy court protection early Wednesday. In other news Bread won't be playing rtcw for a few months as he cannot afford to pay for his internet... We will be holding a event in the upcoming days to raise some money for Bread to help get him back on his feet. for the full story
CNN Story |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (24)
.:Back to Top:. |
|
|
|
| Clanbase RTCW States Cup Update |
| Posted on Wednesday, September 22, 2004 at 05:23:50 AM | ==*{SGT.DICK}*== |
|
| |
Just some general updates that need to get out to the public:
- Registration will close Friday afternoon at 5 pm EST. On Friday night, the states will be merged so that everyone is eligible to play for a state in contention. Also, the final format will be decided on. As of now, I still believe it will be a 32 team tournament. This means not everyone will be able to participate.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (80)
.:Back to Top:. |
|
|
|
| 12v12 - Large Maps....wtf? |
| Posted on Tuesday, September 21, 2004 at 09:49:21 PM | brujah |
|
| |
Yep! you heard me folks. Alot of hype is coming back to RTCW, with the return of teams such as Affliction, High Voltage, Extacy, along with the plan and maybe a permanent event, the States Cup. Its safe to say, things are looking pretty good for RTCW right now.
An addition Id like to throw out amongst you guys to stir the senses would be a fun-side to all the rigorous wolf competition.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (28)
.:Back to Top:. |
|
|
|
| PB, CAL Thursdays, Tourney |
| Posted on Sunday, September 19, 2004 at 09:14:26 PM | E-THUG |
|
| |
I don't want ANYONE to post anything OFF TOPIC at all, or else I will ask Wippuh to delete your post.
For PB, I need everyone to send an E-Mail to them with the following message.
Topic: PB Update needed for RtCW!
Message: Hello PB staff. I play Return to Castle Wolfenstein and recently there has been a drastic amount of cheats that are undetectable by PB out for anyone to download.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (40)
.:Back to Top:. |
|
|
|
| Affliction vs Exodus: Round 2 |
| Posted on Wednesday, September 15, 2004 at 03:29:27 PM | c[_]`Wippuh |
|
| |
Affliction and Exodus went to it 2-2 when a couple of Affliction's players got their ping's blasted in the final last half round. Therefore the game was discontinued and things looked like a forfeit win for Exodus.
Nope.
Affliction and Exodus will be replaying the ENTIRE match tonight on WTV! And this time Chrome gets his wish, the Super Mario Bros combo of Mario and Luigi will be in attendence!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (42)
.:Back to Top:. |
|
|
|
| Top 10 - Cal Main - After week 4 |
| Posted on Wednesday, September 15, 2004 at 03:16:51 PM | c[_]`Wippuh |
|
| |
Cal-Main came to a head last night with two quality matchups on WTV. One saw sMn continue their streak with a big win over eXe while the Affliction vs Exodus matchup ended in controversy.
Onto the top 10
(+/-) denotes previous spot in the top 10
- Out of the top 10 - Valor, Star
10. Vengeance (new) - Quietly, the Cal-O champion jumps into the top 10.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (45)
.:Back to Top:. |
|
|
|
| The Longest Undefeated Streak |
| Posted on Tuesday, September 14, 2004 at 09:43:28 PM | c[_]`Wippuh |
|
| |
The longest undefeated streak in all TWL is about to end. After two years at the top of the TWL 5v5 ladder, Hostile Inc is set to play their last match.
From ChaosLord
"Hostile Inc. will be playing it's last 5v5 Match vs asf this sunday, and we would like to invite all the TWL members to spectate on WTV if asf agrees. If you follow the TWL ladders, you know that Hostile Inc.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (16)
.:Back to Top:. |
|
|
|
| Poll: RtCW Disappointments |
| Posted on Tuesday, September 14, 2004 at 04:09:44 PM | c[_]`Wippuh |
|
| |
Going back to keeping this site on track, we've got a good flame worthy thread up in "Biggest Disappointment in RtCW History".
And the nominees are...
Rumble in the Desert, Continetal Domination Tourney, Abuse at Qcon 2k2, NARF at Qcon 2k3, RtCW's "expansion" - ET, Cyber X, Going from 7's to 6's, No RtCW at Qcon 2k4, D|S starters going to cK and Redman not staying retired!
Feel free to discuss =D |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (162)
.:Back to Top:. |
|
|
|
| Cal Issues News |
| Posted on Monday, September 13, 2004 at 03:14:54 PM | c[_]`Wippuh |
|
| |
CAL has posted some news on their site. The first bit speaks on MoTW's and the second deals with a lot of stuff including cheats! Here they are.
MoTW:
Starting in Week 5, Matches of the week will be announced by CAL at the time the week's schedule is released and covered through shoutcast and/or WTV. Each week there will be one MOTW per division.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (32)
.:Back to Top:. |
|
|
|
| Time for a new interview? |
| Posted on Saturday, September 11, 2004 at 03:42:38 PM | E-THUG |
|
| |
Sup kids, E-THUG reporting.
I've decided that it's time for a new interview to be done to some certain farmer out there, but I need your help in deciding who should be interviewed. Post here and tell me who you'd like to see interviewed, just don't post yourself. If you do, give me a good reason why. They don't have to be the biggest bow rager on the market, or the lowliest peon in the game, just who you'd like to see interviewed finally. Also, please don't post people who've ALREADY been interviewed. You can see who's been interviewed here --> http://www.pcloadletterwtf.com/forum/topic.asp?TOPIC_ID=1245
I'll tally up how many people want so and so, so of course, the one with the most votes will get interviewed.. that is if he/she agrees to it.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (104)
.:Back to Top:. |
|
|
|
| Beach Redemption ready and loaded to Anarchy I |
| Posted on Friday, September 10, 2004 at 03:18:08 AM | Randy |
|
| |
Hello there...
I was just downloading a few custom maps from rtcwfiles.com and came across this objective based map called Beach Redemption. After viewing the screenshots I figured I should give it a shot, and w0w what a map. I must say everything in the map is well thought of and i'm pretty sure it will be very fun to play with allot of people in the server since the map is big.
I would really give this map a try if I were you; hey what do you got to lose, just click the clickable below. Currently Anarchy 1 has the map uploaded.
Anarchy I : 69.9.169.2:27960
http://returntocastlewolfenstein.filefront.com/file/Beach_Redemption;15857
Please post your feedbacks and if you have any other custom maps in mind, tell moi :)
Randy
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (16)
.:Back to Top:. |
|
|
|
| Musical: Melong Raging Spree |
| Posted on Monday, September 6, 2004 at 05:37:53 AM | -doNka- |
|
| |
Well, hello again, my fellow gaymers. I' back from vacation and my studio Wolf Records doINK is up and running. And today I'm proud to present my second creation called Melon Raging Spree, w00t! I also have to say thanks to people who helped with all this: DA_G for technical setup, paladin for hosting my first masterpiece, and now nail for helping me to bring my second musical to you.
Enjoy: Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (51)
.:Back to Top:. |
|
|
|
| Old School Buzzer Beaters on WTV! |
| Posted on Friday, September 3, 2004 at 08:50:37 AM | Sir_Shaggy]NARF[ |
|
| |
I'm thinking of setting up a night of 'Classic matchups' on WTV and I need your help on selecting possibly 2 or 3 matchups to showcase. What I really want to showcase are 'nailbiters', 'buzzer beaters', 'hail mary's', etc... or a team down 0-2 and came back to win 3-2. Matchups that were really GG's!
What I need from the community is some suggestions on some 'Classic matchups'. Suggestions MUST have a demo available, either POV or WTV. Demos can range from any season, playoff or non-playoff. Here's some inspiration from the list of Champions. So dig through those old demos and submit your findings.
Date of broadcast will depend on the number of suggesions / submissions. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (51)
.:Back to Top:. |
|
|
|
| Top 10 - Cal Main - After week 2 |
| Posted on Thursday, September 2, 2004 at 05:36:41 PM | c[_]`Wippuh |
|
| |
Nothing like a top 10 list to really stir ze shiznit up. Here we go with an indepth look at a personal opinion of who's the top 10 teams participating in Cal-Main right now :o
10. Valor - They're slowly but surely building up the teamwork from merging some oldschool TV guys and the SoS llamas of Rahl, Reload and Spitfire. Look for drastic improvement as the season progresses.
09.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (50)
.:Back to Top:. |
|
|
|
| Stop the p2p Madness! |
| Posted on Wednesday, August 25, 2004 at 05:00:37 PM | c[_]`Wippuh |
|
| |
Thanks for all the offers, but the one and only E-THUG was first in requesting rights to post the schedule for CAL. We're assuming that Fuzion will still post TWL's. Expect them to be up for next week shortly. Buy your stocks now!
If you would like prediction rights, p2p either one of them, not Wippuh!
Congrats to b3e for winning last season's stock race! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| Friendly Reminder from WTV! |
| Posted on Wednesday, August 25, 2004 at 03:04:59 PM | Sir_Shaggy]NARF[ |
|
| |
A new season is about to start tonight and WTV will be here to cover any match you request. To request match to be shown on WTV stop by #gtv and the lovely WTV|Bot will take care of you. Simply type:
requestcam team1 vs team2 @ time EST league
The available cammer(s) will select one of the requests and inform you ahead of time if your match will be shown.
WTV has changed ports, so update your All seeing eye / Pathfinder to this:
/connect gtv.speakeasy.net:27965
Thanks to everyone who tuned in last season and good luck to all teams this exciting season 9.
***Yes, we know this is a day late, but it can be used for the rest of the season*** |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (6)
.:Back to Top:. |
|
|
|
| Oh NO! Speakeasy Ref Access Taken Away! |
| Posted on Tuesday, August 24, 2004 at 04:56:57 PM | c[_]`Wippuh |
|
| |
What will the asshat dm'ers do now? In a long needed call, Citizen has removed the ability to vote in refs on all of the Speakeasys. There's not really an explanation needed for why this was done, just a good, long overdue, change to the Speakeasys.
Thanks to Jaytee for getting this done! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (29)
.:Back to Top:. |
|
|
|
| TWL Propose 2 Map a Week System... |
| Posted on Monday, August 23, 2004 at 03:11:47 PM | c[_]`Wippuh |
|
| |
... No Soap and Berets Too ;p
Rahl, TWL's lead admin is proposing a radical change this season where TWL would adopt Clanbase's 2 maps each week system. There's not much feedback being given on TWL's forums, so we're posting the info up here. We all know that there's nothing but constructive criticism given on our comment sections!
So read on and lets give Rahl the feedback he desires!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (17)
.:Back to Top:. |
|
|
|
| RTCW movie REFLEXION |
| Posted on Monday, August 23, 2004 at 02:38:18 AM | mo*badass |
|
| |
Australias premier movie maker Demanufacturer has raised the bar once again with his new movie REFLEXION.

Quote from own-age.com
"Demanufacturer's Reflexion is a really nice look into some RTCW action all done with great camwork and thoughtful editing. With nice quality and some great effects used only when needed, this video is very entertaining. The cams get you right in the middle of the action, which were all from actual matches and completely unstaged. A very enjoyable, tasteful RTCW video that I would definately recommend checking out."
A top class movie that i highly recommend every rtcw fan check out.
Download: OzForces | FileFront
Own-Age article: http://www.own-age.com/vids/video.aspx?id=2558
Other movies by Demanufacturer and DINFW productions: http://www.dinfw.com/movies.php |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (16)
.:Back to Top:. |
|
|
|
| One Tier For All! |
| Posted on Friday, August 20, 2004 at 01:30:56 AM | sMn-s0r |
|
| |
---
From Cal website:
Welcome to CAL Main everyone!
That's right ladies and gentlemen, CAL RtCW has decided that in the best interests of all our RtCW teams we will institute a single tier system this season. Currently there are 46 teams signed up for CAL RtCW with 5 or more players on their roster and when looking at dividing those teams up between 2 seperate tiers based upon skill level, we found that although there may be a skill disparity between the best and the worst teams, the overwhelming majority of teams fall somewhere in the middle which will make for some fiece competition and a great environment for teams to increase their skills.
We look forward to continuing to serve our players in what is sure to be one of the most competitive seasons we've had yet.
GL & HF!!!
---
now anybody can be a main player! even me! haha |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (58)
.:Back to Top:. |
|
|
|
| CAL Season 9 bringing back some of the old schoolers? |
| Posted on Tuesday, August 17, 2004 at 12:34:18 AM | E-THUG |
|
| |
Sup kids. E-THUG here reporting on some of the old school teams that are looking to make a comeback.
First off we have Affliction (#affliction).
The roster consists of some pretty solid bowragers in Decka, Nail, Holly, Chrome, TB, and TTocs (nice q3 player). They might be looking into picking up a few guys (probably Ralph; kid said he retired but he's probably pulling a 3D|Bullseye).
Next we have xcal (#xcalibur).
Their roster is looking like their old one in Season 7. Lateralus, cade, MrsT, desolate, and probably Fuzion, and SniperT to complete them.
Then we have the famous Team Exodus (#team_exodus)
The roster looks like a renamed AGoggles but hey whatever. Elusive, Mario, Luigi, CL, Madness, Stiegl, Parcher, Morphine.
EoD is also making a comeback. (#eodclan)
They have a pretty nice roster and some solid teamwork in Lox, Nismo, Stormrider, ioKain, sIn, underdawg, ColBanks, vem, and a few others I dunno. Looks like they're recruiting.
Then there's Uprise (#uprise) and FearUs (#fearus). Not the same old school roster but it's still 2 good teams with an old school clan tag.
Finally we have the old school QCon 03 in Minions of getting raged by LQD ~ j/k (#minions.rtcw)
Their roster as of right now is looking like LuckyB, Imposter, Havoc, and possibly some of their other old school players like Reddevil? or even Kuniva? Whatever. Hope it works out for them.
This season is unfolding into one of the best seasons in a while. Competition for the top is gonna be violent if all these teams scrim hard and actually play out the season. Watch out for Wippuh's team though. They're definitely gonna be intimidating as always.
E-THUG out.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (87)
.:Back to Top:. |
|
|
|
| New cvars added to TWL's cfg |
| Posted on Thursday, August 12, 2004 at 02:49:26 PM | c[_]`Wippuh |
|
| |
"Two new pb cvar restrictions have been added, and the match.cfg has been updated in our download section. While the r_shownormals and r_showtris cvars are built-in cheat protected cvars, it has come to our attention that a wolf.exe file could be downloaded to circumvent automatic pb detection. Please make certain these 2 cvars are added to your server configs immediately. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (15)
.:Back to Top:. |
|
|
|
| c[_]`Texas Swingline Updated |
| Posted on Tuesday, August 10, 2004 at 03:34:56 PM | c[_]`Wippuh |
|
| |
The rotation and several other features of Texas Swingline have been updated! The new CAL/TWL pb config is in place and Wizernes has been added to the rotation! Also, due to popular demand the CP maps have been reduced from ABBA rotations to AB. The dual objective maps Wizernes and Depot have also been taken from A to AB.
ip: 69.93.101.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (27)
.:Back to Top:. |
|
|
|
| The Anarchy OSP .9 NY / NJ / WDC servers launched!! |
| Posted on Monday, August 9, 2004 at 05:31:23 AM | Randy |
|
| |
As August 06 we have launched 3 OSP servers located at New Jersey, New York and Washington DC.
Servers are running the new CAL configs.
The Anarchy OSP 0.9 -NY ******66.55.137.66:27960
The Anarchy OSP 0.9 -WDC *****69.9.169.2:27960
The Anarchy OSP 0.9 -NJ ******66.55.137.67:27960
Server rules:
The servers are there for rtcw. You can use it to pub or play matches/scrims.
Please respect each-other and keep it fun for everyone in the server.
**NOTE** If any of you think that one of these servers should have map rotation allowed, then post your feed back with your choice of rotation.
Any Feedback is welcomed.
Servers are maintained by:
n4d3r@msn.com (Randy)
xxqnzlunaticxx@aol.com (Chris)
Have fun.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (69)
.:Back to Top:. |
|
|
|
| Distress!RtCW :'( |
| Posted on Friday, August 6, 2004 at 09:28:00 PM | c[_]`Wippuh |
|
| |
There's been some really good guy teams out there, but today one of the most longstanding teams around called it quits in RtCW. Team Distress has stated that they will not be returning for for another season. Several of the players are free agents looking for new teams, but it seems that Rahl did not want to go through the stress of recruiting 3 or 4 more guys to cover up his lack of skills! Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (27)
.:Back to Top:. |
|
|
|
| Tentative STA Preseason Schedule |
| Posted on Friday, August 6, 2004 at 01:58:37 PM | :+:VirUs047` |
|
| |
Finals are over, champions have been crowned and now it's time to look towards the next season. We have picked out 3 totally new customs, as well as last season’s favorite custom, Tundra, to appear in this season’s preseason. Featuring a romp on two moving trains, a midnight doc run, a crazy complex assault, and of course some fun in the snow.
Our tentative preseason schedule for next season is as follows:
August 30th - Week 1- Complex Assault
September 5th - Week 2- Train Siege
September 13th - Week 3- Tundra Rush (Doc Version)
September 20th - Week 4- Night Raid
Again this is a tentative schedule. It’s possible there might be a few minor changes, so stay tuned. Download Links:
Complex Assault: http://team-crossbreed.net/maps/te_complexassault_fix.zip
Train Siege: http://rtcw.filefront.com/file.info?ID=14155
Tundra Rush: http://team-crossbreed.net/maps/tundra_rush_beta.zip
Night Raid: http://rtcw.filefront.com/file.info?ID=3706
Any questions or comments please PM an Admin at #sta-wolf on IRC or give us an e-mail. Thanks!
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (13)
.:Back to Top:. |
|
|
|
| Nightfall/RtCW Expatriots Shine at CPL |
| Posted on Monday, August 2, 2004 at 03:19:45 PM | c[_]`Wippuh |
|
| |
The CPL just conducted their Summer CPL event and several notable teams had old time RtCW'ers leading the way. Looks like all of Nightfall's boasting should have been taken seriously! He just walked away with a HUGE check from the CPL by defeating basically the Drs in CoD. Team 3d/Drs in CoD was basically an unstoppable beast that hadn't been bested EVER in CoD.
CoD
1st Place - u5 - LEADER - Nightfall!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (60)
.:Back to Top:. |
|
|
|
| CAL Pay to Play?!?! |
| Posted on Sunday, August 1, 2004 at 06:57:14 PM | c[_]`Wippuh |
|
| |
Over at ET-Center, they have the following posted.
From CSNation:
"In an exclusive interview with CS-Nation, CPL Owner and Founder Angel Munoz just confirmed that CAL, the Cyberathlete Amateur League, will be going to a pay to play format. The amount is unknown, although he did say it would be "something small like $5 a season." The full interview will be posted tonight on CS-Nation.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (43)
.:Back to Top:. |
|
|
|
| Photoshop Contest 2 - Successories! |
| Posted on Thursday, July 29, 2004 at 08:41:57 PM | c[_]`Wippuh |
|
| |
Ah yeah, you know another season is finally coming to a close when SI loses in the semifinals! j/k, it's been a good season and there looks to be some exciting matchups for the conference finals. That's good and bad. Exciting matchups = good. Only 4 teams left in each division = bad :(
So we're going at it with another Photoshop contest.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (66)
.:Back to Top:. |
|
|
|
| DeGeneration comes out TODAY! Do you have a server to play on? |
| Posted on Wednesday, July 28, 2004 at 07:28:35 AM | KolosoK)nG( |
|
| |
Sup people?
At #kolosok on gamesurge.net, people voted to convert our RTCW server to a DeGeneration server! As a beta tester, I got access to the mod before anyone else and uploaded it on the server. When the mod comes out, you have a new home to play at :). Do you play Wolf: ET? This will make you want to play RTCW all over again!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (50)
.:Back to Top:. |
|
|
|
| CAL Semifinals on WolfTV |
| Posted on Tuesday, July 27, 2004 at 07:32:12 PM | pissclams |
|
| |
Tonight on WTV, we will be bringing you all 4 CAL Semifinal matches!!! (although I think only 3 of them are being played)
Pro gold runners and stealhy ninjaneers will reign supreme in this week's matches which are being played on mp_village !!
CAL Open:
Suicidal Intent vs. Optical Experience @ 9:30 est
Vengeance vs. Team Silence @ 10:30 est
CAL Main:
Executives vs. Team Effect (forfeit?)
Raiders Coven vs.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (42)
.:Back to Top:. |
|
|
|
| GamingUK Interview: gwg|KyusS |
| Posted on Monday, July 19, 2004 at 01:29:21 PM | selfie |
|
| |
One could go on forever over whether Abuse or mTw invented the r2 defense. One thing is certain, Geeks with Guns were the first to employ a Radar 4 strat! Who are these crazy Norwegians and what has kept them going since 2001? Questions that needed an answer, so I ventured beyond borders and coastlines, tracking down geek{KyusS} in the Great North’s little brother Norway, country of fjords, treehuggers and WheelChairGeeks.
Wheel-What?!
Read all about it here! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (6)
.:Back to Top:. |
|
|
|
| Back to the future |
| Posted on Monday, July 12, 2004 at 03:40:51 PM | Randy |
|
| |
"The lads over at www.gamingcentral.co.uk are taking out the nails in from the coffin, and for one day only RTCW is back at its best with all of your favourite UK RTCW clans back in action!
Catch the teams from the oldschool as they return to the beaches, defend that comms tower, and batton down the hatches! One more time in true RTCW fashion! "
These euro people really come up with brilliant ideas! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (122)
.:Back to Top:. |
|
|
|
| Maps Announced! |
| Posted on Wednesday, July 7, 2004 at 05:23:36 AM | c[_]`Wippuh |
|
| |
Caught this in TB's channel and now it's confirmed. The following is the schedule for both cal and twl.
Playoff Map Rotation:
Round 1 - July 13th: UFO
Round 2 - July 20th: Ice
Round 3 - July 27th: Village
Round 4 - August 3rd: Assault
Seedings and brackets will be posted as soon as they become available.
A custom but no base? Curious indeed :/ |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (53)
.:Back to Top:. |
|
|
|
| iTG, Nok and EvilJohn |
| Posted on Tuesday, July 6, 2004 at 09:01:16 PM | c[_]`Wippuh |
|
| |
Radio ITG is going to do an interview tonight with two of the bigwigs over at qcon, Nok and EvilJohn. We've gotten word back from ITG that they will submit some ET/RtCW questions. So get out your thinking caps and pose your best questions in the comments section. We'll take the best ones and forward them to ITG, where hopefully they'll be asked. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (29)
.:Back to Top:. |
|
|
|
| Quakecon Tourney Announcement |
| Posted on Tuesday, July 6, 2004 at 01:39:36 PM | pissclams |
|
| |
Well folks, it's official, the Quakecon Tournament staff has finally made their official announcement this morning and it's not good news to many of us RtCW & Et players. This year's Quakecon Tournament line up consists of a 128 man Doom 3 double elimination Deathmatch tourney with undisclosed prizes, a 256 player Quake 3 Deathmatch tourney with $50k in prizes, and a 32 team Quake 3 CTF tourney with $40k in prize money. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (88)
.:Back to Top:. |
|
|
|
| Creative people, we know you are out there |
| Posted on Tuesday, July 6, 2004 at 05:22:16 AM | gisele |
|
| |
Please submit some new POW's! We are running out of decent ones and that is not good! If you don't submit some, I will post pictures of male celebrities that I find attractive (they will be wearing close to nothing, tbh)
Now, submit away! Los Los!
Get creative guys, sort of like what many of you did with the Bread pictures :P |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (12)
.:Back to Top:. |
|
|
|
| BYOC Rentals |
| Posted on Thursday, July 1, 2004 at 02:43:09 PM | c[_]`Wippuh |
|
| |
Interested in going to Qcon but dread luggin' your computer and monitor cross country? Well, Bit-by-Bit is here to help. They're renting both computers and monitors for the entire event.
Monitors
$45 - 17" CRT Monitor
$95 - 21" CRT Montitor
$75 - 17" LCD Monitor NEC LCD71V
$165 - 21" LCD Monitor NEC LCD2010x (has DVI input)
Computers
$180 - Dell GX270 P4 2.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (11)
.:Back to Top:. |
|
|
|
| Doom 3 Release Date Set |
| Posted on Wednesday, June 30, 2004 at 07:17:09 PM | c[_]`Wippuh |
|
| |
Old news for many, but several sites are reporting that Doom 3 will ship on August 3rd. Hrmm.. just a few days before Qcon, could this be the reason for the delay in announcing tournaments? Either way, with 42 days left till Qcon, it's looking more and more like anything beyond player organized tournaments in the BYOC is not capable of happening. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (18)
.:Back to Top:. |
|
|
|
| Oldschool Comes Back to Say Hi! |
| Posted on Friday, June 25, 2004 at 01:34:17 PM | c[_]`Wippuh |
|
| |
A certain Icelandic n00b armed with only with a knife showed up this morning in irc and wanted to say hi! He's promised a post on his escapades in Japan that includes hitting on schoolgirls, manga and the Japanese being really bad at English! So stayed tuned!
(07:16:16) (+Zydoran) hi sirs
(08:19:07) (@c[_]`Wippuh) wow
(08:19:12) (@c[_]`Wippuh) what's up Zydoran?Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (47)
.:Back to Top:. |
|
|
|
| GamingUK interview: BinaryBiscuit |
| Posted on Monday, June 21, 2004 at 02:01:22 PM | selfie |
|
| |
After almost a year of silence, this Shaolin-Productions crew member has released quite an impressive trailer for “Swadhistana – History of Hardcore”, the highly anticipated follow-up of the celebrated fragmovie “Disturbed”. Read all about it here as the famed BinaryBiscuit tells us everything about making thrilling gaming movies! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| RTCW Nations cup 4 results |
| Posted on Monday, June 21, 2004 at 01:05:46 AM | [CB]Ins0mniA |
|
| |
Today the final match, the match for the bronze final was (Sadly) forfeited by Sweden because they couldn't get enough players for the game against Russia.
But the final it self was played on friday and this was won by the Netherlands on mp_village and de_frostbite. So with that victory by the Netherlands, they have killed the winning streak from Sweden. Because they won the Nations cup 3 times before.
1. The Netherlands
2. Belgium
3. Russia
4. Sweden
Click this nasty link if you want to know more about the ClanBase Nations Cup IV http://www.clanbase.com/news_league.php?lid=1404 |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (8)
.:Back to Top:. |
|
|
|
| Hey Idiots! |
| Posted on Wednesday, June 16, 2004 at 03:44:02 PM | c[_]`Wippuh |
|
| |
Never have understood what is so hard about understanding a deadline but enough of you goons out there bitched and moaned about your own incompetence enough that Cal has opened rosters for today and tomorrow.
Don't miss it this time.
"I've been getting tons of requests from teams asking for one last chance to open rosters up, so here's your chance to find a home.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (79)
.:Back to Top:. |
|
|
|
| Sorry Bout Your Face |
| Posted on Wednesday, June 16, 2004 at 03:35:44 PM | c[_]`Wippuh |
|
| |
The Winner of the 1st ever Planet-RtCW.com photoshop contest is Endo! He tied Donka going into the finals, but in a runoff he ran away with 1st place.
Endo will now receive a can of spam signed by Bread and if he wants, Bread's newly pulled wisdom tooth (omgwtf!?!?).
"WINNER WILL GET MY MINT CONDITION WISDOM TOOTH, nEVER BEEN USED!!!. and the can Spam wippuh has. THIS TOOTH LOOKS LIKE A MOVIE PROP!!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (4)
.:Back to Top:. |
|
|
|
| Ask Warzone |
| Posted on Monday, June 14, 2004 at 06:29:02 PM | c[_]`Wippuh |
|
| |
Currently there's an interview out that we're waiting on. In the meantime, we're getting questions together to ask some n00b named Warzone. Since we have a little time till we send off the questions, we're asking for reader submitted questions. We'll take the best ones and pass them along to Warzone.
So, get to typing and remember the question marks! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (25)
.:Back to Top:. |
|
|
|
| Fired! |
| Posted on Tuesday, June 8, 2004 at 04:20:29 PM | c[_]`Wippuh |
|
| |
Well, we're tired of getting pm's on irc about what's up with the stocks. Carnal and Snowcrash were in charge of these, but neither seems to care enough to take care of them. So, we're gonna take care of them by removing their rights and ask anyone interested in handling the stocks to p2p Wippuh on the site!
Sorry for the mishandling of the stocks :( |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (13)
.:Back to Top:. |
|
|
|
| Punkbuster blocks wallhacks once again, Whee! |
| Posted on Thursday, June 3, 2004 at 06:59:39 PM | Da_G]NARF[ |
|
| |
Wednesday 06.02.2004 [1:30PM]
Version 1.089 of the PB Server for RtCW has been released to our PB Master Servers for auto-update and to our website download page. This is a maintenance release.
Confirmed this now detects the crappy wallhax peeps been using. Huzzah. Let there be pubbage without ph33r again! :P |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (94)
.:Back to Top:. |
|
|
|
| CAL announcement regarding the rest of the Season. |
| Posted on Sunday, May 30, 2004 at 11:25:14 PM | -opp bigbear- |
|
| |
Since I know a lot of you ignore what is posted on the actual CAL site heres something some of you may miss:
FROM CAL-Bert posted on the CAL site:
Demos = Mandatory May 29, 04 - 8:37 PM
Posted by CAL|Bert More news [ Add Comment ]
Starting this Tuesday, Week 4 of Season 8, all players will be required to demo their POV in matches until further notice. Team Captains can opt to have their Spectator record a Multi-View demo if they so choose. I will be collecting random demos from various teams/players; "forgetting" to demo is not a valid excuse for not providing one if requested, so make sure your auto-action is set.
I also want to take a moment to remind everyone about our policy on hacks/cheats. CAL has a ZERO TOLERANCE policy when it comes to cheating. Zero tolerance means that anyone caught hacking in a match, on a pub, in a pug, in a shrub, or at the Starbucks down the street, will be suspended, with absolutely no exceptions, period.
Please think about the consequences of your actions, let's continue to move forward having fun and playing with good sportsmanship.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (101)
.:Back to Top:. |
|
|
|
| 1st Ever Planet-RtCW.com Photoshop Contest! |
| Posted on Friday, May 28, 2004 at 07:37:45 PM | c[_]`Wippuh |
|
| |
The latest POW is definitely a winner, but there's so much more that can happen with Bread! Your job is to take Bread and insert him into as many different situations as best you can using whatever graphic program you want to (Photoshop, Gimp, Paint, etc...). Bonus points for Wolf related items! Post your results in the comments section! Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (161)
.:Back to Top:. |
|
|
|
| Viva la Grassroots! |
| Posted on Friday, May 28, 2004 at 04:29:38 PM | c[_]`Wippuh |
|
| |
The email campaign has been a success and it appears that PB will be coming through with an update! From the comments section of the previous news...
Posted on Friday, May 28, 2004 at 04:35:43 AM | [PBSTAFF]Stuart
Ahhh, please, I get the message...We haven't forgotten you, we'll have a few new detections out soon. Help, I'm been RtCW community mail bombed!
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (23)
.:Back to Top:. |
|
|
|
| Time to Fight Back |
| Posted on Thursday, May 27, 2004 at 08:10:06 PM | c[_]`Wippuh |
|
| |
With the current upswing in hacks becoming prolific, it's evident that something is needed from PB in order to eliminate the events we've seen over the past few weeks. So, in order to create a little positive pressure on Evenbalance, we're asking that everyone send them an email asking them to update their product in order to detect the lastest cheats! Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (277)
.:Back to Top:. |
|
|
|
| Smile, You're On Candid Camera! |
| Posted on Thursday, May 27, 2004 at 02:21:53 PM | c[_]`Wippuh |
|
| |
While the recent upswing in undetected wallhacks for RtCW/ET are alarming, there is one bit of pb that they can't hide from. That would be the automated screenshot feature! It appears that two high level RtCW players wanted to have some fun on clan q3's servers, not realizing that they were about to put their entire wolf careers in jeopardy! Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (408)
.:Back to Top:. |
|
|
|
| CyberX/TWL fraud will be dealth with soon enought :) |
| Posted on Thursday, May 20, 2004 at 02:28:26 PM | $ Inv s bl m n |
|
| |
Latest letter to me dated: May 17th 2004.
Thought it might make some of u happy to know that==> The U.S. Department of Justice will find out soon if TWL/CyberX were related or conspired together as/or criminal violations. Thomas J. Kneir, Special Agent in Charge or Federal Bureau of Investigation is personally looking into it. Anyone who wants to add there input should write additionally to my efforts (lucky I have friends in high places) to them at--> 219 South Dearborn Street, 9th Floor. Chicago, Illinois 60604.
Also feel free to write Patrick J. Fitzgerald- United States Attorney. Dirksen Federal Building: 219 South Dearborn Street, Fifth Floor. Chicago, Illinois 60604.
TWL|Zedsdead & his buddy TWL|Mitch (http://www.cyberxgaming.com/forums/forumdisplay.php?f=6) & Hill's can explain things to them soon :). I'll make sure to show how they were the led admin's of CyberX, obviously they aren’t the owners, but they had involvement. Let the investigators figure out who should be banned from Internet gaming/imprisoned. (Punished, ironic how they treated me & others, yet they are so much worse a public problem in reality) Anyone who has some good links showing how TWL was involved, post them here please I’ll forward proof to the FBI agent. Kinda rocks how the law works & they don't require u to have to type perfectly to prosecute criminals. Slow but effective do undercover investigators work =].
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (179)
.:Back to Top:. |
|
|
|
| Ask ChumChum |
| Posted on Wednesday, May 19, 2004 at 02:22:38 PM | c[_]`Wippuh |
|
| |
ChumChum has agreed to an interview. Upon accepting, we realized that we really don't have anything to ask this power 'grade. So in order to come up with 10 questions, we're going to take some reader submitted questions! Ask what you want in the comments and if they're good enough, they'll be passed along to ChumChum while he watches his soaps this afternoon. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (42)
.:Back to Top:. |
|
|
|
| Shoot Me Now! |
| Posted on Friday, May 14, 2004 at 07:25:14 PM | c[_]`Wippuh |
|
| |
Since the Most Missed post has turned into a "where are they now?" comments train, it's time to get a new post going in order to get a new poll. This time we get away from happy/fun polls and go with something more flame worthy.
Most annoying trends!
Some nominees include; people who retire, yet come back to play :o (the Redman syndrome) and players who corner camp and then brag about stats.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (274)
.:Back to Top:. |
|
|
|
| Excal Movie 2k3-2k4 |
| Posted on Wednesday, May 12, 2004 at 01:37:27 PM | FuZioN)nG( |
|
| |
The RtCW clan: Excalibur comes out with their first frag movie. The film consists of all scrims/matches from 2003-2004 in their run in Season 7 of Cal-Main.
The soundtrack is Linkin Park FREE - by request :)
Songs included:
Godsmack "Alive"
Disturbed "Prayer"
Static-X "The only"
Soil "Breaking me down"
AC/DC "Back in black"
#xcalibur @ gamesurge.net
#gamemovie @ gamesurge.net
http://www.own-age.com/vids/video.aspx?id=1769
Should be about 15-20 min download by a fast host #gamersgig
Plz post feedback good or bad ... thanks |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (18)
.:Back to Top:. |
|
|
|
| Exodus vs Trinity: A Dispute Settled |
| Posted on Wednesday, May 12, 2004 at 04:16:27 AM | Kuniva |
|
| |
A classic wolf dispute came up in tonight's match between Exodus and Trinity. The situation of course is where the times of both teams in a round are so close, that the console says one thing, but the "scores" screen that comes up says another. Which is right you ask? Well as it's been established before, the game, or "scores" screen that comes up, is the correct result.
The first such incident arose at qcon 2002. During a dispute at quakecon, rhea himself, said that osp is slower than the game by a fraction of a second. Therefore when a dyno blows an obj or docs are returned in game, the game is quicker to realize this, and brings up the "ALLIES WIN!" screen, while osp sees the obj being blown, or the docs being returned a fraction of a second later. This fraction of a second can make the game see a win, while OSP sees a loss, but the game is right.
I myself have been involved in this dispute twice in my wolf career. In season 2, I was playing for LoD in a game vs 82nd, and we won a round on village using the same ruling as rhea had dealt out at qcon 2002. The game was right, not the console, as 82nd had claimed. Bond settled it himself, giving us the win. The second time I came across this situation was in season 5(?) vs Counterfeit while I was playing with HCC just before qcon 2003. -$-'s dyno blew at what appeared to be 0:29 on the clock, but the game or "score" screen said they'd won, and console said we had. I immedeately knew what the outcome was and the entire dispute was settled immedeately.
In my stint as a CAL admin as well, this situation has shown itself to be a difficult problem, as both teams think they deserve the win, but once again I ruled in favour of the game or "scores" screen, because rhea himself has admitted that the game is right. There should be no dispute in this match on tTt's part, anyone who's been in rtcw for a while knows who won. I can only hope the CAL admins of today know who won too. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (188)
.:Back to Top:. |
|
|
|
| Week 2 Map Announced |
| Posted on Monday, May 10, 2004 at 08:03:13 PM | c[_]`Wippuh |
|
| |
Checking over at cal's site the following news has been posted!
"Due to the favorable feedback it received after preseason play, we've decided to use Tundra Rush Beta as the regular season map in Week 2. For those of you who need the map you can either download the correct version directly from any of the Speakeasy servers or from this link. Good Luck and Have Fun!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (15)
.:Back to Top:. |
|
|
|
| An RTCW Wedding |
| Posted on Saturday, May 8, 2004 at 10:15:47 PM | smoke|SCG |
|
| |
At 5:30 today, Brandon Howard, AKA Cheese (from WTV, Ae, Ballz, SteeL, and tD) will shed his bachelorhood and marry Jennifer Bogardis, AKA Chix0r (from 502nd, Ballz).
The two met at Quakecon 2003 and have finally decided to tie the knot :) Best wishes to one of the coolest guys I've ever met in RTCW and congratulations! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (37)
.:Back to Top:. |
|
|
|
| Happy Poll Up! |
| Posted on Friday, May 7, 2004 at 03:15:17 PM | c[_]`Wippuh |
|
| |
The new Happy Poll is up after Tundra_Rush won the week 2 map poll. This poll focuses on the person/group that has had the most positive contribution to the community. And the nominees are...
- Da_G for his GLARF cfg and for leading NARF to so many Cal-M titles when wolf was supposedly dead :o
- Rahl and the TWL admins for providing an alternative to Cal!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (10)
.:Back to Top:. |
|
|
|
| Quantum Nova |
| Posted on Thursday, May 6, 2004 at 08:56:44 PM | Gizmo |
|
| |
If most of you haven't noticed, we recently switched our *-center sites onto a new web hosting provider. The main reasoning behind this was to make it faster and more secured for the visitiors. We're sorry for the short downtime the other day, and hope not too much information was lost during this.
I'd like to personally thank BlackJudas for providing the web hosting for our websites. I'd also like to promote his web services.
For a small price of $9.95 a month you can have the Ecomony package which has the following features:
($9.95/month)
• 3GB/mo Transfer
• 50MB Diskspace
• 10 User Accounts
• Control Panel
• Virtual Private Server
• Webmail Access
• Integrated File Manager
Plus Many More Features!
For those who need additional space or more features theres the Deluxe package which includes the following:
($18.95/month)
• 10GB/mo Transfer
• 200MB Diskspace
• 30 User Accounts
• Control Panel
• CGI Allowed
• Domain Aliasing
• Virtual Private Server
• MySQL Database
• Webmail Access
• Integrated File Manager
Plus Many More Features!
You can visit Quantum Nova here.
You can get ahold of BlackJudas on IRC.Gamesurge.NET: #teamballz |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (13)
.:Back to Top:. |
|
|
|
| Stocks, the Richest and Matchup Admins |
| Posted on Wednesday, May 5, 2004 at 09:49:30 PM | c[_]`Wippuh |
|
| |
A new season is starting and it's time to put the call out for new Matchup Admins! This work is very timeconsuming (30 mins or so for each div you do) but is the work that dictates the stocks. If Booch wants to do CAL again this season, he gets it, but otherwise we're looking for another to do that, and someone to do TWL if there is interest. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (36)
.:Back to Top:. |
|
|
|
| Happy Lil' Poll |
| Posted on Tuesday, May 4, 2004 at 07:08:23 PM | c[_]`Wippuh |
|
| |
After the outrage of how traumatizing the last poll was for everyone, it's time for a happy lil' poll. One poll to do nothing but spread love and happy thoughts for all of the readers on the site. In order to make it unbiased, the readers will nominate the canidates in the comments on this post. The poll will go up later tonight!
Topic: Player that has contributed/done the most positive stuff for RtCW.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (41)
.:Back to Top:. |
|
|
|
| Most Annoying Up For Grabs! |
| Posted on Monday, May 3, 2004 at 03:34:11 PM | c[_]`Wippuh |
|
| |
A new poll is up and this time it's for all the marbles. All the annoying marbles that is! It's time to vote on the most annoying poster of Planet-rtcw.com. That one person who just makes you cringe when you see that they've posted in a comments section :o
And the canidates are...
Wippuh, Invisible Man, Spec Opz, Scarface, v!king, laws, Aphrodite, Dimmak, Astro and Pingan ;p w00t!!11 |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (94)
.:Back to Top:. |
|
|
|
| Cal Suspends Redman and Crack |
| Posted on Thursday, April 29, 2004 at 07:47:56 PM | c[_]`Wippuh |
|
| |
Just spotted this over at planetwolfenstein.com, checked it at caleague.com and it's all true.
"It is unfortunate that we are forced to announce the suspension of two players for portions of the upcoming season.
Redman has been suspended for 3 regular season matches due to joining and disrupting a CAL playoff match with spectator spam. Any team accepting Redman on their roster must notify the CAL admins.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (98)
.:Back to Top:. |
|
|
|
| New Poll and Interview Update |
| Posted on Thursday, April 29, 2004 at 03:35:31 PM | c[_]`Wippuh |
|
| |
There's a new poll up! This one is dealing with which custom map deserves a spot in the regular season rotation! The nominees are...
PredProject, Tank, Infamy, Pacific, Tundra Rush, The River, Base2, Axis Complex, KungFuGrip and NarfPractice!
In other news, there are 3 interviews currently sent out!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (19)
.:Back to Top:. |
|
|
|
| Warri0r's Info Off? |
| Posted on Tuesday, April 27, 2004 at 03:24:51 PM | c[_]`Wippuh |
|
| |
Warri0r has gone on to say that RtCW would NOT be at qcon this year. Saying that Doom3, Q3ctf, Q3cpma and ET would be the games :o However the following post turned up in the comments section.
"This information is wrong. Whoever told you this has definitely played you. I'd love to know who this supposed "inside source from QuakeCon" is though. Next time give credit for rumors.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (71)
.:Back to Top:. |
|
|
|
| RTCW News Radio |
| Posted on Tuesday, April 27, 2004 at 02:35:08 PM | -x-cKyAs$ |
|
| |
Im going to take up warchild's idea posted in the recent articles. He has an idea for a radio show, Based on rtcw. Here are some of the ideas for it.
-General Wolf News(what's happening around the community)
-Roster Changes and Updates (New Teams as well)
-Upcoming Players/Clans
-That week's matches with predictions and team discussions
-The previous week's matches with summerys and score updates
-League news with team standings and new league regulations(if changed)
-Player/Clan Interviews
-News on Tournys such as Qcon and the like
-General Wolf discussions
-Guest speakers and their thoughts on community happenings
I will be hosting the shoutcast server, But right now we are trying to think of a good name. Give me some ideas and let me know if youd be interested in doing this.Thanks
-the one and only cKyAsS |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (17)
.:Back to Top:. |
|
|
|
| Alarm: European Action Detected! |
| Posted on Friday, April 23, 2004 at 11:33:53 AM | -doNka- |
|
| |
Even though the European RTCW community has suffered tremendous losses some when around CXG prize cuts, there is still some action going on in various parts of the euro gaming medium. I was checking for some sources of RTCW activity on the European sites and I found a demo from CB Nations CUP SWE-UK. I couldn't resist, so I checked it out. So who do we see on team Sweden side...
LiNeup - civ, SoD!, Spear?, Summel, Hombre, and wuff(i hope you get the color theme).
The demo is dated Apr. 7th, but it's still full of rage nonetheless. iNswensus showed some sharp skills and descent action, though I don't believe they spend too much time preparing for the games. Anyway, the fact is: UK got rolled. So far SWE team went 2-0(8-0 rounds) in its group by defeating Italy and UK. If you are anxious to see how it was(UK), follow the link:
http://www.swertcw.com/default.php?c=download&id=577
There's one more match scheduled on Apr 25th, for more details visit www.clanbase.com Nations CUP section.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (55)
.:Back to Top:. |
|
|
|
| TWL Championship Results (Alpha and Beta) |
| Posted on Thursday, April 22, 2004 at 03:39:40 PM | Cypher |
|
| |
-I would first like to say great games to all that played last night. It was great to have been a part of it. Also, great games to all that played in TWL this season! Here are the results:
ALPHA
Intense Combat Forces vs. Elements of Destruction
ICF > EoD 3-0 (GGz EoD...excellent season fellas!!!)
BETA
Forgotten Kings vs. Next Generation
fK > nG 3-1 (Exciting match guys...well played!!!)
-Congrats to the Season 6 TWL Champions: ICF and fK!!! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (16)
.:Back to Top:. |
|
|
|
| New Poll |
| Posted on Wednesday, April 21, 2004 at 07:51:26 PM | c[_]`Wippuh |
|
| |
Since the Championship article is doing so well, there's now a related poll. There's been a lot of complaints lately that there's no place to discuss the polls, so here you have a news post complete with comments to flame away.
The poll? The best team to never win a title! And the canidates are; Amish, wSw, III, cK, FH, cF, tTt, LQD, LoT and Maximum Bow Rage!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (58)
.:Back to Top:. |
|
|
|
| Rahl, N00blar Player and Admin! |
| Posted on Tuesday, April 20, 2004 at 08:15:34 PM | c[_]`Wippuh |
|
| |
The goal of many an interview is to find someone with an interesting perspective to share. It happens to be by accident that we've really never gotten the outlook from an admin of the game. Definitely a point of view that is very different that the average player's. So we tracked down TWL's head admin for Wolf and asked him some questions for your reading pleasure!
Check it out and enjoy!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (3)
.:Back to Top:. |
|
|
|
| Coincidence for bk_forest/Fuel Depot |
| Posted on Friday, April 16, 2004 at 06:59:57 PM | c[_]`Wippuh |
|
| |
Recently there has been a new map released for ET called Fuel Dump, Spring Offensive which takes the original Fuel Dump and adds in some spring textures. Upon playing the map some old school RtCW players are saying that the map looks suspiciously like the RtCW SP map BK_Forest
Check out the screenshots and make the call! On the left, bk_forest in RtCW. On the right, Fuel Dump from ET.
Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (32)
.:Back to Top:. |
|
|
|
| TWL Playoff Finals! (Alpha and Beta) |
| Posted on Friday, April 16, 2004 at 01:34:51 PM | Cypher |
|
| |
-Well once again I am here because everyone else is lame and won't start a TWL prediction thread. Obviously I feel foolish doing this since I will be playing in one of the final games...but as I mentioned last time...."It's a dirty job, but somebodys gotta do it."
ALPHA
Intense Combat Forces vs. Elements of Destruction
Hrmmm....how the hell we made it here I don't know. I do know that EoD is a tough team and will be practicing. We, on the other hand are slackers and will be taking the more laid back approach. Base is personally my favorite map, but it isn't our best. Unfortunately we just played our best map, ice, and will have some possible difficulties on Base due to our lack of scriming. This is our rubber match with EoD since they beat us in CAL and we beat them in TWL this season. It will be an interesting match and I hope there will be WTV so everyone will have the privilage of making fun of my n00bness. With all that being said...
3-2 Glory Gobblers
BETA
Forgotten Kings vs. Next Generation
Wowzors! I was completely off last week for Beta! Show's how much I know. Kings really surprised me with an impressive victory over OsG. nG equally surprised me with a powerful win over Teh Birds (good season Birds, well played). I think fK is most definately the underdog going into this game which might be a good source of motivation. nG, like I mentioned last week is pretty stacked and has excellent individual players. However, Base is a very team-oriented map and will be interesting to see what happens. I definately will be looking forward to watching this match and I think it is a possible upset match. I might have to give the edge to nG just due to their experience, however watch for my bro Public for the Kings, with my l33t training he has developed into a great Glory Gobbler.
3-2 fK (I always love the underdogs)
-DISCLAIMER: Remember, I am a n00b....flaming me is pointless and illegal in 50 states (fucking Hawiians!) |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (58)
.:Back to Top:. |
|
|
|
| Important Reminder |
| Posted on Friday, April 16, 2004 at 12:32:58 AM | -doNka- |
|
| |
QUAKECON registration opens today 9PMEDT. Those who have never registered for Quakecon before must know, that the entrance is absolutely free, therefore registration for the event is extremely fast filling. Two years ago one had to literally refresh the registration page @ 8:59 in order to get a place. The disciplines are not announced yet, but if your team is planning to go I'd suggest having a couple of people at least to register all 6 to be sure. Good luck.
_ www.quakecon.org _ for more info.
Notice, the registration process is now split in 2 parts, first half consists of entering basic info into your profile, something that you can do right now, and the second part is actual signup. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (12)
.:Back to Top:. |
|
|
|
| Cal All-Star Voting |
| Posted on Friday, April 16, 2004 at 12:32:47 AM | Carnal |
|
| |
The semifinals are past us, and only the championships remain! To keep on schedule, the All-Star voting has been opened up for everyone. You'll have to create a simple login to vote, and results will be posted here when final. I expect to leave the system up for about a week, and announce the results later in the week after championships are over.
http://www.martinsports.net/rtcw
Let me know if there are any bugs or corrections that need to be taken care of. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (1)
.:Back to Top:. |
|
|
|
| New Pub Server in town |
| Posted on Friday, April 16, 2004 at 12:32:08 AM | FuZioN)nG( |
|
| |
New server has finally came around that needs some populating.
[Digital Hell][RtCW Pub Server]
The IP for the server is 69.56.200.130:30000 and it is located in Texas. Good pings all around. The server is hosted by www.gameforceone.com , or #gfo in irc.
Digital Hell is an online gaming community, which is rapidly growing throughout the community. Its holding the Checkpoint league, and is hoping to hold a RtCW tournament in the near future. It also has a few custom maps on it, including beach2, along with the new map PredProject. These maps can be voted in/out of the rotation, just post on the forums @ http://www.digitalhell.us
Other maps on the server include Assault, Base2, Beach, Chateau, Frostbite, Village, and others.
Digital Hell [-] #digitalhell [-] Rtcw-Cod-ET-BF:V-more |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (6)
.:Back to Top:. |
|
|
|
| Ultimate Checkpoint League |
| Posted on Wednesday, April 14, 2004 at 12:46:31 AM | warzone |
|
| |
After a scrim against OPP on trenchtoast I have decided to make a checkpoint league. There will be enough slots for 16 teams and your team can have any amount of players on it and may only use 1 ringer when it comes to match time.
You may join #checkpoint on gamesurge and message WARZONE with info for your team including team name and players. There will be 3 matches played before playoffs. The teams with the most wins will be forwarded to the playoffs. If you lose in playoffs you will be eliminated from the tourney.
Maps to be played are(in order)
1. Trenchtoast
2. Base
3. Depot
4. Ice
5. Destruction
6. Village
Remember this is for fun and please join up.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (13)
.:Back to Top:. |
|
|
|
| TWL Playoffs: Semi-Finals (Alpha and Beta) |
| Posted on Wednesday, April 14, 2004 at 12:46:08 AM | Cypher |
|
| |
-Despite the discrimination on this site against TWL, I thought doing a predictions article would spark some interest in an overlooked event. Enjoy :D
Alpha
Elements of Destruction vs By Way of the Gun
Well, not really sure if BwG is still scriming and practicing hardcore, but I can garuntee that EoD is (since their competing still in CAL Playoffs). Gonna be real tough to stop EoD with their solid teamwork so I give them the go.
EoD 3-1
Tribal Valor vs Intense Combat Forces
WEEEEEEEEEEEEEEEEEEEEE FOR US! Don't know bout TV, but we barely scriming at all :/ If we have enough come go-time, it might be close, but I am guessing if TV is scriming they will prolly blow us out da water.
Cypher = Glory Gobbler
Beta
Teh Birds vs Next Generation
Okay, so I don't even really know who Teh Birds are (don't even get what the hell their tag is). All I know is...they seem to be kicking ass and taking names and they beat Renegades pretty good in CAL Playoffs (I believe). Next Generation seems to be a bunch of solid players from different teams (looks pretty stacked if you ask me). However, despite their abilities I doubt they will be scriming very much since their Xcal players are focusing on CAL Playoffs (I could be wrong). Nevertheless, I give the win a strong up-and-coming team.
..|., 3-1
Forgotten Kings vs Old School Gamers
Kovert's a good guy and FK are a solid team, but (correct me if I'm wrong) I think they might have disbanded...don't know for sure but either way, I think OsG will prevail in this one due to their great teamwork and experience.
OsG 3-1
-Forgive my predictions for Beta, haven't followed their season very well so I am guessing quite a bit.
-Also, flaming me is illegal and all who vilotate will be prosecuted.
Thank you and have a wonderful day :P |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (18)
.:Back to Top:. |
|
|
|
| Jerry Rice Back? |
| Posted on Saturday, April 10, 2004 at 11:29:16 PM | c[_]`Wippuh |
|
| |
Just received this in a pm from Jerry Rice. We can't really confirm its authenticity, but it is interesting none the less, just because it is from the legendary Jerry Rice :o
Session Start: Sat Apr 10 18:16:55 2004
Session Ident: JerryRice
(18:16:55) Session Ident: JerryRice (theMan@davis.raiders.net)
(18:16:55) ((
(18:16:55) —› query with (JerryRice) (theMan@davis.raiders.net)
(18:16:55) —› total queries: 12342371 (~47.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (46)
.:Back to Top:. |
|
|
|
| Irc Virus? |
| Posted on Wednesday, April 7, 2004 at 03:11:16 PM | c[_]`Wippuh |
|
| |
Seen some people complaining about this on irc and there's a post over at swertcw.com on how to clean it up, so here's the info straight from them.
We got a new virus out, I just got rid of it. So if you have recieved and strange messages from me with url, please don´t click on it.
It looks like this, someone will talk to you and say something:
[c[_]Recon_Para]: hey
[c[_]Recon_Para]: sup..Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (7)
.:Back to Top:. |
|
|
|
| April 2nd - Lets Interview |
| Posted on Friday, April 2, 2004 at 03:31:33 PM | c[_]`Wippuh |
|
| |
Whew, luckily the crack staff of planet-rtcw.com went out to all you can eat oysters yesterday. This avoided the flood of pitiful April Fools news submissions that would have peppered the site and fooled no one. Nothing more painful than obvious April 1st pranks.
So, in celebration of the lack of llama April Fools posts, we're going to conduct an interview.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (134)
.:Back to Top:. |
|
|
|
| MADNESS - The Team Yakuza Movie by Madoshi |
| Posted on Monday, March 29, 2004 at 03:41:45 PM | kalamazoologist |
|
| |
SEE - the flamer that doesn't care whether he lives or dies!
THRILL - to the exciting skeet shooting action of UFO!
CRINGE - at the short-handed document pwnage!
That's right. All of Yakuza's CLASSICEST of moments from the past 3 seasons. Well, mostly from Madoshi. Hence, MADNESS. Almost all of the movie is match footage from my perspective.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (63)
.:Back to Top:. |
|
|
|
| All-Star Nominations |
| Posted on Saturday, March 27, 2004 at 08:48:56 PM | Carnal |
|
| |
Nominations have been closed and the list of nominees from each league are posted. The voting will open after the first round of playoffs are completed. Please take a moment to check this list out - players have been restricted to the class they were nominated most often for. I didn't edit anyone's name and can't keep up with who plays under what name for what clan anymore. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (59)
.:Back to Top:. |
|
|
|
| Playoff Pool! |
| Posted on Saturday, March 27, 2004 at 08:48:44 PM | fortunate|nayeen? |
|
| |
Hey I have decided to do a playoff pool for open and main leagues! The pool will be closed Tuesday at 7pm est. The person with the most correct picks will be the winner and will be able to choose from the following games: Halo, SoF2, LOTR-Return of the Kind, Battlefield 1942, Unreal Tournament 2003, or Mafia. I know crappy games but they are free and fun to mess around with. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (9)
.:Back to Top:. |
|
|
|
| CAL-Main Playoffs: First Round Matchups |
| Posted on Thursday, March 25, 2004 at 03:25:58 PM | sMn-s0r |
|
| |
Because I am a genius, I know the Cal Main Match-Ups first round.
Central
4. BWG vs 5.Scourge
3. Tribal Valor vs 6. Distress
Byes:
1. GameWyze (Will Play BWG/Scourge winner)
2. EOD (Will Play TV/Distress winner)
Atlantic
4. OPP vs 5. .Com
3. Excal vs 6. ICF
Byes:
1. Exodus (Will Play OPP/Com winner)
2. Darkside (Will Play Excal/ICF winner) |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (29)
.:Back to Top:. |
|
|
|
| CAL-Open Playoffs: First Round Matchups! |
| Posted on Wednesday, March 24, 2004 at 05:04:32 PM | Kuniva |
|
| |
Welp, the open season has drawn to a close, and here I am to tell you who you'll be playin first round! Ready?
First off, I got the word straight from CAL|Bert how the playoffs are workin. 8 Teams from East on one side, 8 Teams from Central/West on the other. So who makes the playoffs? well check it out for yourself:
East
1. Closing Time 10-0 20 Points
2.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (126)
.:Back to Top:. |
|
|
|
| All-Star Voting |
| Posted on Wednesday, March 24, 2004 at 03:19:30 AM | Carnal |
|
| |
OK, I've read enough about this for more seasons now than I can count, so I've decided to make a half-assed attempt at it. Below is a link to a site I threw up in my spare time at work this week. It's not pretty, but it should serve it's purpose. I opened the ability to nominate players from either Cal-O or Cal-M as an All-Star. Most things should be pretty clear. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (13)
.:Back to Top:. |
|
|
|
| CAL Playoff Maps and Dates Announced |
| Posted on Tuesday, March 23, 2004 at 02:58:26 PM | Kuniva |
|
| |
Playoff Map Rotation Announcement Mar 22, 04 - 10:41 PM
Posted by CAL|Bert
The following are the maps and dates for the upcoming Season 7 playoffs:
Round 1: mp_beach
March 30th
Round 2: mp_assault
April 5th
Round 3: mp_ice
April 12th
FINALS
April 19th mp_base
Brackets will be posted Tuesday night upon the completion of Week 10\'s matches.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (25)
.:Back to Top:. |
|
|
|
| Chris "Recon" Hill on cXg |
| Posted on Monday, March 22, 2004 at 08:27:47 PM | c[_]`Wippuh |
|
| |
Recon, from the disaster that was cXg, has officially spoken out in an article on esreality.com. Read the statement yourself as Mr. Hill asks for forgiveness and finds a way to mention nothing of the money promised to players who attended.
"This is Chris "Recon" Hill formally of Lan Tactics and CXG. I have spent many years playing CS and getting to know people from around the world who play this game.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (22)
.:Back to Top:. |
|
|
|
| Main Playoff Information |
| Posted on Thursday, March 18, 2004 at 11:27:33 PM | c[_]`Wippuh |
|
| |
Copied directly from CAL's site.
This season's Main playoffs will include 12 teams and will have 4 rounds. The top 6 teams from the Atlantic Conference and the top 6 teams from the Central/Pacific Conference will compete for the CAL Main title. The top 2 seeds from each Conference will receive a first round bye.
Seedings and Tiebreakers will be determined as follows:
1. Points
2. Wins
3.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (14)
.:Back to Top:. |
|
|
|
| osp clashes with shrub |
| Posted on Tuesday, March 9, 2004 at 09:12:10 PM | kodama |
|
| |
I kept thinking that someone should submit an article about the events that took place over the last few days between yakuza and the titans of shrub, 101st AE. As I (and everyone on my team) have been banned from their forums, I can't link all of the accounts of what happened. Plus, they edited all of our posts, and then nuked the threads all together. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (109)
.:Back to Top:. |
|
|
|
| Lamattitude: RTCW movie by C-Dirk. |
| Posted on Monday, March 8, 2004 at 03:48:47 PM | -doNka- |
|
| |
C-Dirk, a euro wolfer, has just recently released his masterpiece made of primarily n00bstick frags. Even though, the content of the movie might scare you away, I should say that it's actually very nice film with a descent soundtrack and very good editing. The author used Extended Demo Viewer in some parts of the movie, which made it a bit more entertaining. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (23)
.:Back to Top:. |
|
|
|
| Team Vote Pub Night |
| Posted on Wednesday, March 3, 2004 at 03:32:19 PM | Alpine! |
|
| |
[F1] Team Vote has decided to host a pub night on Saturday's. It's nothing special just a good time with a decent rotation. For those who were there a few days ago on WDC, and tonight on our server, look forward to something like that every saturday.
Server is wokka.org. /connect wokka.org . If there is a password it'll be something like "voteyes". Vent will be public for that night as well.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (9)
.:Back to Top:. |
|
|
|
| Speakeasy Servers Ref Free-for-all |
| Posted on Wednesday, March 3, 2004 at 03:31:31 PM | Kuniva |
|
| |
Upon a few incidents last night with some main teams using man power to ref themselves and then kick us from speakeasy chicago . I inquired about the policy on servers with CAL.
[KuNiva] hey arianna
[KuNiva] do you guys concern yourselves with servers anymore?
[KuNiva] bert said he can't do anything
[CAL-rtcw|Arianna] Yes Bert is right.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (27)
.:Back to Top:. |
|
|
|
| Because Wombat Says So! |
| Posted on Monday, March 1, 2004 at 03:57:56 PM | c[_]`Wippuh |
|
| |
Proving that he is actually doing something, Yogi has posted a neat thread on pw.com. It's an interview with Wombat of Doctors fame and has several little lines on the Qcon that the Doctors dominated. Click the link to read and see if you agree with what the cocky Dr.Wombat has to say.
"wombat: After we won QuakeCON, our team decided to stop playing, as did Abuse and cK.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (64)
.:Back to Top:. |
|
|
|
| CAL Shows :NK: the Love |
| Posted on Thursday, February 19, 2004 at 04:58:42 PM | c[_]`Wippuh |
|
| |
It's hard to remember if this has ever happened in the past, but CAL has stepped up and banned an entire team "indefinitely". Here's the quote from CAL's website.
"The Noob Killers have been suspended indefinitely from CAL Open because of a wallhacking incident which occurred with one of their players, :NK:Smoothie, during Week 4's match vs. Clan Pink.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (42)
.:Back to Top:. |
|
|
|
| Baaaaaaaaaaaaah |
| Posted on Monday, February 16, 2004 at 03:37:33 PM | c[_]`Wippuh |
|
| |
Got an interesting little p2p when checking the site this morning.
"Hey Man. I'm a little out of touch with the US RTCW scene. I've been trying to revitalize the UK scene and I'd like to cast noteworthy RTCW games from the US.
So, if you would like to keep me updated with uber game info - I'll see about putting said games on our bot and getting them casted.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (22)
.:Back to Top:. |
|
|
|
| Gamesurge Help |
| Posted on Thursday, February 12, 2004 at 02:32:19 PM | c[_]`Wippuh |
|
| |
If you're having problems connecting to IRC, the following info may be helpful to you. Since Gamesnet has merged with Gamesurge, it seems that you need the following to connect correctly from mIRC.
Just open irc, then go to the options > connect > servers and enter this info.
Description: gamesurge
IRC Server: irc.us.gamesurge.net
Port: 6667 |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (3)
.:Back to Top:. |
|
|
|
| Teamwarfare Goes Silly Euro! |
| Posted on Monday, February 9, 2004 at 09:09:00 PM | c[_]`Wippuh |
|
| |
There's no news being submitted (despite numerous pm's from people too lazy to write and submit their own articles/news?) and the crack team of genetically altered monkeys haven't found anything interesting lately. So, here's a tidbit from TWL going Euro on us all, in ET.
TWL has opened an ET ladder that is 6v6 and uses the Euro style of play.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (35)
.:Back to Top:. |
|
|
|
| CPL Doing it Again? |
| Posted on Thursday, February 5, 2004 at 03:56:50 PM | c[_]`Wippuh |
|
| |
The CPL, and Angel in particular, has a history of proclaiming games as the next big thing, holding a tournament for them and then watching as the game falls apart after teams play them and realize what crap they are (Ie, AvP2, ut2k3). The next victim seems in line with Halo.
CPL|Angel stated ""We have noticed that registration for this tournament is lagging behind all other tournaments announced for the summer event.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (27)
.:Back to Top:. |
|
|
|
| Rawr? Rawr! |
| Posted on Monday, February 2, 2004 at 03:26:01 PM | c[_]`Wippuh |
|
| |
The last week has been a busy one with lots of traveling, but the news will start up again for everyone to read. Any interviews, polls or articles that you would like to see, just say so in the comments section.
In the meantime lets talk about something we usually try to stay away from. ET. Gigolo and company are currently in the process of creating et-center.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (23)
.:Back to Top:. |
|
|
|
| New RTCW League |
| Posted on Sunday, February 1, 2004 at 08:53:43 PM | xil-redman |
|
| |
Their is a new RTCW league being made hosted by #gamingworldwide. Please support #egleague for info. The league will start up shortly. 5 idlers from each clan and your clan gets peon.
RTCW is in need of leagues to keep this gaming going, please support and make this league successful. We are also looking for admins to help run this league, pm {Gw2}aDDicT in #egleague channel for info.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (33)
.:Back to Top:. |
|
|
|
| Articles Go Boom! |
| Posted on Thursday, January 29, 2004 at 11:15:02 PM | c[_]`Wippuh |
|
| |
WooWoo! The pugs and demo articles have been deleted from the site. A comment basically summed it up by stating that it appeared that planet-rtcw's articles section had become a forum for people to post personal beefs and whine. That is not the case. If you want to do that sort of thing, take it to the forum so it doesn't waste space and the time of readers. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (15)
.:Back to Top:. |
|
|
|
| Movie Coming Soon But Need Help With Demos |
| Posted on Thursday, January 29, 2004 at 03:51:10 PM | Scarface |
|
| |
If anyone has some rage that wants me to put it in a movie i am making for rtcw i have gotten alot of demos from players but i need more i am doing all of the work all i need from the people sending the demos is i need them zipped i need the times of the action and i dont want no lame ass 2 man nades "s0r" and just your support im h Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (48)
.:Back to Top:. |
|
|
|
| PoW's, Polls and Perks! |
| Posted on Thursday, January 22, 2004 at 03:30:46 PM | c[_]`Wippuh |
|
| |
There's a current backlash about 'ownage' Pics of Whenever's, so we're making a call out there to all our Photoshopping members. Get those skills fired up and create some original works for the PoW!
The current bobblehead doll poll has stopped and Shogun's BobbleMelon with ElbowPads has won with 16.9% of the vote. Coming in at 11.9%, we had a tie at 2nd place.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (36)
.:Back to Top:. |
|
|
|
| cXg Press Release |
| Posted on Wednesday, January 21, 2004 at 06:00:52 AM | c[_]`Wippuh |
|
| |
There's news of a cXg press release on esreality.com. The intro was really well written and many a jaw will drop when they read the last lil' part.
The CXG released an official FULL press release with some very interesting details. In it they state they plan to hold 4 more tournaments this year including tournaments in Chicago, Berlin and two other cities and will feature national/international TV coverage.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (41)
.:Back to Top:. |
|
|
|
| Blame Canada! |
| Posted on Monday, January 19, 2004 at 11:29:01 PM | c[_]`Wippuh |
|
| |
In my continuing efforts to destroy Wolfenstein, the stocks and matches have been updated for the new season. This is a first ever attempt at this, so please be patient and report any problems you find. If the teams that have not submitted their team to the clan list, could do so, that would be great! Otherwise NCN (No Clan Name) is going to have a busy week. Blame Canada if anything goes wrong! Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (16)
.:Back to Top:. |
|
|
|
| The Final Match, Summ3l's thougts, win a Funcpad! |
| Posted on Sunday, January 18, 2004 at 06:36:16 PM | =X= Sea |
|
| |
The Christmas Cup 2003 Final: The Match, The Radioshow, The prizes!
Keep on reading since on this sunday, YOU have a chance to win a Funcpad 1030, watch some great WolfTV, listen to DeeAy and Trillian, hear Summ3l's experiences from the Cyber X Games
Tonight (or morning for you) The final between clan 535 (Germany) and a-Losers.MSI (Germany) is going to be played.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (9)
.:Back to Top:. |
|
|
|
| Cal-M Teams Named! |
| Posted on Thursday, January 15, 2004 at 10:35:31 PM | c[_]`Wippuh |
|
| |
While doing some research for a random post on pw.com it seems that Darkside couldn't be found in the Cal-O list. Upon rechecking, the Cal-Main RtCW teams have been named! 26 in all were assigned.
Cal-Main
BwG, C!@, Comm, Darkside, Default, dR, distress, eod, eXcaliber, HV, ICF, IW, kor, OPP, Perfect Drug, Scourge, s6, Suave, $, exodus, immortals, Ragin' Octopi, Turbo Cyborg Ninjas, TV, u5 and yZ |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (89)
.:Back to Top:. |
|
|
|
| New poll and a Request |
| Posted on Wednesday, January 14, 2004 at 03:21:24 PM | c[_]`Wippuh |
|
| |
The RtCW bobblehead poll is up and the 10 selections are in. You have to decide which bobblehead you would want. Is it ChaosLord on his Tractor? How about Pinggan, complete with incomprehensible speech or even Wippuh with his foot through a dead RtCW community? A Laws AND JulieBean set or if you're oldschool you could go with a Thorian with velcro clan tags or Shogun's special BobbleMelon elbowpad edition. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (9)
.:Back to Top:. |
|
|
|
| More Top10 updates |
| Posted on Sunday, January 11, 2004 at 01:30:45 AM | |
|
| |
After discussing it more the admins have decided to make additional updates to the Top10.
Clans will no longer be able to vote themselves in their Top10 list. At first this may seem like a bad idea but if you think it through you will realize that this eliminates clans being able to give themselves 10 points in the Top10. Thus there is less incentive to vote poorly.
Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (11)
.:Back to Top:. |
|
|
|
| CXG play day. |
| Posted on Saturday, January 10, 2004 at 10:48:35 PM | -doNka- |
|
| |
Finally, the update. Mike]narf[ if chattin' on IRC like crazy keeping his buddies informed, but I guess not all of the news go here.
The tournament itself was scheduled for 8am today in totally different location. There was no descent setup, not enough monitors, PCs locked up on wolf, and only 6 or 7 of them can connect to one server. Some PCs did not have wolfenstein on 'em.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (25)
.:Back to Top:. |
|
|
|
| Orange Smoothie Interview! |
| Posted on Friday, January 9, 2004 at 03:50:24 PM | c[_]`Wippuh |
|
| |
OSP is the most influential mod for competitive gaming around, and the work comes largely from one individual. Rhea has spent a lot of time working on the mod, yet we couldn't seem to track down any signifigant interviews on his involvement with RtCW.
We had to put a stop to that! Thanks to KITH for the help in setting this up. Locknar!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (4)
.:Back to Top:. |
|
|
|
| Top10 Changes |
| Posted on Thursday, January 8, 2004 at 07:42:00 PM | |
|
| |
After discussing it the admins have decided on a major change in how the Top10 works.
The new Top10 system is based on votes placed by clans instead of users. Each active (and verified) clan in a league will have the opportunity to vote for the Top10 for that league. Only owners of the clans may submit the clan's vote!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (17)
.:Back to Top:. |
|
|
|
| Exploit, again... |
| Posted on Wednesday, January 7, 2004 at 12:34:45 AM | -doNka- |
|
| |
Just in the previous post CAL announced narration of cg_FOV because somehow it allows a player to wallhack. To be honest, I have never realized it could be possible since i play with fov 90. But one thing i knew for sure: cg_zoomDefaultSniper was never restricted. If a person sets this variable to, let's say, 300 fov_wallhacking enters hardcore level. Of course he/she must be LT to be able to zoom that much. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (27)
.:Back to Top:. |
|
|
|
| #rtcwpugs - Pickup Game Lovin' |
| Posted on Monday, January 5, 2004 at 03:25:11 PM | c[_]`Wippuh |
|
| |
Mortal, along with help with several other RtCW lovers like Chilifiend, Rambo, Skeeter, Warrior and Valentine, has set up an irc channel dedicated to Wolf Pickup Game goodness! So far so good as the games are coming in at a good pace. 20 minutes is about the max seen as people wait, and even then they're on the ventrilo talking to the other players.
So join up to #rtcwpugs and join a game asap!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (16)
.:Back to Top:. |
|
|
|
| CXG Cancels Wolf:ET Tournament. |
| Posted on Friday, January 2, 2004 at 11:35:21 PM | prod1gy |
|
| |
Bad news for Wolfenstein players. Cyber X Gaming have cancelled their Enemy Territory BYOC tournament. There would hardly be anything startling in the news if not for the fact that the cancelation took place a week before the event and there was no official news about it!
Only five teams have signed up for the tournament.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (22)
.:Back to Top:. |
|
|
|
| Ask Rhea |
| Posted on Monday, December 29, 2003 at 04:53:25 PM | c[_]`Wippuh |
|
| |
With OSP .9 coming out, Rhea has graciously agreed to do an interview for the site! Trying to keep the interview different and interesting is tough, so we're going to take 5 or so questions submitted through the comments section and include them in the interview.
If you've ever wanted to ask Rhea something, this is your chance. Questions get mailed out tonight so hurry and post now! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (50)
.:Back to Top:. |
|
|
|
| 2v2 Tourney |
| Posted on Monday, December 29, 2003 at 04:16:07 PM | -x-mario! |
|
| |
After seeing most of the Speakeasy servers recently, there has been a lot of 2v2 and some 3v3 going on. So I decided to get some teams together for a little tourney that Warrior is going to help me sponsor. Its nothing big just 16 teams with simple 2v2 rules, like no panzers...ect. Anyways just seeing if anyone is interested pm me in IRC, #team_exodus, for more information and details. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (4)
.:Back to Top:. |
|
|
|
| Restricted you say? |
| Posted on Tuesday, December 23, 2003 at 12:21:04 AM | -doNka- |
|
| |
It’s been a while since cg_thirdperson was locked at 1. It didn’t seem like there really was that big of a deal back then, but some people figured out how to use this variable to exploit the game. It was locked, but was the problem solved? Not entirely. Besides cg_thirdperson there are two more helper variables cg_thirdpersonRange and cg_thirdpersonAngle. Cg_thirdpersonRange is the one that can still be used to cheat. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (16)
.:Back to Top:. |
|
|
|
| The 12 Days of CAL and Here Comes PanzerFaust |
| Posted on Sunday, December 21, 2003 at 09:14:20 AM | warzone |
|
| |
Here comes Panzerfaust!
Here comes Panzerfaust!
Right down Panzerfaust Lane!
Pingan and Baby and all their noobies
are spamming every game.
Noobs are crying, Pros are sighing;
All is quiet and dim.
Hang your guns and say your prayers,
Cause Panzerfaust comes tonight.
Here comes Panzerfaust!
Here comes Panzerfaust!
Right down Panzerfaust Lane!
He's got a tube that is filled with lube
for the boys and girls again.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (27)
.:Back to Top:. |
|
|
|
| Santa Has An MP40 |
| Posted on Thursday, December 18, 2003 at 09:59:28 PM | c[_]`Wippuh |
|
| |
And he wants his Xmas List stuck at the top of the compound on mp_ice back!
Those whacky guys over at WildWest continue to churn out some fun stuff for all of the RtCW heads out there with SantaMod! Nothing but different models for the Allied/Axis and Ammo/Health packs. The players now look like Santa in red or green and the ammo/health packs look like Xmas presents!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (14)
.:Back to Top:. |
|
|
|
| 2v2 North American Tournament Update |
| Posted on Saturday, December 13, 2003 at 05:27:50 PM | -a-WarRi0R |
|
| |
www.warri0r.net is almost completed and I would like for the teams that want to sign up for the tourny to do so. Visit the site for rules and email specifications to sign up. The bracket is done and though the links on the site are not fully functional yet, it should be done by next week. There will be prizes if I get 26 teams or more, so sign up! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (59)
.:Back to Top:. |
|
|
|
| BeavermanA Mails in the Answers |
| Posted on Friday, December 12, 2003 at 02:09:17 AM | c[_]`Wippuh |
|
| |
Several interviews have already been mailed out and all that is holding up their publication is a reply! So to kick off this stretch of interviews from the recent polls we have BeavermanA! One of the most feared, yet more quiet players around, BeavermanA has been receiving lots of praise from fellow players for a long long time, so it was due time we tried to ask him some questions about what's up! Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (10)
.:Back to Top:. |
|
|
|
| Bring on the Questions |
| Posted on Wednesday, December 10, 2003 at 08:26:55 PM | c[_]`Wippuh |
|
| |
The interview poll is over and the process of currently writing questions for Valdez is underway. Of course, there's no way that Valdez can be the only interview, so questions for the rest of the options are also being written. If you have anything you would like to ask, pop it into the comments and maybe it will find its way into the interview. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (53)
.:Back to Top:. |
|
|
|
| Giving Gamers |
| Posted on Tuesday, December 9, 2003 at 05:15:34 PM | c[_]`Wippuh |
|
| |
If you manage to put down your potato masher for more than 15 minutes and venture out into the world, you'll notice wreaths hanging from all the light posts down Main Street and Da Bears eliminating themselves from the playoffs. What does this all mean? It's the holidays of course!
TsN is running an event to collect a modest $1000 for the Red Cross during the Xmas holidays.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| Poll Is Up |
| Posted on Friday, December 5, 2003 at 05:35:10 PM | c[_]`Wippuh |
|
| |
DimmaK Pissclams SharpShooter Laws Rambo Elusion Dr. Anomaly Baby Valdez Rahl
Out of that list, who shoud get interviewed next? Only you can decide by going and voting in the newest poll! Don't think you're interested, well then nominate canidates for the other polls coming up in the comments section. These include Best Team Tag, Best Wolf Slang, Overused Nicks and the Player who needs a BobbleHead!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (96)
.:Back to Top:. |
|
|
|
| Full Effect to United 5 and iN Leaves GMPO |
| Posted on Thursday, December 4, 2003 at 04:12:29 PM | c[_]`Wippuh |
|
| |
Another attempt at an uber multigaming clan has risen, and this time we see a major team from both RtCW and ET joining. United 5 has recently grown from a CS team of 5 guys, to teams from 5 different games. Those include Counter-Strike, Halo, Call of Duty, Return to Castle Wolfenstein and Enemy Territory.
Looking over the rosters of these teams some familar names pop up.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (43)
.:Back to Top:. |
|
|
|
| Darkside is Officially Back |
| Posted on Wednesday, December 3, 2003 at 04:03:23 AM | c[_]`Wippuh |
|
| |
ChaosLord has pm'd the info across that Darkside will be participating in RtCW next season. The lineup is Herbal, Illshot, ChaosLord, Rambo and Magik. CL mentioned that they may be looking for 1 to 2 more players to fill in the remaining spots, but it seems that they have already begun locking that problem down.
Good news for RtCW as the new season approaches. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (76)
.:Back to Top:. |
|
|
|
| RTCW: DeGeneration - Accepting new tester applications! |
| Posted on Monday, December 1, 2003 at 02:58:52 PM | Codey |
|
| |
We've been working in stealth mode ever since we began work on DeGeneration, but now we've come to a point, after testing with a hand-picked group for about 2 months, where we've decided to look for testers outside our circle for the current testing and for the beta testing that will be coming shortly. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (23)
.:Back to Top:. |
|
|
|
| No, you are not an admin =p |
| Posted on Saturday, November 29, 2003 at 05:13:35 AM | |
|
| |
Ok so I sent out a P2P and meant to only send it to admins but managed to send it to every user on the site. This is alright though as I can still take feedback from anyone who uses the site. As such, feel free to respond if you actually have suggestions for the site but no, you are not an admin (as the message suggests). =p |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (12)
.:Back to Top:. |
|
|
|
| Modern Day Gamer 2 Film Released! |
| Posted on Sunday, November 23, 2003 at 04:28:16 AM | icf|r0b`GG |
|
| |
Browsing through the enormouse amount of egaming websites, I found a very interesting article that includes a movie. The movie is basically about 4Kings Intel and their RTCW team. Below is a description of the movie:
The film features the Four Kings Wolfenstein squad as they compete at Quakecon 2003. We follow the team as they progress through the event & talk exclusively with them about tactics before their games.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (18)
.:Back to Top:. |
|
|
|
| Your Cal-M and Cal-I Champs |
| Posted on Friday, November 21, 2003 at 06:34:51 PM | c[_]`Wippuh |
|
| |
The two title matches went down on mp_ice in both cal-main and cal-drama.
With a 3-1 victory over !U Go Boom!, Action League Now is the champ of a very competitive and intense Cal-M season. The Raging Octopi, with perhaps the ugliest tags ever sported in a Cal finals match, escaped with a 3-2 win over !CF to win Cal-I.
GG's. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (23)
.:Back to Top:. |
|
|
|
| Team 3D Interviewed |
| Posted on Tuesday, November 18, 2003 at 05:22:03 PM | c[_]`Wippuh |
|
| |
If you play competitive games or even if you don't, you've surely heard of CounterStrike. CS represents the biggest game that is is on the forefront of taking video games to esports. No matter how individuals feel about it, that is hard to dispute.
Team 3D was recently interviewed by the CPL about the last Summer tournament and the game in general.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (11)
.:Back to Top:. |
|
|
|
| RtCW Shoutcasting Takes A Major Blow |
| Posted on Monday, November 17, 2003 at 03:52:06 PM | c[_]`Wippuh |
|
| |
Blankz, Wheat and trillian have all left TsN according to news reports off of various sites. The best known was DJ Wheat (former member of Positive Dickmen) who has been flown to places like Korea just to shoutcast q3 matches at the World Cyber Games. There's still no definate answer as to why the three left, but it is not good news for Wolf. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (8)
.:Back to Top:. |
|
|
|
| CAL-M Finals |
| Posted on Saturday, November 15, 2003 at 06:02:06 AM | ==*{SGT.DICK}*== |
|
| |
|aln| vs. !UgB!
Match will be played on Thursday, November 14. |aln| is coming off a 3-1 victory in an exciting match over Distress! Meanwhile, !UgB! has rolled through the playoffs so far with victories over Redline and Operation Psycho Patrol. The map has been switched from Base to Ice and the match will be on WTV and TSN as far as I know. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (22)
.:Back to Top:. |
|
|
|
| RTCW Nostalgia Tournament signups |
| Posted on Friday, November 14, 2003 at 04:06:25 AM | astro* |
|
| |
Signups start today, right now. #evolve.na message evolve-astro to signup your team or yourself! If you dont have a team, message me and if there's enough "loners" out there, you can create a team using that, or, I can direct you to some teams that need players to compete in the tournament and they may let you play with them. Anyway..
About the tournemnt. It's 7v7 format (hence the name nostalgia).Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (65)
.:Back to Top:. |
|
|
|
| NA's Only Hope? |
| Posted on Wednesday, November 12, 2003 at 03:45:05 AM | c[_]`Wippuh |
|
| |
Big news coming from the Full Effect camp as they gear up for cXg. With Affliction's retirement, fe looks to be NA's best chance to place at cXg. To even emphasize their aim at performing well at cXg, they have picked up former Affliction members Elusion and BeavermanA, while booting Wyld and Impulse.
The cXg lineup for Full Effect now consists of the following 7 man rotation...Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (58)
.:Back to Top:. |
|
|
|
| The EU scene Post Quakecon |
| Posted on Wednesday, November 12, 2003 at 02:15:02 AM | 4K ZaF |
|
| |
Well im gonna keep posting news as this is quite a popular website and i hope some of you are interested in the eu scene.
De.nvidia rtcw team has been given the boot, to be replaced by COW. COW are top 10 EU and qualified for the last 8 of ec8. Its a good move for them and they will be looking for sponsers to go to Vegas.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (13)
.:Back to Top:. |
|
|
|
| New Server and More ;p's |
| Posted on Monday, November 10, 2003 at 04:08:08 PM | c[_]`Wippuh |
|
| |
Looks like there's a new server in town, and it's being run by those fun spamming n00bs in OPP. Baby, Newt, Hydro and the rest of the squad are bringing you pub style fun in their own special way. I'll give you three guesses who wrote the following, heh.
hear ye hear ye NEW PUB ON TOWN!!!!! wo0t!!!!!!!! ;p new OPP pub server is running NOW!!!!
located at DALLAS!!!
69.56.147.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (17)
.:Back to Top:. |
|
|
|
| Lame IRC Exploit |
| Posted on Tuesday, November 4, 2003 at 02:41:11 PM | c[_]`Wippuh |
|
| |
Just read this off of challenge-tv.com, but it seems there's an exploit going around on irc where if you click a link to a certain jpg (a jessicaAlba.jpg is the example seen the most), you will do an amsg and not be able to see yourself spamming it. Occurs in both IE and Opera, while Mozilla is not affected. It also changes your homepage. Just another reason to NOT click links posted in irc. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (10)
.:Back to Top:. |
|
|
|
| Demos! |
| Posted on Tuesday, November 4, 2003 at 02:30:33 PM | c[_]`Wippuh |
|
| |
There seems to be some weird conspiracy at cached.net about Wolfenstein demos. You simply can't upload one and it not appear with a broken link in the dl section. Supposedly this has been fixed, but it was still broken upon testing last night.
This has led to a complete absence of demos lately, and we're being bombarded with q3ctf and wc3 demos. While those are all good, we don't want to watch them.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (11)
.:Back to Top:. |
|
|
|
| iN now GMPO? |
| Posted on Thursday, October 30, 2003 at 03:51:21 PM | c[_]`Wippuh |
|
| |
Saw this just posted on cached.net. No news on if they have to assume a bad attitude now.
Here is news that the top RtCW clan iNfensus has dropped their name and merged with GamePoint.AMD:
21:00 CET - 29/10/2003 - Volendam, Holland
iNfensus is happy to announce that we merged up with GamePoint.AMD.
To even advance in the Esports and see a brighter future for ourselfs then before.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (36)
.:Back to Top:. |
|
|
|
| CXG RTCW Qualifiers Now Open Invite |
| Posted on Wednesday, October 29, 2003 at 12:23:04 AM | Mich |
|
| |
Effective immediately the online qualifiers for the CXG RTCW Lan event are cancelled. All RTCW Teams all over the world will have the opportunity to play in this spectacular event in Las Vegas. The registration fee of $75 for the LAN Event is still in effect and is per person. The tournament is open to the first 64 clans that sign up and pay their fees. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (47)
.:Back to Top:. |
|
|
|
| STA-Wolf pre-season on tap... |
| Posted on Tuesday, October 28, 2003 at 03:17:47 PM | Skrappa |
|
| |
Enrollment is currently open. Pre-season starts Monday Nov 3rd.
-North American based RTCW league.
-Playing format is "old-school" 7 vs 7.
-Matches played every Monday night.
-Match default start time 9:30pm est.
-10 week season.
-Standard and custom maps in reg-season rotation.
-Pre-season maps: Assault, TheRiver, Rocket & infamy.
-MVP voting system.
-2 Panzer limit per side.
-Mandatory player pb_guids and server pb_ss.
-Special events such as 10 vs 10 intra clan matches.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| Planet-RtCW.com Tidbits |
| Posted on Friday, October 24, 2003 at 06:56:46 PM | c[_]`Wippuh |
|
| |
Just wanted to mention a few things. We're out of Pics of Whenever, so submit those photoshops and/or screenshots that you would like to see posted. Blatant personal attacks won't get posted.
As always you can submit articles and news through the admin menu on the left. Submit them and we'll approve them if they're not complete crap. Please don't post long posts for news, put them in the articles section.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| CAL Open playoff breakdown |
| Posted on Friday, October 24, 2003 at 04:09:58 PM | [+ oo] rampage |
|
| |
The season is winding down and here's the playoff schedule.
CAL's Playoff Map List:
Round #1 11/04 & 11/06 Assault
Round #2 11/11 & 11/13 Beach
Round #3 11/18 Base (Open) & 11/20 Ice (Main & Invite Finals)
Round #4 11/25 Ice (Open Finals)
Open will be advancing 16 teams, the top 8 from each conference. Main will advance 8 teams, the top 4 from each conference.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| Cal Playoff Format and Schedule Announced |
| Posted on Thursday, October 23, 2003 at 02:52:56 PM | laws_69 |
|
| |
According to CAL|BERT
With only 6 or 7 active teams left in CAL Invite, we are presented with a interesting playoff situation as the rules state we will take the top 8 teams. Since there aren't 8 active teams we've decided to take the top 6 teams into the playoffs based on the guidelines found in the CAL Invite rules 3.110 Playoffs:
Seedings and Tiebreakers are determined as follows:
1. Points
2. Wins
3.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (16)
.:Back to Top:. |
|
|
|
| There's No Border Patrol on the Way to Vegas! |
| Posted on Wednesday, October 22, 2003 at 07:29:55 PM | c[_]`Wippuh |
|
| |
Interesting Conversation of IRC last night, it went something like this.
c[_]`Wippuh: Hi, is it true you guys are coming back?
Da_G]NARF[: Yeah
Da_G]NARF[: Gonna play for cXg, different roster same name
c[_]`Wippuh: Any plans to play in cal next season?
Da_G]NARF[: Maybe, not sure yet
Will NARF play in Cal? How will cXg go for them? Will BeavermanA play for Affliction or NARF? Will Obliv play for Trinity or NARF?Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (53)
.:Back to Top:. |
|
|
|
| Stronger Than All ET First season... |
| Posted on Monday, October 20, 2003 at 03:22:38 AM | Skrappa |
|
| |
STA-ET kicks off its first regular season of RTCW:Enemy Territory this Thursday October 23rd. Here are some of the particulars at a glance:
-North American based league.
-Playing format is 8 verse 8.
-Matches played every Thurs night.
-Match default start time 9:30pm est.
-8 week season.
-Point based scoring system (win 3, loss 1, ties 2.)
-All half rounds are 20 minutes in length for every map.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (12)
.:Back to Top:. |
|
|
|
| MasterMind |
| Posted on Sunday, October 19, 2003 at 09:41:19 PM | c[_]`Wippuh |
|
| |
Bearing bad news is never fun, but this needs to be said as Mastermind knew a lot of people from the early days of wolf. On the 8th of this month Mastermind was found dead from an alcohol overdose. Mastermind played Wolf for The Dead Pool (TdP) and participated in some of the early Cal league seasons.
Sad news about a great guy. Mastermind was in his mid 30's. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (23)
.:Back to Top:. |
|
|
|
| Q and A with CyberX CEO Joe Hill |
| Posted on Friday, October 17, 2003 at 01:48:16 AM | Mich |
|
| |
I know this is short notice but there will a Question and Answer session with Joe Hill the CEO of CyberX in #cyberx on gamesnet. So if you have any questions for the owner with the recent changes feel free to come on by and ask him something. It will last from 9:00 PM to 10:30 PM CST. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| CyberX Moves to Las Vegas and More! |
| Posted on Thursday, October 16, 2003 at 08:59:41 PM | Mich |
|
| |
Here's the update that you all have been waiting for and you will see why i have waited so long to update everyone. Now i know this may throw a kink into some of your travel plans but in the end its a better location to help expose RTCW and esports in general to the industry. This will help teams foster sponorships by showcasing themselves to the thousands of vendors at the event. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (57)
.:Back to Top:. |
|
|
|
| RtCW Trivia |
| Posted on Thursday, October 16, 2003 at 12:36:30 AM | c[_]`Wippuh |
|
| |
I tried my hand at writing trivia for and Donka was kind enough to give it a run through in #planetrtcw tonight. Fragile thoroughly dominated everyone and came away winner. We'd like to get more questions to add to it if we could, so we're asking everyone to submit their very own question(s). There's a format to which you have to follow.
Question|Answer
IE: What's the irc channel for planet-rtcw.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (12)
.:Back to Top:. |
|
|
|
| STA-WOLF Finals and ProBowl... |
| Posted on Monday, October 13, 2003 at 12:15:19 AM | Skrappa |
|
| |
"Old school 7's" take front and center with STAWOLF's Playoff Final's match this Monday Oct. 13th at 10pm est. Preceding the playoff finals match will be STA-WOLF's ProBowl game at 8:30 pm est. Both matches to be played on mp_Base and are scheduled to be broadcast on both wolftv and Xcast (The official qcon shoutcast network).
The main event features RAG (Rubber and Glue...Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (14)
.:Back to Top:. |
|
|
|
| ESO 2 Finals + BoB2 is over |
| Posted on Sunday, October 12, 2003 at 04:55:31 PM | selfie |
|
| |
Battle Of Britain ended yesterday with a 2-0 win from Four Kings over Digital Heresy.
In other news, ESO2, the European tournament with 8 invited teams, is coming to and end today. The biggest revelation was undoubtly Kreaturen |K|, who weren't originally invited but made it to the finals by beating big names such as Infensus and Team Unknown.
Loser Brackets Round 3
Date: 18:00 CET, 12 October 2003
Map: Mp_Assault
4kings.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (10)
.:Back to Top:. |
|
|
|
| Osp Suggestions |
| Posted on Friday, October 3, 2003 at 03:29:33 PM | Impulse #complexity |
|
| |
Rhea Emailed me back and this is what he had to say
Heya,
Yea, I'll definitely consider this stuff. I've just finished an overhaul on
the multiview and demo stuff, and plan to start working on normal gameplay
stuff next.
If you have any other requests, and/or bugs that you and the crew have
found, I'm definitely all ears right now :)
Thanks,
-rhea
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (64)
.:Back to Top:. |
|
|
|
| Week 4 CAL Invite Results & Week 5 Schedule Mp_Beach |
| Posted on Friday, October 3, 2003 at 03:29:19 PM | pissclams |
|
| |
Week 4 CAL Invite Results -- Mp_Submarine
LQD > dT 3-0 -forfeit
!CF > Chrome 3-1
tTt > i 3-0
Stylez > K` 3-0
affliction > dh. 3-0 -forfeit
Raging Octopi > GAT 3-1
Redrum > P*rnStars 3-0
Week 5 CAL Invite Schedule -- Mp_Beach
GAT vs. Team Chrome
ICF vs. Stylez
Kinetic vs. LQD
P*rnStars vs. Raging Octopi
Redrum vs. Trinity
Affliction vs. immortals
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (6)
.:Back to Top:. |
|
|
|
| Prediction payouts |
| Posted on Thursday, October 2, 2003 at 10:14:29 PM | |
|
| |
I recoded the system so hopefully now the prediction payouts will work. For those that didn't know (or understand how it works) about the prediction payout here is a brief overview.
A user makes predictions on a group of matches. After the admins enter in the official scores for those matches, the system will look at how many predictions you got right.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| Cal-Invite Takes a Major Blow |
| Posted on Tuesday, September 30, 2003 at 09:15:30 PM | c[_]`Wippuh |
|
| |
Cal-Invite, and the North American RtCW scene, has taken a major blow with two high profile teams leaving the game mid season. Both DeathTouch and Digital Heresy have dropped.
As of right now, no definite answer has been discovered for .dh's drop, but their roster is completely empty and some members have been seen scrimming with other teams. It was just a few days ago that they picked up Slag to solidify their roster.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (28)
.:Back to Top:. |
|
|
|
| Doctors Returning? |
| Posted on Sunday, September 28, 2003 at 05:43:08 AM | Kuniva |
|
| |
It has come to my attention that the famed 2002 Quakecon Champion Team "Doctors" is alive and kicking.
Upon random conversation in #Narf last night someone said "they're back you know" and put the channel #Doctors up. I joined expecting to find a cs team or something, but immedeately the topic caught my attention:
* Now talking in #doctors
* Topic is 'the doctors. | soon to play WoW | Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (34)
.:Back to Top:. |
|
|
|
| Weekly Planet-RTCW Prediction Write-Up |
| Posted on Thursday, September 25, 2003 at 06:27:24 PM | Pravda |
|
| |
If you haven't already noticed, The_Wippuh has begun writing his predictions on the CAL matches on a weekly basis and can be found in the Articles section (you can also check the lower right column for article updates). The opportunity to have your predictions shown on this site and scrutinized by its readers is extended to anybody who reads the site. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (9)
.:Back to Top:. |
|
|
|
| RTCW Leagues vs. Stable Community. |
| Posted on Wednesday, September 24, 2003 at 02:58:20 PM | -doNka- |
|
| |
It's just came to the point when I come to IRC everyday and see new clan trying to recruit people of different skill levels: invite, main, and just "good". One of the reasons for this is an existing ability to put together a team of 6 people and enter ANY level of the competition at almost any time of a season. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (11)
.:Back to Top:. |
|
|
|
| CyberX RTCW Update |
| Posted on Sunday, September 21, 2003 at 05:08:06 AM | Mich |
|
| |
I know its been a long time since there have been any updates on CyberX so here it is. We have gone through some format changes and date changes that we feel will better suit the community. The TeamWarfare RTCW Staff will still be assisting in the running of the online qualifiers and LAN tourney in Orlando. You can read an interview with the CEO of CyberX Joe Hill here. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (29)
.:Back to Top:. |
|
|
|
| 2v2 North Atlantic Tournament |
| Posted on Saturday, September 20, 2003 at 08:08:49 PM | -a-WarRi0R |
|
| |
2v2 North American ****UPDATED 9/21/03*****
General:
This cup will be for two (2) players versus two (2) players double elimination tournament.
A point is awarded by killing both players of the opposing team, in one round (With the exception of mp_badplace). Once you kill them you repeat until you get ten (10) points. Then change sides to give an equal advantage (luger and colt) to both teams.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (40)
.:Back to Top:. |
|
|
|
| More Info on the Phantom |
| Posted on Thursday, September 18, 2003 at 07:46:06 PM | c[_]`Wippuh |
|
| |
Slashdot has linked to an interesting article. If you're unaware, there's been a good bit of press given to a new gaming device called the Phantom. Not a lot has been said about it, and many have assumed it was vaporware. However, it appears that it may become reality.
From the info gathered in the article, a possible scenario would go something like this.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| Resetting Stock Salary and More... |
| Posted on Tuesday, September 16, 2003 at 11:15:35 PM | Pravda |
|
| |
Due to popular demand, I am resetting the stock system so that each player will begin with 10,000 dollars rather than 1,000 dollars. This was decided due to the fact that a person with only 1,000 can buy a very minimal amount of shares. So, if you were shopping around with your measly grand, you can go back to your account right now and re-buy more shares. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (8)
.:Back to Top:. |
|
|
|
| Begin Predictions Season 6 |
| Posted on Saturday, September 13, 2003 at 05:22:33 AM | Pravda |
|
| |
In case you haven't already noticed, the predictions system for CAL Open and CAL Invite are both up and updated. As previously mentioned, this also means that the stock system will start up again. They are officially being reset. So your stock portfolio has also reset and once again the contest for the top stock earners begins again. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (9)
.:Back to Top:. |
|
|
|
| Stock System is Running |
| Posted on Friday, September 12, 2003 at 08:51:10 PM | c[_]`Wippuh |
|
| |
Just received the following p2p
Since yer the smartest person I know, maybe you wanna annouce that the team list is completely updated and all results for week 1 have been entered. Which in turn means that all stock prices reflect those results. I had to manually enter a bunch of teams so if they want to take ownership of the their own team they'll have to send me a p2p.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (6)
.:Back to Top:. |
|
|
|
| Cal-O Week 1 Results |
| Posted on Wednesday, September 10, 2003 at 03:40:12 PM | c[_]`Wippuh |
|
| |
Last night the first week of matches were played in Cal's Open division. For the most part things went as you would expect, with a lot of 3-0 wins, but there were some extremely close matches.
The MOTW went to tE as they edged out Cult of Hands for a 3-2 win. It appears that Handof went up 2-0 and then tE came screaming back for the overtime win.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (15)
.:Back to Top:. |
|
|
|
| CAL-Invite |
| Posted on Friday, September 5, 2003 at 10:26:33 PM | -a-nail |
|
| |
Last night was the preseason round of CAL-Invite. With only 1 match (Rewind vs Kinetic) going 3-0 shutout it looks as if this season of CAL-I will have good competition with the other games going 3-1 and 3-2 wins.
Although WolfTV was not able to cover any of the matches last night I've heard it will be up and running next week to cover the first week.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (41)
.:Back to Top:. |
|
|
|
| Cal-Open Kicks Off |
| Posted on Thursday, September 4, 2003 at 07:23:29 PM | c[_]`Wippuh |
|
| |
Cal-Open will officially kick off the 9th as teams face off on Assault. Week one has a lot of good matchups including the match of the week imo, Team Eclipse vs Cult of Hands.
The early favorites this season look to be Distorted Reality, Team Eclipse, Handof, Republic, Ufok, 502nd, TH, and BYE. It should prove interesting to see what mystery team(s) rise up and challenge them as the season rolls along.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (16)
.:Back to Top:. |
|
|
|
| Season #4 Config (Yes i swear!) |
| Posted on Wednesday, September 3, 2003 at 04:54:44 AM | Mich |
|
| |
With some great community input from people such as Jinks from Uprise and Reyals from PlanetWolfenstein i have made the final changes to the config and one that i hope the community is pleased with. Here are the final pb restrictions for season #4:
pb_sv_enable
pb_sv_cvarempty
pb_sv_kicklen 1
pb_sv_cvar rate in 2500 25000
pb_sv_cvar snaps in 20 40
pb_sv_cvar com_maxfps out 0.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (49)
.:Back to Top:. |
|
|
|
| CyberX Article |
| Posted on Monday, September 1, 2003 at 07:44:41 PM | c[_]`Wippuh |
|
| |
After the release of the new cfg settings, there were discussions had in #affliction about the relation of the aforementioned cfgs and CyberX. Many were upset at the lack of teams signed up and the threat that posed to actual RtCW tournament occuring. I put forth my thoughts on the subject, and while some disagreed, a few agreed. So here's the article I wrote up after the prodding from several people. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| TWL Goes Nazi Cfg |
| Posted on Monday, September 1, 2003 at 05:42:28 AM | c[_]`Wippuh |
|
| |
Effective immediately a new match config will be in effect. In an effort to standardize configs across the board with CyberX, Clanbase, CAL, and TWL we are implementing a new match.cfg with new pb cvar restrictions. You can download the new match config here.
The above is the statement released on TWL's homepage as they have enforced the strictest pb settings ever seen in NA league play.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (98)
.:Back to Top:. |
|
|
|
| ATI CyberX RTCW Update |
| Posted on Friday, August 29, 2003 at 04:48:53 AM | Mich |
|
| |
For those of you that have been waiting for an update on the CyberX RTCW Qualifiers well here it is.
-The North American Qualifiers will start on October 6th while the European Qualifiers will start on November 4th. The deadline for registering on the NA Quals is September 26th and October 17th for the Euro Qualifiers.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (22)
.:Back to Top:. |
|
|
|
| Affliction Reappears! |
| Posted on Thursday, August 28, 2003 at 03:09:56 PM | c[_]`Wippuh |
|
| |
Upon early release of the Cal-I team list, almost everyone pointed to Rewind as the obvious favorites to win it all this season. Things might change from here on out as Team Affliction has made their presence known in Cal-I.
In addition to ending their league vacation, Affliction has stepped up and grabbed two high profile players in BeavermanA and Elusion of NARF and wSw fame respectively.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (27)
.:Back to Top:. |
|
|
|
| Cal-M Teams are Announced |
| Posted on Wednesday, August 27, 2003 at 02:56:42 PM | c[_]`Wippuh |
|
| |
The caleague site has been updated with the info on who will form cal-m. The preseason for Main will start next Thursday (Sept 4th) and will be on mp_pacific! Nice to see the leagues really starting to adapt a progressive stance towards custom maps. Even better to see that there's something FINALLY being put out that's worthy of the league's attention. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (16)
.:Back to Top:. |
|
|
|
| ET Pickup Games |
| Posted on Tuesday, August 26, 2003 at 03:44:39 AM | CireJ/SI/ |
|
| |
For those of you Enemy Territory players who are having trouble finding a competitive public server to play on, you aren't alone. We were (or still are) all noobs at some point, but you have probably noticed a large amount of players of lesser skill on the majority of ET public servers. With that being said, #etpickups on gamesnet has recently been created. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (12)
.:Back to Top:. |
|
|
|
| fX.ET divsion merges with top notch CS team Death is Eternal |
| Posted on Saturday, August 23, 2003 at 06:39:10 AM | rand0m |
|
| |
This late time at night we have merged the ichorvile q3 team and the ichorvile et team(fX.et division) and have merged them with team Death is Eternal. The cs team that has won lan's and placed 17th at CPL. The channel is #teamdie on irc.gamesnet.net. The merge came late late this friday night...things are still getting smoothed out, but now you will find us under the name DIE. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (58)
.:Back to Top:. |
|
|
|
| New Wolf Movie Produced By BinaryBiscuit |
| Posted on Thursday, August 21, 2003 at 07:13:00 PM | v1k!ngISCG |
|
| |
From the member of shaolinproductions himself, comes another great wolf movie entitled "disturbed" which showcases Savage and his 1337ness through multi kill clips, some nice use of effects, and cool camera tricks. From the beginning of the film it's apparent that this film will be great. Just the opening sequence alone makes you want to go out and play some wolf; it's beautiful. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (26)
.:Back to Top:. |
|
|
|
| Cal-I Season 6 Comes Into Focus |
| Posted on Thursday, August 21, 2003 at 04:28:57 PM | c[_]`Wippuh |
|
| |
With the preseason for Cal starting up next week on a modified Chateau, the team list for Cal-I seems to be getting a little less foggy. With the influx of a few new teams the overall state of Wolfenstein appears to be very strong despite the absence of several high profile names. However, is there enough consistant talent out there to form both a main and invite level of Cal? Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (33)
.:Back to Top:. |
|
|
|
| New Company on the Game Computer Scene |
| Posted on Tuesday, August 19, 2003 at 10:23:28 PM | c[_]`Wippuh |
|
| |
In yet another move that shows the growing popularity of gaming, Gateway has entered the gamer computer market. Boasting a p4 2.8, 512 of Ram, fx5900, 180GB drive, DVD burner, and a 19" monitor, Gateway seems to have a good combination of hardware, but a staggering price of $2,100! If you're strapped for cash, you can buy a lesser system for $1,150 :P
Will this ever work? Who buys these things?Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (8)
.:Back to Top:. |
|
|
|
| Impressions of Qcon |
| Posted on Monday, August 18, 2003 at 05:33:14 PM | c[_]`Wippuh |
|
| |
With qcon over, there's a lot to look forward to and look back upon. The event was a big success and extremely entertaining to attend. If there's ever a chance that you can make it, do it. So here goes a lil' article with my experience and impressions at qcon. Hopefully this will shed some light on how the event was run, the stuff liked/disliked, and all that jazz. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (8)
.:Back to Top:. |
|
|
|
| Europe Brings the Pain Train |
| Posted on Sunday, August 17, 2003 at 04:24:22 AM | c[_]`Wippuh |
|
| |
The night has finally ended and the big winners of the entire thing is Infensus. Facing off vs GMPO, Infensus left no doubt who the best in the world is with an extremely dominating performance on assault. A noticeable difference in their lineup is Spear, their panzer. He put on a show that will be remembered for a long time as he blasted GMPO all over the map. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (206)
.:Back to Top:. |
|
|
|
| Wowzers! |
| Posted on Saturday, August 16, 2003 at 12:49:58 AM | c[_]`Wippuh |
|
| |
Two big matches have occured with NARF loosing to wSw in a very close match and frontline falling to Affliction! Both matches had tie rounds, and they're counting tie rounds as points for each team at Qcon.
So far the teams knocked out include the Amish, dh.NA, !cF, Last Chance, and HV. The teams gaining the upper hand, with 2-0 records, include iN, wSw, -a-, and TAF.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (7)
.:Back to Top:. |
|
|
|
| Day 2 |
| Posted on Friday, August 15, 2003 at 04:41:25 PM | c[_]`Wippuh |
|
| |
With !cF disputing the results of their match they've been awarded a forfiet win over .dh's European squad and right now the it's .dh vs .dh on beach in a loser's bracket match. 4k and Lastchance are also rolling along.
The North American teams came out extremely strong with both wSw and f| defeating 4k and GMPO. ocr regained some momentum with their win over cK.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (18)
.:Back to Top:. |
|
|
|
| The Clam that Cried Wolf |
| Posted on Thursday, August 14, 2003 at 07:42:50 PM | c[_]`Wippuh |
|
| |
In a shocking Quakecon development, there's no Pissclam's sighting! Many have turned away from Qcon upon seeing the infamous "beatdown" line thinking that it was the line for BYOC. Instead of receiving a vicious beating from Piss, everyone was turned away.
One thing that will not be ruined because of Qcon, is NARF's reputation for partying.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (1)
.:Back to Top:. |
|
|
|
| CAL Season 6 to be 3-tiered |
| Posted on Thursday, August 14, 2003 at 02:02:18 AM | CireJ/SI/ |
|
| |
Here's the scoop from CAL|Gill:
Thanks to some great input CAL will be doing 3 tier for season 6. Please prepare your teams as sign ups will be made available shortly. Also, if by the end of the preseason, it's not looking good we will go back to 2 tier. So please do your best to have your teams ready to go. Thanks again for all the feedback.
CAL|GILL
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (9)
.:Back to Top:. |
|
|
|
| Quakecon day 1 |
| Posted on Thursday, August 14, 2003 at 01:01:44 AM | CireJ/SI/ |
|
| |
If you're reading this, chances are you aren't currently at Quakecon. That's alright though, because the next best thing to being at QCon, is watching the action on GTV from the comfort of your very own home. Thursday marks the first day of the RtCW tournament, and here are the scheduled match times. I'm assuming the times given on the QCon site are central standard, so that is how they will appear here. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (9)
.:Back to Top:. |
|
|
|
| ICF AT QCON WEEEEEEEEEE |
| Posted on Thursday, August 7, 2003 at 06:27:54 AM | icf|reactor |
|
| |
Newsbot on Quakcon forums
Hello all!
Well, another team has been replaced! Trinity (a substitute) has dropped and ICF! will be taking their place! Congrats to ICF and thanks to them for accepting on short notice.
Good luck in the tournament!
Im not going but im sure to be watching from home and cheering on my boys in icf, with our few add-ons ;)
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (65)
.:Back to Top:. |
|
|
|
| TWL Annouces Preseason Maps! |
| Posted on Wednesday, August 6, 2003 at 06:41:26 PM | c[_]`Wippuh |
|
| |
I don't know about the rest of you, but this offseason is the longest I can ever remember. I started itching for some match action about 2 weeks ago, so this news is very welcomed. Looks like TWL and CAL will continue their work in unison, and that kicks ass for all competitive players of RtCW. Also encouraging is the inclusion of NEW MAPS in the preseason. Here's what we've got so far. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| GLOW wins Cal Open |
| Posted on Wednesday, August 6, 2003 at 04:29:49 AM | CireJ/SI/ |
|
| |
Tonight GLOW used all the power of their Double D's to defeat The Commission in the CAL Open championship 3-1 on mp_base. It was an exciting match to watch, and a very competitive game to boot. I didn't have time to do a write up, but there should be demos up for download soon and a recording of ze axis shoutcaster Herr Warwitch from TsN.
Congrats GLOW! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (8)
.:Back to Top:. |
|
|
|
| ET_TourneyMod |
| Posted on Tuesday, August 5, 2003 at 02:53:08 PM | c[_]`Wippuh |
|
| |
With Bani releasing his initial version of ET Pro, Shrub has come back with their release of ET_TourneyMod. Things look good for this mod as it's backed by those slackers over at LoT (Planet-RtCW > Odin). Lots of changes have been made, including things like a new hud, a fix spawn scripting system, ammo/health pack throw length, and a moverscale to help change the speed of the tank on maps like goldrush and fueldump! Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (9)
.:Back to Top:. |
|
|
|
| Cal-O Championship Match - Glow vs Comm |
| Posted on Tuesday, August 5, 2003 at 06:11:39 AM | c[_]`Wippuh |
|
| |
It's all come down to this. Glow vs Comm for the #1 spot in Cal-o. Both teams look strong and ready to leap up into main next season. Kicking ass through the entire regular season, someone's perfect record gets marred tonight as they face off on Base.
The match starts somewhere around 10:30est, and will be cammed by the mad clam himself, Pissclams!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| ET Pro 1.0.0 |
| Posted on Monday, August 4, 2003 at 03:26:20 PM | c[_]`Wippuh |
|
| |
If you didn't know, now you do. Tonight is the first night of the TWL ET preseason. The forecast on Radar includes 6v6 with fps dipping into the teens. In keeping with their fine tradition, Splash Damage has created a game with little to no competitive play value without major tweakage.
That's where the mods step in. Bani has created the first ET mod with ET Pro.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (9)
.:Back to Top:. |
|
|
|
| Qcon: Reseeding Announced |
| Posted on Saturday, August 2, 2003 at 08:14:53 PM | c[_]`Wippuh |
|
| |
Just saw this on the quakecon site.
"Okay, as all of you know, two teams have dropped: fx and Amnesia. That means that the #1 and #16 seed have dropped from competition.
The major decision here was to insert 2 teams at the #15 and #16 position and thus have to reorganize everyone else or to just "replace" them.in the bracket and leave the prior matchups the same.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (17)
.:Back to Top:. |
|
|
|
| New Pub |
| Posted on Saturday, August 2, 2003 at 08:37:44 AM | MadnesS |
|
| |
With locked box closing soon and o++ already gone there are hardly any quality servers left in the community. Team Redemption has recently purchased an 18 person pub. Its located on the east coast but central players ping well and west coasters have around a 100-110 ping. Server could possibly have o++ like stats as well. Also noobishness will not be tolerated. Server will be regulated by redemption members. Server ip is 65.39.205.86:27960. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (12)
.:Back to Top:. |
|
|
|
| Zay about fx and Amnesia |
| Posted on Friday, August 1, 2003 at 11:52:32 PM | c[_]`Wippuh |
|
| |
I emailed Zay to ask about fx and Amnesia and if it was true they were dropping. This is the email she returned to me.
Hello.
There is some truth to that. The teams will be announced on the website along with what will be going on with the seeds after things are made 100% sure. Until things are 100% I don't really want to give out incorrect information.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Amnesia not attending Quakecon |
| Posted on Thursday, July 31, 2003 at 09:57:52 PM | Kr#kc |
|
| |
Unfortunately Amnesia had to cancel their attendance at Quakecon. After we got the spot a team was formed and everyone had the money to go. At least till one parent decided it was too expensive so we were down one player. We tried to find another sixth, but the only people interested were people we didn't know too well or people that didn't have the money for sure. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (3)
.:Back to Top:. |
|
|
|
| Cal-Open Finals Set |
| Posted on Wednesday, July 30, 2003 at 07:21:23 PM | c[_]`Wippuh |
|
| |
Last night The Commission and GLOW took out eS and TV on ice to secure their spots in the Cal-O championship. The finals will take place next Tuesday on mp_base.
Both teams rolled through the regular season with undefeated records, and while GLOW was predicted to arrive at this spot since the very beginning, Comm represents a small surprise.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Planet-RTCW.com X-cast.net Show |
| Posted on Sunday, July 27, 2003 at 02:26:09 AM | cK AnimeMan |
|
| |
Well, we had a really small show friday night with about 50 listeners and announced that our next show would have the QuakeCon Seedings announced before anyone else. Well, you wont have to wait till next friday, due to time restraints, the seedings will be announced tomorrow night at 11 EST on another Planet-RTCW.com X-Cast.net show.
If you missed our last show find it here.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (11)
.:Back to Top:. |
|
|
|
| New QCon RTCW e-mail! |
| Posted on Saturday, July 26, 2003 at 07:05:42 PM | cK AnimeMan |
|
| |
Zay has sent out this mail to all the teams, so check it.
Hello all!
Okay, we're a little over 2 weeks out and I assume that everyone now has their travel arrangements and hotel arrangement set.
What I need from each and every qualifying team is the following:
1) The full NAME / HANDLE / ADDRESS / PHONE # and EMAIL address of each person coming. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (7)
.:Back to Top:. |
|
|
|
| Quake 4 concept art |
| Posted on Saturday, July 26, 2003 at 04:38:52 AM | v1k!ngISCG |
|
| |
Because of the massive interest in not only Doom 3 but also the games that will be created using it's 3D engine, many websites having been doing as much as possible to get early looks at these games. Quake 4 has got to be high on everyone list for "most wanted" and these early character models look impressive. These and other artwork pics floating around the net paint a happy picture for gamers' futures. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (4)
.:Back to Top:. |
|
|
|
| Qcon Seeding Predictions |
| Posted on Friday, July 25, 2003 at 03:21:55 PM | c[_]`Wippuh |
|
| |
With the cal matches taking place last night, I thought an article about their effect on the seedings at qcon would be interesting to read. Feel free to read on and tear my ideas apart. I've got a feeling this year's qcon is gonna be rock solid in terms of competition, and the seedings are going to make a world of difference. Especially with village in and sub out. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| CAL-Main and Invite Finals TONIGHT |
| Posted on Thursday, July 24, 2003 at 09:56:46 PM | -x-fragile |
|
| |
Thats right folks just a friendly reminder that the Season 5 Main/Invite finals are on tonight. First up with Team eXodus vs Digital Heresy on mp_ice kicking off at 10est. Shoutcasted by the dangerous trio of THE Warwitch, Sabo, and Deeay expect a classic match to unfold tonight. Team Exodus has also invited Warwitch into their ventilo for some ingame chatter, so be sure to tune in. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| TWL Opens ET Leagues |
| Posted on Thursday, July 24, 2003 at 07:26:47 PM | c[_]`Wippuh |
|
| |
Just saw this posted by Warpath on Planetwolfenstein.com
TWL Enemy Territory League Sign Ups
We are pleased to announce the first major league in North America for Return to Castle Wolfenstein: Enemy Territory. The Team Warfare League feels the community is not only ready, but very eager to have the structured weekly competitive play that a league affords.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (4)
.:Back to Top:. |
|
|
|
| Cyberathlete Amateur League RTCW Finals Night! |
| Posted on Tuesday, July 22, 2003 at 04:00:48 AM | Kuniva |
|
| |
Big night comin up this thursday in CAL. Both the Main and Invite seasons are drawing to a close with the championship matches this thursday. To generate a little more interest in the finals than has been shown over the playoffs so far, CAL has organized a big show for wolfers, including TsN and wtv for both finals matches. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (7)
.:Back to Top:. |
|
|
|
| CAL playoffs |
| Posted on Sunday, July 20, 2003 at 01:59:36 AM | Carnal |
|
| |
The Championships are upon us! On Thursday night, two-time CAL champ ]NARF[ will try to avenge their regular season loss to Team Effect. Coming off an undefeated season, fX will be eager to dethrone the former champions and secure their place as North America's frontrunner leading into Quakecon.
In the Main division, Digital Heresy puts their flawless record on the line against Exodus to conclude another season of Cal-Main.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (21)
.:Back to Top:. |
|
|
|
| CyberX Regional Events |
| Posted on Thursday, July 10, 2003 at 09:23:48 PM | Mich |
|
| |
All of the Regional Events for CyberX have been announced. Here is the rundown:
Chicago Regional July 19-20
Dallas Regional August 22-24
New York Regional October 3-4
Los Angeles Regional November 28-30
The same $76 fee applies for all of these events. Now the real question to ask yourself and your team is which of these events would your team most likely attend?Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (23)
.:Back to Top:. |
|
|
|
| PsyberStats 3.1.2 released |
| Posted on Wednesday, July 9, 2003 at 06:11:43 AM | |
|
| |
I have released a new ver of PsyberStats, 3.1.2. This version has a few bug fixes, includes all updated game profiles and all updated (and a few new!) themes. It also adds a few new features, most of which you won't even notice.
This new release adds the ability for the program to output 1 file PER PLAYER or 1 file PER MAP!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (1)
.:Back to Top:. |
|
|
|
| Minions of Rage merge with Euro Digital Heresy... |
| Posted on Tuesday, July 8, 2003 at 07:23:18 PM | iM-Hicks |
|
| |
Euro multi gaming clan Digital Heresy today confirmed Minions of rage as their north american RTCW team.
spokesman from the global dh HQ's had this to say....
"I would like to thank dh|jifster and Digital Heresy in general for this idea and proposal. The invitation came several weeks ago and after careful planning we came to a conclusion that this is the best move for Minions at the moment.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (48)
.:Back to Top:. |
|
|
|
| Just a reminder for QuakeCon Teams |
| Posted on Tuesday, July 8, 2003 at 06:43:02 AM | cK AnimeMan |
|
| |
I got this in an e-mail saturday, and didn't check until tonight by chance. Would have been bad had I not checked my mail another day ;o.
Hello all! (Make sure you read through all of this and write me one back!)
Congratulations on making it to the final 16! We had some bumps, but I
feel that the 16 that are here definitely deserved it! Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (6)
.:Back to Top:. |
|
|
|
| CAL Invite and Main Results |
| Posted on Friday, July 4, 2003 at 08:51:41 AM | Pravda |
|
| |
This week marked the end of the regular season for CAL and probably one of the most quiet ones ever. The forfeit bug was extremely contagious as the majority of matches both in CAL Main as well as Invite appeared to have resulted in forfeits. With July 4th revelry looming in the air and some teams disbanding or struggling to keep their roster, and still others concentrating on Quakecon, it was quite a quiet night. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (20)
.:Back to Top:. |
|
|
|
| Two Hundred Twenty Seven Years Old |
| Posted on Friday, July 4, 2003 at 08:31:31 AM | Pravda |
|
| |
Yep, it's July 4th, Happy Birthday United States of America. In the meantime, our weekly Friday 11:59PM EST show for Planet-RTCW on X-Cast will be rescheduled for this week in light of the fact that it's July 4th, Independence Day for the majority of our listeners. The new time this week will be on Sunday 11:00PM EST so mark it down on your calendars and hopefully, if you missed Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Playertracker Thursdays Meets Warri0r |
| Posted on Thursday, July 3, 2003 at 06:39:29 PM | Pravda |
|
| |
With the big upcoming match between NARF and Team Fx in CAL Invite, it is only fitting that for this week, we take a look at a Team Fx player who has been legendary with his aim and praised for his skills, Warri0r. Having been on several high caliber teams including Darkside and former CAL Open champs, 82nd, Warri0r is no stranger to victory. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Turning Back to CAL |
| Posted on Wednesday, July 2, 2003 at 07:18:32 PM | Pravda |
|
| |
After a tumultuous and interesting week of Quakecon qualifiers, we turn our eyes back to CAL where the last matches of the regular season end this week and will begin the playoffs, the quest for a CAL championship.
This week's Invite probably has some of the closer matchups of the season and will make for a very exciting set of games.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (36)
.:Back to Top:. |
|
|
|
| CyberXGaming Regional Qualifiers |
| Posted on Wednesday, July 2, 2003 at 04:59:11 AM | Mich |
|
| |
Event Registration & Team Sponsorship Cyber X Gaming has now opened registration for all Regional Qualifying events as well as the BYOC competition to be held at the World Games. With a limited number of teams and BYOC slots available within each of our events we anticipate that all areas will be rapidly filled to capacity.
The Orlando Championship event in January will feature a maximum of 1,200 available BYOC positions.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (10)
.:Back to Top:. |
|
|
|
| Spawntimer Drama Clarification |
| Posted on Tuesday, July 1, 2003 at 08:01:19 PM | Pravda |
|
| |
Krekc from Amnesia has submitted his own story of what happened during the whole spawntimer affair where a member of Amnesia accused members of the Amish World Order of illegally using an external spawntimer program in their Quakecon qualifier match. The Amish World Order has since gone on to officially win that match and will be invited to Quakecon. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Mock Quakecon Seedings |
| Posted on Tuesday, July 1, 2003 at 07:58:17 PM | Pravda |
|
| |
Zaf from Gamepoint has submitted a mock Quakecon seeding (similar to what Abuse did last year) based on several different conditions including average overall time, average overall time including Olympic interleaving and loss of best and worst rounds, etc. Here, for example is his average overall time seedings:
The Seeding for Overall Average time is as follows.
1: Team Effect (2.23)
2: ocrana (3.20)
3: TaF (2.41)
4: De.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (10)
.:Back to Top:. |
|
|
|
| Amish World Order Officially Accepted |
| Posted on Monday, June 30, 2003 at 11:51:42 PM | Pravda |
|
| |
With the recent drama surrounding the Amish World Order's use of an external spawn timer in the AWO vs Amnesia match, a decision has been officially reached by Zay. The dispute stems from a claim by an Amnesia member that AWO used external timers that should be considered illegal during Quakecon qualifier matches. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (11)
.:Back to Top:. |
|
|
|
| Tapper Speaks Out |
| Posted on Monday, June 30, 2003 at 08:01:57 AM | Pravda |
|
| |
Tapper, one of the foremost Quakecon administrators has spoken out on the supposed conspiracy against Europeans in a cached thread article. *CLARIFICATION*: This is not an official statement, but a post in a thread. So this is his personal opinion. I've pasted what he had to say:
"Regarding this ping and server nonsense, I've given the official position before, but apparently everyone only pays atention when they want to whine about something.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (49)
.:Back to Top:. |
|
|
|
| Quakecon Qualifiers Rounds Out 16 |
| Posted on Sunday, June 29, 2003 at 08:36:44 PM | Pravda |
|
| |
Last night, 4Kings and Infensus were both able to shut out their opponents in dominant fashion and officially pave their way to Quakecon, adding two additional teams to the European representation at Dallas this year. With those two games over, it marks the official end to the Quakecon qualifiers as the 16 top teams have emerged to take their places for the quest for $20,000. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (6)
.:Back to Top:. |
|
|
|
| X-Cast.Net Planet-RTCW.com show download |
| Posted on Sunday, June 29, 2003 at 12:52:30 AM | cK AnimeMan |
|
| |
The X-Cast.Net Planet-RTCW.com show download is now availible from this site, and should be on the x-cast.net site soon as well. Just click on the downloads link on the left, or click here.
Great deal of thanks for all those 100+ who tuned in, and those who we interviewed. Hopefully our show will just get better and better with time, like wine. Ciao. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| My Matches of the Day |
| Posted on Saturday, June 28, 2003 at 06:32:45 PM | Pravda |
|
| |
Tonight's Quakecon qualifiers features a great doubleheader that can't be ignored. These games will also be the last two qualifier matches and will finally round out the top 16 teams that are invited to the Adam's Mark Hotel for a big battle for the first prize of $20,000.
Saturday, Jun 28, @ 06:00pm Four Kings Intel. vs.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| CAL Main Struggles to Stay Alive |
| Posted on Friday, June 27, 2003 at 06:53:47 PM | Pravda |
|
| |
This week of CAL Main was disheartening as several teams including 7 Angels, Steel, Team Fuzed, and Bomb Your Enemies forfeited their matches. Some of these teams have already disbanded and will no longer play. With the presence of Quakecon qualifier matches, many teams have also placed their focus outside of CAL. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| Thursday Night Fights for the Journey to Quakecon |
| Posted on Friday, June 27, 2003 at 05:10:36 AM | Pravda |
|
| |
Amish World Order and Amnesia played their hearts out for an extremely close battle to the finish which even featured Quakecon 2003 qualifier's first fifth round overtime match. In the end, the Amish were able to prevail victoriously putting a finish to the game as they patiently planted the last round. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (11)
.:Back to Top:. |
|
|
|
| My Match of the Day |
| Posted on Thursday, June 26, 2003 at 09:08:22 PM | Pravda |
|
| |
Thursday, Jun 26, @ 08:30pm Amish World Order vs. Amnesia
Ah, I know this is a bit late because I just got off work, but here it is, my match of the day:
This is a great game where I see no favorites or upsets, but rather a toughly fought out match that will very closely decide who is more deserving of a spot at Quakecon 2003.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (10)
.:Back to Top:. |
|
|
|
| More Euro Insight on Playertrackers |
| Posted on Thursday, June 26, 2003 at 06:30:35 AM | Pravda |
|
| |
This week on Playtertrackers, we take a look at Zaf from the successful Gamepoint.amd who managed to win Round 2 of Quakecon qualifiers this week against Clan Carnage to seal themselves a spot at the big tournament. Zaf and company expect to pose a threat to anybody whose goal is to take home the $20,000 RTCW prize this year. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| Quakecon Results of the Day |
| Posted on Thursday, June 26, 2003 at 03:41:16 AM | Pravda |
|
| |
Ocrana D-Link > Reformation
Clan Kapitol > Clenched Fist
Good games guys. And to anybody watching WTV, yes, I nooblared it up. =) And for those who haven't seen it:
1) I tossed a nade toward my own engineer in the garage and killed him (almost gibbed).
2) I went down a ladder to revive a teammate and pulled out my console last second.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (6)
.:Back to Top:. |
|
|
|
| My Match of the Day |
| Posted on Wednesday, June 25, 2003 at 08:15:29 PM | Pravda |
|
| |
Wednesday, Jun 25, @ 09:30pm Clenched Fist vs. clan Kapitol RTCW
Quite literally. Yours truly as a member of Clan Kapitol faces off against Clenched Fist, a formidable foe. Their lineup is a list of good players, many from CCCP. The reincarnated Clenched Fist is led by Aimology who helped the old Clenched Fist of yesteryear take a CAL-Main runner-up spot many a CAL season ago.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (3)
.:Back to Top:. |
|
|
|
| Clanbase RtCW AmeriCup Delayed |
| Posted on Tuesday, June 24, 2003 at 05:46:23 PM | Soma)x( |
|
| |
Clanbase Americup, the first North American cup by clanbase, will be delayed 1 week till after Quakecon 2003 qualifiers are over. This gives everyone one last chance to sign up. So far the signed up teams are.
Damage Incorporated
clan Kapitol
Total Annihilation Factor
Team-Effect
We Aren't Trying
Minions Of Rage
Team Kinetic
Admin Clan
The Immortals
Team Yakuza!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| Upcoming Match Preview Interviews |
| Posted on Monday, June 23, 2003 at 07:18:34 PM | Pravda |
|
| |
Mr. Selfdestruct has done a fine job in investigating the upcoming matches in grand fashion: interviews with those from the European scene.
Thursday, Jun 26, @ 09:30pm NARF!!!!11 vs. Fear Factory - resist
NARF vs Fear Factory Resist is a match that few know about as Fear Factory Resist has gotten little publicity in the past and is a relatively new team in the European scene.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (6)
.:Back to Top:. |
|
|
|
| My Match of the Day |
| Posted on Monday, June 23, 2003 at 07:14:26 PM | Pravda |
|
| |
Monday, Jun 23, @ 08:00pm dot vs. west Side wolves
Much talk has been made concerning the bracket placement of these two teams which pits the best team in Australia against a top team in the United States. Though it has been predicted on several occassions that Dot may perhaps pull off an upset, the future I see is much more bleak. I will be honest.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| CAL Main Tightens Up |
| Posted on Friday, June 20, 2003 at 07:57:46 PM | Pravda |
|
| |
This week's CAL Main matches on Ice provided ultimate excitement and a batch of upsets that should shake things up in the predictions and standings.
Both teams were unable to pull off a win in the Quakecon qualifiers, but Operation Psycho Patrol was able to shut the naysayers up, put in a hard game, and prevail in the end in what was a very close victory against the favored RedruM 3-2.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (4)
.:Back to Top:. |
|
|
|
| Clanbase Americup Invites You |
| Posted on Friday, June 20, 2003 at 07:30:41 PM | Pravda |
|
| |
Clanbase.com, the popular and premier RTCW gaming league for Europeans, has officially extended its league play to America, offering the same type of intense competition it does in Europe. The so-called Americup will be a fresh change from the current leagues around and will also offer a small taste of how European matches have been run. Rules are also slightly different including the well-known two maps in one match rule.
Currently, Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Double Dosage of Planet-RTCW Playertrackers |
| Posted on Thursday, June 19, 2003 at 07:06:36 AM | Pravda |
|
| |
This Thursday, I had the pleasure of interviewing two pro players. That's right, you get a double dose of Playertrackers courtesy of me. This is to make up for the absence of an interview two weeks ago.
The first player we check out is Vash from the English team, All Guns Blazing and formerly of 4 Kings Intel.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| Day 3 of Quakecon Qualifiers is Low Profile |
| Posted on Thursday, June 19, 2003 at 06:01:37 AM | Pravda |
|
| |
A smooth ride was experienced on the third day of Quakecon RTCW qualifiers as the upset bug was not as contagious as thought to be. The well known German team, Ocrana D-Link, was able to stomp through the first round against Order Thru Chaos while High Voltage did the same to their opponents, Clan [Q3] Quakecon. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| Day 2 of Quakecon Qualifiers Provides a Suprise |
| Posted on Wednesday, June 18, 2003 at 05:09:00 AM | Pravda |
|
| |
Day 2 of the Quakecon qualifiers was not as routine as yesterday as the biggest upset of Quakecon qualifiers so far, occured when Minions of Rage, a high caliber team from CAL-Main, were able to knock off one of Euro's finest teams in Rewind, reigning Clanbase Eurocup champions. This came as a big surprise as Rewind was more or less predicted to contend at Quakecon for the first prize. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (24)
.:Back to Top:. |
|
|
|
| -=Team Sportscast Network enters Enemy Territory!=- |
| Posted on Wednesday, June 18, 2003 at 04:25:02 AM | TsN|JeffT |
|
| |
For all RTCW fans out there, TsN|JeffT will be shoutcasting Enemy Territory TWL (www.teamwarfare.com) Stopwatch Ladder Thursday night at 10:00pm EST.
Goatse takes on Treehuggers in a blitz offensive effort to dethrone Treehuggers of thier #3 spot. Join JeffT at 10:00PM EST for all the ET heart-pounding action!
For more information, point your browser to www.tsncentral.com.
|
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Quakecon Qualifier Day 1 Results |
| Posted on Tuesday, June 17, 2003 at 05:17:59 AM | Pravda |
|
| |
Today marked the first day for the Quakecon RTCW qualifiers as several teams matched up on Ice in hopes of taking away the right from another team of going to Dallas to compete for the grand prize. In general, the favored teams did not disappoint as each rolled through their matches. Here are the results:
Affliction > Admin Clan
Trinity > panzer bitches
Team-Frontline > Devil Stomper Battalion QC
Infensus > P!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| The Other White Meat |
| Posted on Tuesday, June 17, 2003 at 12:58:51 AM | Pravda |
|
| |
With Quakecon qualifiers started tonight and several matches lined up and WTVed, there is the noticeable absence of TSN Shoutcasting coverage. However, perusing through IRC, I noticed there are other people shoutcasting tonight's Quakecon qualifier matches. Check out the XCast Network which has shoutcasters broadcasting the games all day. Their coverage does not stop at RTCW either. It extends to all Quakecon gaming this year. The official Quakecon shoutcasting station...
cast.net:8000/listen.pls" target="_blank">http://relay1.x-cast.net:8000/listen.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| GA Ladder Finals Round 4 |
| Posted on Monday, June 16, 2003 at 01:24:33 AM | mo*badass |
|
| |
GA Ladder Round 4 Finals kick off tonight with two corker matches being played on mp_ice.
First up sees the no 1 team in Aus (and our only hope at qcon) dot, take on the fearsome smg talent of the Nurses. Winner gets a week off, and a spot in the grand final.
Next up is last seasons champs Oxygen versus the ever improving Screaming Eagles.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| All New RTCW Trivia today 8:00 EST |
| Posted on Sunday, June 15, 2003 at 06:29:02 AM | -doNka- |
|
| |
Accelerate your typing! Re-read last RTCW news! All New RTCW Trivia will be hosted today on #kinetic.rtcw channel by K`donka. For those of you who don’t know what RTCW Trivia is, it’s a normal IRC trivia (question, answer) with RTCW related questions about game play, community, competitions, etc. Previous trivia had relatively big success among the people who came to play from the major community channels. Wat? Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| Qcon Qualifiers Round 1 |
| Posted on Sunday, June 15, 2003 at 06:03:00 AM | prod1gy |
|
| |
All matches will be played on mp_Ice
Monday, Jun 16, @ 06:00pm SnapS vs. Instant Defeat
Monday, Jun 16, @ 06:00pm infensus vs. P!mps
Monday, Jun 16, @ 07:00pm GamePoint vs. 502nd PIR
Monday, Jun 16, @ 07:00pm Team-Affliction RTCW vs. Admin Clan
Monday, Jun 16, @ 09:00pm Clenched Fist vs. Reconstructed
Monday, Jun 16, @ 10:00pm Team-Frontline vs. Devil Stomper Battalion QC
Monday, Jun 16, @ 11:00pm .:. Trinity vs.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (3)
.:Back to Top:. |
|
|
|
| Swertcw.com Cup |
| Posted on Friday, June 13, 2003 at 03:12:03 PM | Pravda |
|
| |
SWERTCW's hosted tournament has already kicked off and it should be interesting to pay attention to. Not only are there some top European teams involved, there are also a few American teams that signed up for a taste of the action: TAF, Clan Kapitol, Amish World Order, and Fx. The first round of matches will conclude by the end of this week. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Playertracker: Intact |
| Posted on Thursday, June 12, 2003 at 11:46:12 PM | Pravda |
|
| |
I realized last Thursday that I forgot to update the site with a new pro player for the Playertracker section. Little did I know, WarKrime from NARF would go behind my back and stab it...repeatedly...by becoming the first RTCW player featured in the cached.net's Playertracker section.
In order to redeem myself this week, I decided to interview someone from overseas. That's right, a Euro.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (4)
.:Back to Top:. |
|
|
|
| Planet-RTCW Private Servers for QuakeCon Scrims |
| Posted on Tuesday, June 10, 2003 at 06:52:41 PM | Pravda |
|
| |
Thanks to Soma for helping us set up two private planet-rtcw.com servers based in Houston, Texas. These servers will be up for teams to scrim each other under Quakecon configs. The server will have cvar settings that are concurrent with Quakecon restrictions and are open to all Quakecon clans who want to scrim with the settings. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| More Quakecon and CAL Open Fight Tonight |
| Posted on Tuesday, June 10, 2003 at 06:28:59 PM | Pravda |
|
| |
Last night Quakecon.org saw over 3000 people filing in to register for Quakecon 2003 at the Adam's Mark Hotel in Dallas, Texas. Within minutes, the Quake 3 1 versus 1 filled up and if you blinked your eye while registering, you probably got a waiting list spot. The BYOC Lan was not much different and if you haven't registered, you will now find yourself near the 600s in the waiting list. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| TSN @ QuakeCon 2003 |
| Posted on Sunday, June 8, 2003 at 06:11:17 PM | cK AnimeMan |
|
| |
Well it isn't over until the fat lady sings. As you are all aware by now, TSN is not allowed to cast at QuakeCon 2003, although they would like to. I have heard from many casters who were all set to go there and cast, even bought tickets and hotel rooms, but are now not able to cast the games they love, and we not able to hear our favorite casters. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (7)
.:Back to Top:. |
|
|
|
| CAL Open is Open |
| Posted on Saturday, June 7, 2003 at 08:54:15 AM | Pravda |
|
| |
If you haven't already noticed, for the past few weeks, Codewarrior, Carnal, Tariq and I embarked on a tough journey to integrate CAL-Open into the planet-rtcw.com system for predictions and stocks. That journey has finally come to a very successful end. Thanks to the three guys for rounding up as many CAL-Open clans as possible to register them for the site and for setting up the schedules and predictions system. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Petition to use CAL cvar limitations at Quakecon |
| Posted on Saturday, June 7, 2003 at 03:50:20 AM | s|Arachnyd |
|
| |
Quakecon 2003 will be the largest RTCW event our community has seen yet. Naturally, those who are competeting want to be allowed to play in a way most comfortable to them. Many of you remember the controversy last year over the last minute announcement of the rather extreme cvar restrictions used in the Quakecon 2002 tournament. CG_Drawgun 1, r_picmip 1, Lightmap, it was all very irritating to be forced to play like that. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (4)
.:Back to Top:. |
|
|
|
| How To Be a Pro Gamer 101 |
| Posted on Wednesday, June 4, 2003 at 05:26:38 AM | Pravda |
|
| |
Thanks for Steme for this little tidbit:
Apparently there's a teacher out at Southern Methodist University who plans on teaching a class centered around becoming a professional video game maker.
David Najjab is an educator with an unusual problem: He's trying to lure students who are serious about making a career out of fun and games.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| sweRTCW Cup |
| Posted on Monday, June 2, 2003 at 01:44:14 PM | prod1gy |
|
| |
sweRTCW cup is a euro tournament, but they accept teams from the states. 64 teams have signed up so far, registration closes this Friday 23.59 CET. Some U.S teams signed up including cK, [TAF], Amish and [FX]. This weekend the cup tree will be finished, and they will have a huge lottery live on irc to fill up the spots, #RTCW.se (Quakenet) sunday 21.00 CET. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (8)
.:Back to Top:. |
|
|
|
| New Demo Player Thingy.... |
| Posted on Monday, June 2, 2003 at 06:17:16 AM | cK AnimeMan |
|
| |
Ever want to see every pov in a demo...but alas its not a multi view demos? Well there is a new program out named Demo Extender which allows you to just that.
how do I use it ?
=================
unzip this archive into {PATH_TO_RTCW}/edv/
run the mod via, options->mods->extended demo viewer
run your favorite rtcw demo (/demo yourdemoname), the demo must be placed in the "edv/demos" folder. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (4)
.:Back to Top:. |
|
|
|
| GA Ladder Finals Round 2 |
| Posted on Monday, June 2, 2003 at 01:08:35 AM | mo*badass |
|
| |
Tonight at 8pm sees Round 2 commence of the GA Ladder finals. All matches will be played on te_frostbite.
Monday 2nd 8pm (6am EST)
#1 . dot (minor champs) v #4 o2 Oxygen (defending champs) - Winner gets round 3 bye
Monday 26th 10pm (8am EST)
#2 |+| Nurses v #3 =SE= Screaming Eagles - Winner gets round 3 bye
Tuesday 27th 8pm (6am EST)
#5 [Rok.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Enemy Territory Released |
| Posted on Thursday, May 29, 2003 at 07:00:12 PM | Pravda |
|
| |
For those of you still not in the know, iD's Enemy Territory has been officially released as well as their press release on Yahoo Finance:
Featuring multiplayer support for up to 32 players, Wolfenstein: Enemy Territory is the ultimate test of communication and teamwork on the battlefield. Players join the fray as one of five distinct character classes each with unique combat abilities.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (9)
.:Back to Top:. |
|
|
|
| Once, Twice, Three times a lady..... |
| Posted on Sunday, May 25, 2003 at 06:08:12 PM | cK AnimeMan |
|
| |
Well, only two times so far, but how many times does it take. Wyldcard has been caught cheating in Quake 3 on May 18, 2003 now. His quake 3 guid was 3647ee8d, which matches the second guid on http://pb.speakeasy.net/pbbans.dat . This comes up after him getting caught wallhacking in sof2. I will say it up front, I don't like cheaters. If you cheat, expect your name to get plastered on my site. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (33)
.:Back to Top:. |
|
|
|
| QuakeCon Looking for Volunteers and More... |
| Posted on Friday, May 23, 2003 at 05:50:14 PM | Pravda |
|
| |
The QuakeCon.org site is now looking for volunteers for this year's QuakeCon and has put up a volunteer registration form (not the official quakecon registration). Volunteer spots that are open include just about all kinds of work and they are looking for dedicated volunteers not people who will hang around for a few minutes and leave.
We need all kinds of people this year for network setup, registration, security, and more.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| Possible Addition of CAL-Open Into the System |
| Posted on Thursday, May 22, 2003 at 02:05:19 AM | Pravda |
|
| |
Since this website is geared toward competitive RTCW, it is without doubt that we will try our best to bring you all CAL coverage. Over the last few weeks, we've implemented two sections of RTCW CAL: Invite and Main. That leaves out Open. The reasons we were hesitant to bring CAL-Open over into our systems was because Open has a ton of teams, many that are new and many that might drop out. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (16)
.:Back to Top:. |
|
|
|
| A Config Consortium |
| Posted on Monday, May 19, 2003 at 11:36:16 PM | Pravda |
|
| |
Shatter has submitted an article to the site regarding his config consortium, essentially a website that holds different Wolf cfgs from several different players. Shatter writes:
Just wanted to get the word out for those of you that may not know about the site. The Config Repo is a community resource geared at storing/sharing configs for RTCW. There are more than 100 configs at the moment, ranging from your basic, stock wolfconfig_mp.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (1)
.:Back to Top:. |
|
|
|
| TWL Invite Predictions Reset |
| Posted on Monday, May 19, 2003 at 07:42:32 PM | Pravda |
|
| |
I had to reset the predictions on the TWL Invite section because the wrong map was cited (UFO Foofighter). The correct map was replaced: mp_base. If you already predicted, please re-input your predictions. Also, TWL Invite predictions are a part of the stock system and the TWL results do affect team stocks. Thanks for the inconvenience. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| TWL Invite Added to Predictions System |
| Posted on Sunday, May 18, 2003 at 08:59:48 PM | Pravda |
|
| |
As you can see on the bottom left in the Predictions section, TWL Invite has been added to the system. Anybody who is already accepted as a predictor for CAL-M or CAL-I is welcomed to predict for the TWL Invite section. If you participate in the TWL league or would like to predict for TWL Invite and have not been accepted, you can reply to this news post with your log-in name for prediction access. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| CyberX Gaming = Big Money? |
| Posted on Friday, May 16, 2003 at 07:04:58 PM | Pravda |
|
| |
Recently Cyber X Gaming has announced their qualifiers for their World Games competition. The locations are posted here and include such places as Dallas, Texas; Chicago, Illinois; and Los Angeles, California. There are also several European locations. These qualifiers take place throughout June and July of 2003 and each qualifier offers lots of cash and prizes (there is a fee to enter the qualifier as well).
The featured Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (3)
.:Back to Top:. |
|
|
|
| CAL-Main Results and More |
| Posted on Friday, May 16, 2003 at 05:31:33 AM | Pravda |
|
| |
EuroStandard > Steel 3-0
Elements of Destruction > Cutthroat 3-1
Minions of Rage > Excessive 3-0
Clan nyX > Cause 4 Concern 3-2
The Immortals > We Aren't Trying 3-2
Team Arise > Deathtouch 3-2
Team Trinity > Operation Psycho Patrol 3-0
Team Exodus > Masters 3-0
Bomb Your Enemies > Collateral Damage 3-2
Clan Carnage > Aiming Impaired 3-0
7 Angels > Redrum 3-2
slateoon > Guerrilla Warriors 3-0
Intense Combat Forces > LAW 3Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (8)
.:Back to Top:. |
|
|
|
| CAL Main Kicks Off Tonight |
| Posted on Friday, May 16, 2003 at 12:08:07 AM | Pravda |
|
| |
CAL Main RTCW kicks off in grand fashion tonight with some very good matches. This season, expect the unexpected, as teams line up for what could become an extremely tight race for the CAL-M championships. In addition, many new faces have emerged as well as reincarnations of some classic RTCW clans to add to the usual competitive pool of teams. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| Pro-Gaming Takes One Step Forward |
| Posted on Thursday, May 15, 2003 at 06:50:08 PM | Pravda |
|
| |
From ESPN, Marc Stein's article on the Spurs-Lakers playoff match:
"Some of you watching the ending, like us, will struggle to envision how these Spurs -- Tim Duncan and David Robinson and the newbies around them -- can close out the champs, if they couldn't finish off a Game 5 they were dominating."
If Stein's next article uses the term "buddylee" then mark it down folks, ESPN is going to be covering RTCW! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (6)
.:Back to Top:. |
|
|
|
| BOB2 comes to a surprising end! |
| Posted on Tuesday, May 13, 2003 at 08:32:21 AM | cK AnimeMan |
|
| |
"Two men enter, one man leaves." Quoth the Mad Max of Thunderdome. Today it was deathTouch(affliction) who was able to come out of the proverbial ThunderDome known as Battle on Das Beachhead 2.
In a stunning 3-0 upset of Narf on beach, a Narf team who had stumped dT just a month ago on the same map for the Cal-M finals were not able to do so again.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (9)
.:Back to Top:. |
|
|
|
| BoB2 RTCW Championships Tonight on TsN |
| Posted on Monday, May 12, 2003 at 06:13:14 PM | TsN|Warwitch |
|
| |
TONIGHT (05/12/03): OGL's Battle on Das Beachhead 2 Tournament is coming to a rousing close featuring the two greatest teams in modern RTCW history!
Grab that shortwave radio - here is what TsN has planned on shoutcast tonight:
Darkside vs Team Z @ 9pm EST! - Battle for Third Place w/ Archvile and Sabo!
NARF vs Deathtouch (Affliction) @ 11pm EST! - Uber Championship w/ Deeay and Warwitch!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (8)
.:Back to Top:. |
|
|
|
| Get Your Word In |
| Posted on Saturday, May 10, 2003 at 06:50:39 AM | Pravda |
|
| |
With the NARF vs Deathtouch (Affliction) match coming up this Monday to decide the Battle of the Beachhead 2 champions, it's important to hear what you think will happen. This is going to be a huge one, a rematch on beach between the two top teams right now. Another overlooked match is the one between Team Z and Darkside for the 3rd best team in BoB2. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| The Final Four Commence |
| Posted on Thursday, May 8, 2003 at 09:34:24 PM | Pravda |
|
| |
Tonight's BoB2 comes down to the last four teams left in the tournament: Darkside, Deathtouch, NARF, and Z. The night will end with only two teams left standing to take on each other. But for now, we take a look at the two big matches of the Final Four.
NARF vs Z
The NARF and Team Z match holds up to something of a match of David and Goliath proportions.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| Talking to Fatal1ty on IRC |
| Posted on Thursday, May 8, 2003 at 03:19:36 AM | Pravda |
|
| |
Team 187 headed by Shogun hosted Fatal1ty, the professional gamer who has attended and won several money tournaments such as UT2k3 and has been featured on MTV's Life show, for a brief chat session with the gaming community. Over a hundred people filed into the 187 IRC room to hear what he had to say. I edited the massive chat text from my log where cK-Silencer attempted to organize the questions. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| Your Predictions on the Final Four for BoB2 |
| Posted on Sunday, May 4, 2003 at 08:17:08 AM | Pravda |
|
| |
Since the ever popular Predictions section is not enabled for BoB2 and we all know that you RTCW gamers love to predict the games, there is a new topic in the Predictions thread that involves predicting the final four for BoB2. If you're not already registered for the forum, do so now! It only takes a second. Yes, a second for a lifetime of fun! Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| BoB2 elight 8 round completed. |
| Posted on Saturday, May 3, 2003 at 02:17:56 PM | prod1gy |
|
| |
Narf defeated HV with a 3-0, to advance into the next round.
With the elite 8 round completed, we are left with the following teams in the top 4:
NARF
Z Unit
DarkSide
Affliction
The schedule for the semi finals is not posted yet, make sure you hit the forums and make your predictions.
In other news new CAL and TWL seasons are starting up, make sure you sign your team up.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| Dark days looming ahead? |
| Posted on Friday, May 2, 2003 at 12:03:51 PM | cK AnimeMan |
|
| |
Well, I didn't give much thought to the wallhack that we posted about earlier, until I decided to see how "hard" to find it was.... I was severly dissapointed, it took me almost 2 minutes of googling to find it =\, further more I also found out the same hack shown below, also works in SoF2, RTCW, ET, Quake3, and even Doom 3 leak.
Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (3)
.:Back to Top:. |
|
|
|
| BoB2 elite 8 matches conclude tonight |
| Posted on Friday, May 2, 2003 at 12:00:07 PM | prod1gy |
|
| |
BoB2 continues tonight with NARF vs. High Voltage battling it out on mp_ice @ 11:00 PM EsT! Warwitch and Wonderdog will be shoutcasting on TSN (#tsn @ gamesnet), also WolfTV will be available (#gtv @ Gamesnet). Make sure you tune in to find out who will join -a-, D|S and Z in the bob2 top four list! |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Darkside Powers Through to Final Four BOB2 |
| Posted on Friday, May 2, 2003 at 07:22:23 AM | Pravda |
|
| |
In a match that was predicted to be very close, Darkside was able to muster its troops together and shoot their way through to the next round over Locked on Target on Ice. With the exception of one round, LoT's Ice defense simply did not have an answer for the Darkside offense which was able to break times and set short rounds. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| RTCW Wall Hack Exists |
| Posted on Thursday, May 1, 2003 at 10:17:29 AM | Pravda |
|
| |
A wallhack has been recognized by a few of the RTCW community and is now being shown to us officially. Gearbolt has screenshots of this wallhack in action as well as an avi of it. Unfortunately, at the present moment, it is not detected by Punkbuster. However, those who do abuse the exploit will display odd action during gameplay such as running into walls or aiming at targets behind walls in anticipation. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (12)
.:Back to Top:. |
|
|
|
| Cyber X Gaming $300,000 Tournament ! |
| Posted on Wednesday, April 30, 2003 at 12:51:12 PM | prod1gy |
|
| |
Cyber X Gaming has announced a $300,000 tournament that will include Quake 3, Counter-Strike and RTcW. Staring June 15, 2003 there will be qualifying events for the Cyber X Gaming World Games. These 35 events will take place throughout the North America and Europe. CXG will manage and schedule all qualifying activities and each will maintain consistent rules and regulations. Check out their site Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (5)
.:Back to Top:. |
|
|
|
| The Long and Winding Road to BOB2 |
| Posted on Thursday, April 24, 2003 at 06:15:33 AM | Pravda |
|
| |
Today's BOB 2 matches featured some rather lengthy, but intense action with a few big surprises. The underdogs tried their best and even though they put up a tenacious fight to the end, they were unable to power through to the next round.
We start off with Nyx against Z which featured a game that was favored toward Z.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| Enemy Territory Official Test Out |
| Posted on Thursday, April 24, 2003 at 05:52:23 AM | Pravda |
|
| |
The Enemy Territory map test is officially out. This game is completely free and entirely stand-alone AKA you do not need RTCW to run it. The minimum system requirements are:
Windows® 98/ME/2000/XP OS (Windows NT 4.0 not recommended for clients)
100% Windows® 98/ME/2000/XP compatible system (including all 32bit drivers)
Intel® Pentium® III 600Mhz processor or equivalent
128 MB RAM
32 MB video card
Microsoft® Direct X® 8.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (4)
.:Back to Top:. |
|
|
|
| Planet RTCW's very own live broadcast... |
| Posted on Saturday, April 19, 2003 at 08:11:09 AM | cK AnimeMan |
|
| |
Well its not live anymore, but if you missed out on our spur of the moment friday night interview/jam session with many known players in the community TOO BAD... Just kidding, I actually figured out how to record it, and it worked, so after a little editing of just the gaps we had here and there, it is available for download now. Hit up the downloads section under files, or if you're lazy, ... Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| Planet-RTCW Shoutcast Show on in 15 Minutes |
| Posted on Saturday, April 19, 2003 at 02:47:21 AM | Pravda |
|
| |
Me and Animeman are putting up a shoutcast in 15 minutes about BOB2, recent CAL playoffs, QuakeCon 2003, anything RTCW related. This is relatively impromptu and if it is successful, we might try doing it more often. Come on to #planetrtcw on gamesnet for more info and if you want to be interviewed or make a statement, you can PM am|Animeman. Also, I will post the link to the shoutcast here once we're on live. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (3)
.:Back to Top:. |
|
|
|
| Team Affliction is back! |
| Posted on Thursday, April 17, 2003 at 02:39:44 PM | prod1gy |
|
| |
Last night there was some conflict in the deathtouch squad 1 camp resulting in a split between them and their leader DimMaK. The Rest of Squad one consisting of Hollywood, Brian, Nail, Illumina, Rok, Decka, Slizznut and Slag have reformed Team Affliction, with Brian and Slizznut being the only original members. There’s also some news about one more player tagging up within a week, though it’s just a rumor. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (6)
.:Back to Top:. |
|
|
|
| CyberX Gaming Will Host RTCW Tournaments |
| Posted on Wednesday, April 16, 2003 at 10:55:20 PM | Pravda |
|
| |
Good news for those of you who consider yourselves "pro gamers." LoT-Soma has informed me that CyberX will host an international LAN tournament, the CyberX World Games, next year around January and will now include Return to Castle Wolfenstein in the mix as one of the tournament games. This tournament will include around $600,000 worth of prize money. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (8)
.:Back to Top:. |
|
|
|
| BoB2 on TSN Wednesday Night! |
| Posted on Wednesday, April 16, 2003 at 06:55:47 PM | cK AnimeMan |
|
| |
And tonight tsn has 2 village matches lined up from the second round of bob2.
Wednesday, April 16th @ 09:00PM EST ViB vs. Uprise playing RTCW(Stopwatch) for BOB2(Round 2) on Server1 with Archvile, Sabo
Wednesday, April 16th @ 11:00PM EST Aftermath vs. 502nd PIR playing RTCW(Stopwatch) for BOB2(Round 2) on Server1 with JeffT, Justice
GL to all teams playing tonight.
TSNCentral.com |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| War of the Sandbaggers |
| Posted on Tuesday, April 15, 2003 at 11:12:11 PM | SilentsTorm |
|
| |
There can be only one....With what is predicted to be a close 3-2 match either way. The Outsiders take on Redemption for the Cal-Open title. Tune in to TSN to listen to WarWitch shoutcast what is sure to be a awesome match. The match starts at 10:30 est and will be covered by WTV as well.
bring your popcorn, case of bud, and leave the lil ole lady on the couch.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| Enemy Territory Approaches Beta Testing |
| Posted on Tuesday, April 15, 2003 at 10:05:04 PM | Pravda |
|
| |
Apparently the people from http://www.planetwolfenstein.com have received word directly from Hellchick of Activision that the Enemy Territory beta will be forthcoming. This is straight from planetwolfenstein.com:
YES! The moment we've all been waiting for is near, the release of RtCW: Enemy Territory is just a public test away! Thanks to Activision's Hellchick for passing along the following note:
We're currently doing a private beta of a Wolfenstein: Enemy Territory test.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| TWL Announces a New League Format |
| Posted on Tuesday, April 15, 2003 at 06:10:46 AM | Pravda |
|
| |
A few clans may have received an email today by ZedsDead! from TWL announcing a new league that will be out for the Team Warfare Ladder. Here is a copy of the email:
Dear Team captain,
The Team Warfare League is proud to present you and your team the opportunity to play in our first Invite RTCW league. Due to your team's outstanding achievements and extraordinary accomplishments in RTCW.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| BoB2 Results for Round 2 |
| Posted on Tuesday, April 15, 2003 at 06:04:53 AM | Pravda |
|
| |
As predicted, the match between The Admin Clan and Deathtouch 2 was exciting and ended with a victory for dT2 3-1 with the fourth round being very close as The Admin Clan attempted to hastily rush back with the gold as the clock was winding down when at the 13 second marker, the gold was returned by the relentless Axis chasing down the objective carrier. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (1)
.:Back to Top:. |
|
|
|
| BoB2 Predictions for Week 2 |
| Posted on Sunday, April 13, 2003 at 04:54:12 AM | Pravda |
|
| |
Apocolus from GAT and WarKrime from NARF have jointly submitted their predictions on what will occur during Week 2 of BoB2 as well as who will advance in the tournament. They predict the scores and analyze each game in the bracket for some interesting results including this nail-biter that could have been the CAL-O finals matchup:
Redemption vs Cause4Concern
Warkrime says:
Good matchup here.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (1)
.:Back to Top:. |
|
|
|
| Frostbite TE released |
| Posted on Saturday, April 12, 2003 at 08:49:21 PM | cK AnimeMan |
|
| |
Looking on the forums this morning, it looks like moonkey has released the final version of his frostbite map. Hop on our forums for some links to download his map. Forums
This is one of the rare custom maps that actually got good feedback originally, and then the mapmaker listened to what everyone wanted changed, changed it, and released it. I really hope cal looks into this map.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| What Has Become of Enemy Territory |
| Posted on Saturday, April 12, 2003 at 12:45:08 PM | Pravda |
|
| |
Computerandvideogames.com released an interview yesterday with Paul Wedgewood, the lead game designer for Enemy Territory. As most of you remember, Enemy Territory was an expansion project that was eventually cancelled by iD and instead, handed over to Splash Damage (who are responsible for mp_dam, mp_rocket, and mp_tram).
Now, instead of being a retail expansion pack for RTCW, it will simply become a standalone multiplayer-only game free to download.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (1)
.:Back to Top:. |
|
|
|
| Narf Wins Cal Main |
| Posted on Friday, April 11, 2003 at 04:14:02 AM | cK AnimeMan |
|
| |
Well, I cant explain it, or describe it, but it was an amazing game. Narf takes dT on beach 3-1-1. The game was very close, and I hope anyone who missed it to download the wtv demo which i am sure will pop up on cached. Congrats to Team Narf on thier 2pete, and GG's to dT for a very good season. RTCW, still the best spectator game _ever_. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (8)
.:Back to Top:. |
|
|
|
| Game Time Predictions |
| Posted on Thursday, April 10, 2003 at 09:35:05 PM | Pravda |
|
| |
The Super Bowl of RTCW kicks off tonight at 10:30PM EST, 7:30PM PST and will be shoutcasted as well as shown on Wolf TV. TSN (www.tsncentral.com) will shoutcast featuring Warwitch, Sabo, and Archvile (there is also a pre-game show around 9:30 you do not want to miss which will have Animeman on). The WTV link can be found in #gtv (gamesnet server). Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (3)
.:Back to Top:. |
|
|
|
| Exact QuakeCon Hotel Rates |
| Posted on Thursday, April 10, 2003 at 06:17:04 PM | Pravda |
|
| |
Taken straight from Quakecon.org:
"There has been some confusion regarding the specially negotiated room rates we have arranged for attendees staying at the Adam's Mark hotel. First of all, in order to receive the rates, you must actually CALL the hotel's toll free line (1-800-444-2326). You will not get the reduced rate by reserving online. You must also specifically mention "QuakeCon" or "id Software" to the representative you speak with.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Dem Fighting Words |
| Posted on Wednesday, April 9, 2003 at 06:56:41 AM | Pravda |
|
| |
There now stands two clans left on the brink of taking home the most precious RTCW prize, the CAL-M championship trophy. Only one clan will remain standing amidst the rubble of airstrikes, MP40s and potato mashers. But this game isn't just about a CAL-M title or championship. No, this game is about pride, fragile egos, long-standing bragging rights, and the ability to confidently say to the other team, "I own you."
That's right.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (1)
.:Back to Top:. |
|
|
|
| QuakeCon 2003 Official Date and Location Up |
| Posted on Wednesday, April 9, 2003 at 12:26:05 AM | Pravda |
|
| |
QuakeCon 2003 will be held in a slightly different location this year: Dallas, Texas at the Adam's Mark Hotel instead of ID's headquarters at Mesquite. The date set is August 14-17, 2003. This is straight from http://www.quakecon.org :
"To reserve a room, call the Adam’s Mark Hotel at (800) 444-2326. To receive our specially negotiated room rates, QuakeCon attendees should inform the reservation desk that they’ll be at the hotel for QuakeCon.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (4)
.:Back to Top:. |
|
|
|
| TSN Tuesday night! |
| Posted on Tuesday, April 8, 2003 at 07:19:47 PM | cK AnimeMan |
|
| |
Tonight TSN will be bringing you:
Tuesday, April 8th @ 10:00PM EST Outsiders vs. Cause 4 Concern playing RTCW(Stopwatch) for CAL(Open Playoffs, SemiFinal) on Server TBD with Warwitch.
Tuesday, April 8th @ 09:00PM EST Deathtouch2 vs. The Commission playing RTCW(Stopwatch) for BOB2(Round-1) on Server TBD with Warwitch.
Yay for more Warwitch casts!Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| BoB2 matches on TSN Tonight! |
| Posted on Monday, April 7, 2003 at 09:41:14 PM | cK AnimeMan |
|
| |
TSN is geared to bring you some exciting round 1 bob matches tonight, and I suspect every night during bob. Here is what they have lined up for tonight:
Monday, April 7th @ 09:00PM EST VIB vs. Vengeance playing RTCW(Stopwatch) for BOB2(Round-1) on Server1 with DeeAy, Sabo
Monday, April 7th @ 11:00PM EST cK vs. Eurostandard playing RTCW(Stopwatch) for BOB2(Round-1) on Server1 with Warwitch, trillian
As always check Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (4)
.:Back to Top:. |
|
|
|
| Australian RTCW |
| Posted on Monday, April 7, 2003 at 08:32:01 PM | Pravda |
|
| |
For our Australian readers and those interested, LoA-Majikshoe has written a very informative article including an interview with some of the top teams of Australian RTCW: cD and it's predecessor, dot. To get a little glimpse into the history of Australian RTCW ladder play and what has happened with these two teams, check the article sections. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (1)
.:Back to Top:. |
|
|
|
| Interview with Team Thorian and More BOB2 News |
| Posted on Monday, April 7, 2003 at 05:15:45 AM | Pravda |
|
| |
The_Whippuh has submitted a funny interview with Team Thorian, a BOB2 clan dedicated to the eccentric former RTCW trash talker, Thorian of Fusion fame. Go to the articles to read the interview.
Also, |HCC|Kuniva writes:
"The amount of teams approved for play in the BoB2 tournament now stands at 52.
64-52=12
That's right, only 12 spots left.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (4)
.:Back to Top:. |
|
|
|
| DeathTouch and NARF Previews |
| Posted on Sunday, April 6, 2003 at 12:55:44 PM | Pravda |
|
| |
In the Articles Section, |HCC|Kuniva has submitted his interesting preview of the CAL-M finals match between DeathTouch and NARF. I'd like to reiterate that anybody can submit articles about the match or RTCW in general and they will be posted on the site once I verify. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| More BoB2 clans accepted! |
| Posted on Saturday, April 5, 2003 at 08:15:16 PM | cK AnimeMan |
|
| |
It looks like the list was updated sometime this morning, with the grand total of clans accepted being around 35, a little over half. If your clan hasn't been chosen yet, don't frett, they are only half done. Be sure you have all your people on your roster fill out all the personal info that is needed, and make sure your roster follows thier guidelines (no less then 6, no more then 9). Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| DeathTouch vs DarkSide Match write up. |
| Posted on Friday, April 4, 2003 at 04:14:34 AM | cK AnimeMan |
|
| |
Prav made me promise to do a write up since he would miss this match, here goes.
What a game, everyone knew it would be a great game to watch. Although it was impossible to buffer winamp for 2 minutes to match the delay of wtv, which did take away a little from the game, it still could not take away what an exciting match it was.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (4)
.:Back to Top:. |
|
|
|
| DarkSide vs DeathTouch Pre-Game Chatter |
| Posted on Wednesday, April 2, 2003 at 07:50:04 PM | Pravda |
|
| |
RING RING RING!
What's that? The telephone? No, its the school bell for recess and all the kids are coming out to play. That's right folks, it's DarkSide vs DeathTouch, where when push comes to shove on the monkey bars, fists fly, little Timmy's teeth gets knocked out, and nobody comes back quite the same.
Matches don't get nearly as deadly or darker than this.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (1)
.:Back to Top:. |
|
|
|
| Doctors are Back to Give BOB 2 a Checkup |
| Posted on Tuesday, April 1, 2003 at 08:17:39 PM | Pravda |
|
| |
The Doctors, former Quakecon 2002 RTCW champs and well-revered CAL-i powerhouse are back for some Battle of the Beachhead 2 action. After retiring with a well-earned victory garnering the RTCW Quakecon championship last year in Mesquite, Texas and involving themselves in a short stint with the evil ranks of Counterstrike, the Doctors have decided to take one more shot at Return to Castle Wolfenstein. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (3)
.:Back to Top:. |
|
|
|
| Redemption Vs SI Cal East Finals! |
| Posted on Monday, March 31, 2003 at 08:37:07 PM | SilentsTorm |
|
| |
Aight....here you go, cal opens best of the east have a all out battle on assualt for the east conference title. In one of the most antcipated matches of the playoffs...it will be covered on WTV and shoutcasted by WARWITCH!!! on TSN...match time is 9:15 pm est...limited seating avaiable so get your popcorn and your koolaid...it's going to be a bumpy ride =) gl hf |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (3)
.:Back to Top:. |
|
|
|
| Semi-Finals Playoff Coverage by You |
| Posted on Sunday, March 30, 2003 at 11:15:31 AM | Pravda |
|
| |
Now that the CAL RTCW season is coming to a nice dramatic end with the playoffs, I'd like to make it more interesting with increased coverage on the site. The whole premise of this site was to cater to the competitive RTCW community and to get some of the players and clans involved. So far, it's been pretty damn successful, but I think it could be better. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| The Rest of the West |
| Posted on Friday, March 28, 2003 at 06:36:17 AM | Pravda |
|
| |
With Wicked forfeiting their game to Uprise due to Spring Break roster issues, the NARF vs Amish World Order matchup would have to make up for it and it did.
The match began slowly as NARF, using a pseudo-garage defense that relied on their communication, was able to put a full hold clamp on Amish's offense while pulling off a close plant to end the round 1-0.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Beasts of the East |
| Posted on Friday, March 28, 2003 at 04:58:30 AM | Pravda |
|
| |
Tonight's East CAL-M matchups pitted Darkside against High Voltage and Deathtouch against Team Z for some very interesting games.
Deathtouch and Z battled it out for an exciting game that was more than advertised, trading blow for blow with each other while never letting up, including a tie that involved two full holds on Assault.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (1)
.:Back to Top:. |
|
|
|
| Battle of Beachhead II Set to Begin |
| Posted on Wednesday, March 26, 2003 at 11:09:08 PM | Pravda |
|
| |
OGL has announced that the sequel to Battle of Beachhead will be set to go on. This tournament will involve 64 chosen teams composed each of 6 players to battle it out bracket style on different maps with each match consisting of 4 stopwatch rounds. This will hopefully be the precursor to summertime's Quakecon.
From planetwolfenstein.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| Stats parser for all your stats needs! |
| Posted on Tuesday, March 25, 2003 at 06:58:54 AM | |
|
| |
Ok after much work (or lack there of) I have finally decided to release a beta version of my stats parser. With this release, I am also renaming it from Q3F Stats to PsyberStats. The rename was basically required since from this point on the program will support any game that makes a logfile. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (3)
.:Back to Top:. |
|
|
|
| March Madness Ensues |
| Posted on Friday, March 21, 2003 at 04:54:50 AM | Pravda |
|
| |
DeathTouch continued their CAL onslaught against Flatline refusing to lose a single round for another consecutive week. Sweeping Flatline 3-0, they will face Z next week.
Z and LoT showcased an exciting game although hampered by ping problems for LoT. Z showed why it was no pushover, coming from the momentum of their victory against Darkside.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (3)
.:Back to Top:. |
|
|
|
| Fun Guys- RTCW Bracket Challenge |
| Posted on Wednesday, March 19, 2003 at 11:01:45 PM | Prime |
|
| |
With the upcoming CAL Main playoffs we’ve decided to start a bracket tournament. This was started by dT|Loru, but now there are numerous admins which are: Loru, mv, Prime, Evil-Doer, and Gunner. The tournament is much like the NCAA one. You start out with the week 1 matches and people make predictions on who will win and what the score will be. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (1)
.:Back to Top:. |
|
|
|
| The Cal-Main Playoffs |
| Posted on Wednesday, March 19, 2003 at 08:41:25 PM | cK AnimeMan |
|
| |
The Map schedule is as follows:
Village (East and West first round)
Assault (East and West second round)
Ice (East and West Conference Finals)
Beach (CAL-Main RTCW Championship)
The West seeds are as follows:
1st seed: NARF
2nd seed: Uprise
3rd seed: Wicked Crew
4th seed: Amish
5th seed: syztem
6th seed: Trinity
1st round: NARF (bye), Amish vs syztem, Wicked vs Trinity, Uprise (bye)
2nd round: NARF vs (awo syz winner), Uprise vRead more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Small tidbits and happenings for tonight. |
| Posted on Thursday, March 13, 2003 at 10:34:02 PM | Gearbolt |
|
| |
***Final Week of CAL Main Tonight***
The Final week of CAL Main happens tonight. Playoff seeds will be determined by tonights results.
TSN will be shoutcasting Team-Z vs dT at 8:30est time. Archvile and Trillian will be your shoutcasters for tonight.
Wolf tv will surely be at a match or two. Stop in #gtv on irc.gamesnet.net for match listings and connection info.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| Global Assault Team going inactive |
| Posted on Tuesday, March 11, 2003 at 05:57:05 AM | s|Arachnyd |
|
| |
I'm sad to report that due to roster issues GAT will be going inactive in CAL and TWL until next season. This is due to the fact that GAT only have 6 members active, and the rosters have locked. GAT will remain active in the OGL invite ladder, and will return to CAL and TWL next season.
GAT will also be recruiting one or two highly skilled players.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (8)
.:Back to Top:. |
|
|
|
| PunkBuster Woes |
| Posted on Tuesday, March 11, 2003 at 01:36:07 AM | cK AnimeMan |
|
| |
It seems the latest update of PunkBuster has been crashing PC's world wide, myself included. I thought it was my video card crapping out because it is basically on its last leg, but no, it was pb. As of now, with Cal open playoffs a couple hours away, and many clans with members just crashing, things dont look good for tonight. I sense a rash of disputes, problems, and general chaos all caused by pb. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| Death Touch Takes the OGG Tournament |
| Posted on Monday, March 3, 2003 at 05:00:08 AM | Pravda |
|
| |
Rounding out the day of OGG was Death Touch winning against Clan Kapitol on Chateau with a 3-1 victory. The times set were short and the match was short, but the game was fun nonetheless.
Also, I did a quick interview with Witchdoctor who ran the tournament along with Unholy. He discussed the future OGG tournaments, an interesting tournament version of 1v1 and 2v2 and other things to look forward to.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| Very nice week! |
| Posted on Sunday, March 2, 2003 at 03:43:39 AM | cK AnimeMan |
|
| |
That was a very sucessful week 1 for this site. We did just over 3 gigs of bandwidth in 1 week, which scares me. Psybers has just added the comment module on the article pages, as well as a counter for the articles. He also added an article ticker on the side of the page which displays the last 5 articles submitted. Last week was exciting, and prediction and participation was high, keep it up. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Death Touch Unstoppable; D|S over LoT 3-1 |
| Posted on Friday, February 28, 2003 at 05:00:30 AM | Pravda |
|
| |
Death Touch VS Animosity
Death Touch showed once again that they were the team to beat in the East with a dominant effort against the up-and-coming Animosity in CAL's Match of the Week. Combining timing, teamwork, and an unstoppable defense, they swept Animosity 3-0.
Illumina and Brian were each responsible for two document caps for Death Touch, setting respectable times from 4 minutes to 5 minutes.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (1)
.:Back to Top:. |
|
|
|
| New colors added. |
| Posted on Friday, February 28, 2003 at 12:48:49 AM | cK AnimeMan |
|
| |
Now you can use all the osp colors in your displayed names. For those who are wondering how to still get colors to show up in your name, do the following:
#1. Login
#2. Click on your Admin Panel.
#3. Under user maintenence, click modify user info
#4. under displayed named change it using this format:
^1Wo^5lf^3player will show up as Wolfplayer.
All the following colors are added:
ABCDEFGHIJKLMNOPQRSTUVWXYZ-=';,./\[]* |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| West Side Wolves Are Back |
| Posted on Thursday, February 27, 2003 at 03:41:51 AM | Pravda |
|
| |
The West Side Wolves are back after a break from RTCW with the original members: Exclusive, Elusion, Emaciator, and EvilKiller. A powerhouse of the west, placing a formidable 8th last year at Quakecon, wSw should add competition to the Pacific division by the next CAL season. In addition, look out for them in Quakecon 2003. Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (2)
.:Back to Top:. |
|
|
|
| A Chat with Dot from Down Under |
| Posted on Wednesday, February 26, 2003 at 08:46:17 AM | Pravda |
|
| |
I had the opportunity to have a nice, laid back chat with some members of Dot, CAL-RTCW's only clan from Australia who was brave enough to join CAL-Open despite major ping disadvantages. Tofu, Ringo, Flare, and Kosmix discuss their views on didjeridus, free-style rapping, and oh yeah, RTCW.
The interview can be found under the Articles Section. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (3)
.:Back to Top:. |
|
|
|
| Captains for RTCW:CD |
| Posted on Monday, February 24, 2003 at 08:24:12 PM | rand0m |
|
| |
--
Ontario:anomaly-redman-mkov-de_x_rules
Quebec:caseyjones-atomicfish-tekoda
California:Thorian-gnomish-mehdi-hostile-cynosure
North Carolina:Common
New Jersey:BTD-chaos-herbal-tea
Florida:ego-arachnyd
Massechusettes:grimdeath-odin
New York:warpath-snipes-ckyass
Pennsylvania:Madness-brian-fuman
Texas:Animeman-se7en
Virginia:Rapier-Illshot
--
I need all these people that are in this list here to plese message me on irc, dT|random.
Thanks |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (7)
.:Back to Top:. |
|
|
|
| Clan Kapitol Makes Their Comeback |
| Posted on Monday, February 24, 2003 at 07:38:23 AM | Pravda |
|
| |
Clan Kapitol makes a comeback to Return to Castle Wolfenstein after a hiatus and some brief stints with UT2k3 and Quake 3. Their past accomplishments include placing 3rd in CAL-Invite last year, 2nd in the Speakeasy Invitational as well as placing 3rd at Quakecon.
Their lineup has slightly changed with the notable absences of Czm because of college and Shogun because of work.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (1)
.:Back to Top:. |
|
|
|
| Interview with dT|Nemesis |
| Posted on Sunday, February 23, 2003 at 02:08:10 AM | rand0m |
|
| |
In the article section I have had a little chat with dT|Nemesis on the new tournament Return to Castle Wolfenstein : Continental Domination. To check it out head on over to the articles section and just click on the link that says interview with dT|Nemesis on RTCW:CD and read up about it. |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Cal-Main Results and next week Schedule |
| Posted on Saturday, February 22, 2003 at 06:05:11 AM | rand0m |
|
| |
This past week we saw the next clash in the CAL-Main scene. We saw a few nice games, and a
a few games that were just flat out blowouts. The best match you probably saw was Flying Hellfish vs.
Team Uprise since the games were so close. We saw alot of 3-0 which usually indicates that the games
were either blowouts, or just easy wins.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
| Flying Hellfish give up RtCW |
| Posted on Saturday, February 22, 2003 at 05:44:52 AM | tTt-Myth |
|
| |
Earlier this morning, The Flying Hellfish, one of the oldest Wolfenstein clans, decided to hang up their MP40's and take a break from competitive Wolf, thinning the herd in an already watered down Cal-M Western Conference.
Marauder, the leader and founder of The Hellfish, attributed the decision to lack of interest and dedication. "Some of us are just so burnt out. We don't even pub anymore.Read more... |
Edit this News Post | Delete this News Post
Submit News |
Read Comments (0)
.:Back to Top:. |
|
|
|
Team Special America. Very Special

Irc Channel:
irc.gamesurge.net,
#PlanetRTCW
Top Stock Prices
US/flagrant/139.92
US/np./139.78
US/blatant/109.97
US/LLC/109.08
US/dont-blink/108.99
Recent Articles
| Case for Sten |
(470 views)
(0 comments) |
| Sten - cool, but ultimately useless weapon. Fun long range, but not good enough for real play.
The problem is obvious - natural limitation - 10... |
| Movies 2008 |
(886 views)
(5 comments) |
| Here is a list I compiled of my picks for movies in 2008. There is nothing else really going on with this site, but I figured you guys would... |
|
Which map is missing from QuakeCon?
|
|
|
| |
|
|
|



 News
News
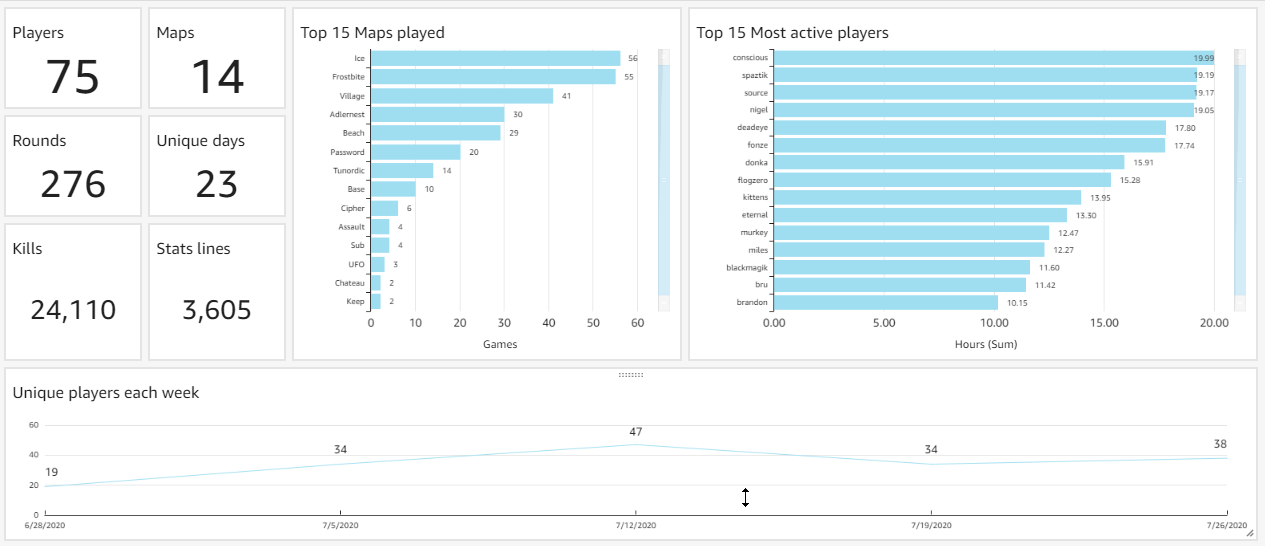

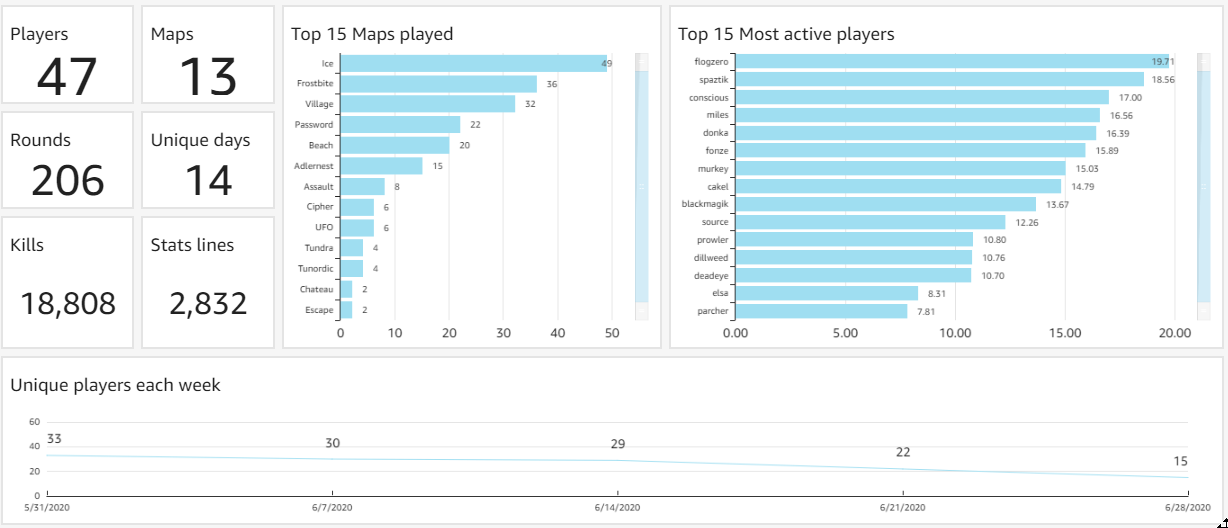
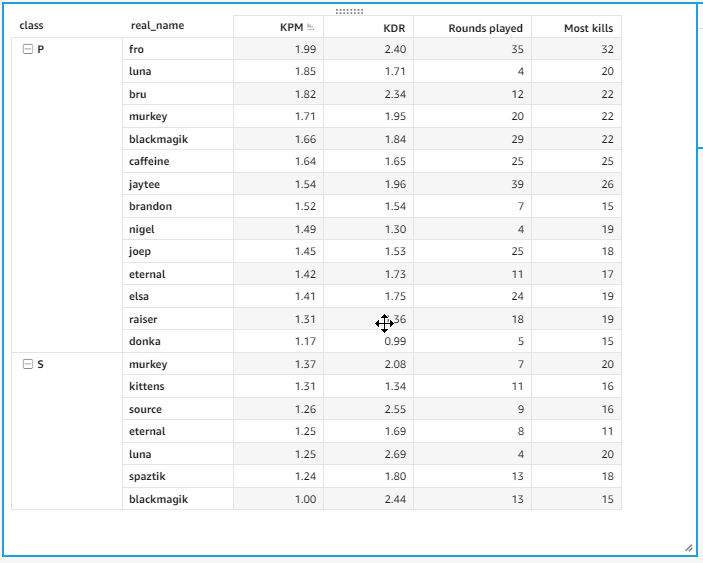
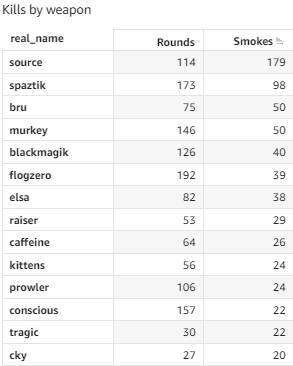
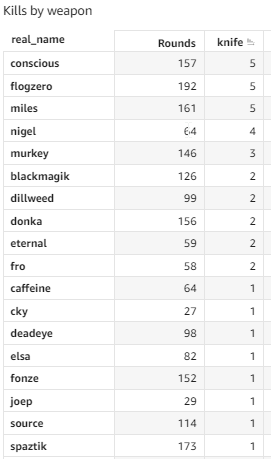
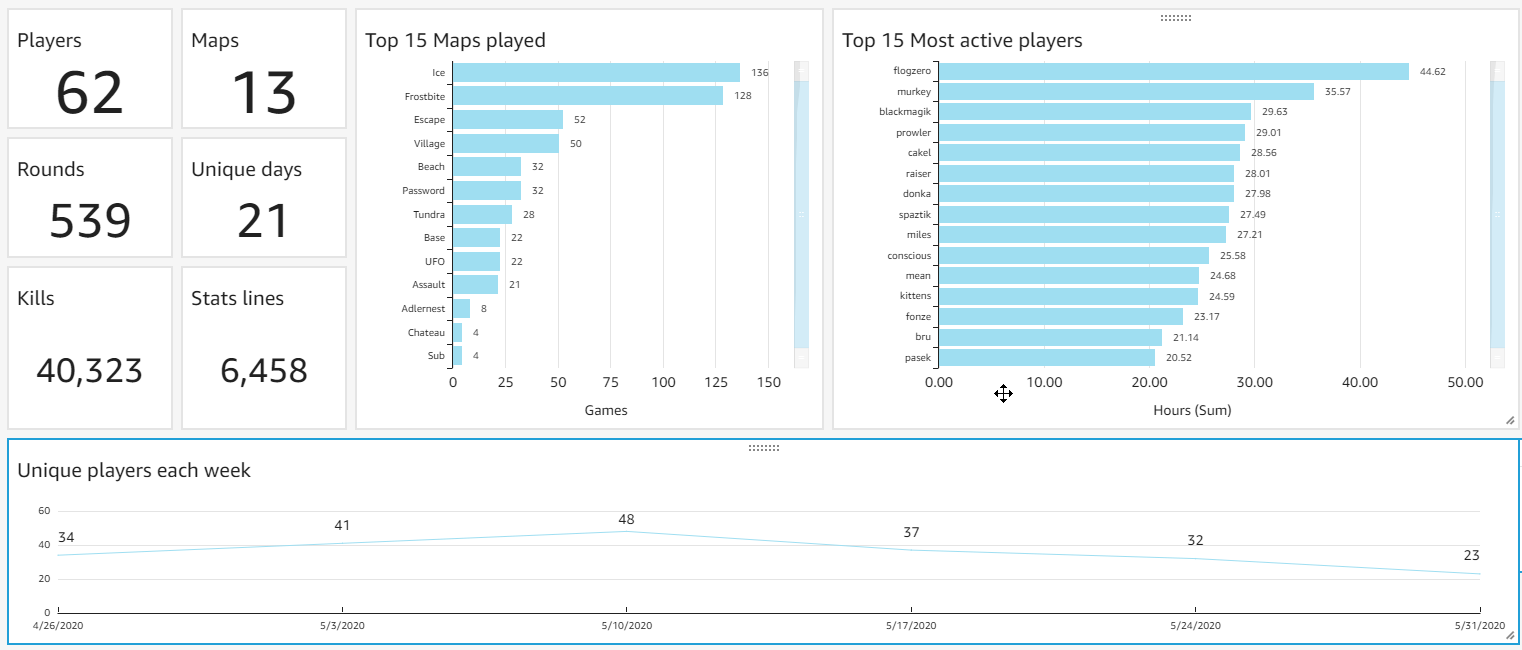


 Highbot
Highbot











































 iTG Deeay has just informed me that she will be shoutcasting BoB3 Finals.
iTG Deeay has just informed me that she will be shoutcasting BoB3 Finals.













 This time we kick it with the plumber with an attitude from Florida! See what Mario has to say about Exodus, Luigi and who's the Princess of RtCW!
This time we kick it with the plumber with an attitude from Florida! See what Mario has to say about Exodus, Luigi and who's the Princess of RtCW!








 Haven't had enough? The German Werhmacht marches once again! Join
Haven't had enough? The German Werhmacht marches once again! Join  The Axis Goat invasion of Return to Castle Wolfenstein comes down to an exciting final match-up! Join
The Axis Goat invasion of Return to Castle Wolfenstein comes down to an exciting final match-up! Join  The CAL playoffs continue to heat up tonight on The Team Sportscast Network! Here is what we have planned:
The CAL playoffs continue to heat up tonight on The Team Sportscast Network! Here is what we have planned:  Time for interview #3, and it's with Wonderbread! We strolled into the local supermarket and sat down in the bakery section for a nice chat with this l33tz0r!
Time for interview #3, and it's with Wonderbread! We strolled into the local supermarket and sat down in the bakery section for a nice chat with this l33tz0r! The match you've voted for is going live tonight on The Team Sportscast Network! Here is what we have planned:
The match you've voted for is going live tonight on The Team Sportscast Network! Here is what we have planned: 

 Radio iTG makes it's North American RTCW debut as DeeAy casts
Radio iTG makes it's North American RTCW debut as DeeAy casts 
.jpg) Warwitch, Caemdare and Thunder will be bringing the poison needles and goomba kills tonight as they shoutcast the n00biest match out there as
Warwitch, Caemdare and Thunder will be bringing the poison needles and goomba kills tonight as they shoutcast the n00biest match out there as  The game that began TsN's charge into World War 2 returns once again! Join Caemdare and Herr Warwitch as they Return to Return to Castle Wolfenstein yet again, relaunching the RTCW Division for TsN!
The game that began TsN's charge into World War 2 returns once again! Join Caemdare and Herr Warwitch as they Return to Return to Castle Wolfenstein yet again, relaunching the RTCW Division for TsN! 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}